

barefootstache @barefootstache@qoto.org
- Website
- https://bf5.eu/
- Pixelfed
- https://pixelfed.de/barefootstache
- OSM account
- https://en.osm.town/@barefootstache
Mod
I am a strong proponent of leaving this planet better behind than when I arrived on it. Thus to get the most bang for a lifetime my key focus is #longevity which I attempt to achieve with #nutrition specifically #plantbased.
Longevity is good and all as long as you are not frail and weak. Ideally would be to die young at an old age. Thus I incorporate tactics from #biohacking and #primalfitness. Additionally I am an advocate of #wildcrafting, which is a super set of #herbalism.
Studied many fields of science like maths or statistics, though the constant was always computer science.
Currently working as a fullstack web developer, though prefer to call myself a #SoftwareCrafter.
The goal of my side projects is to practice #GreenDevelopement meaning to create mainly static websites. The way the internet was intended to be.
On the artistic side, to dub all content under the Creative Commons license. Thereby, ideally, only using tools and resources that are #FLOSS #OpenSource. #nobot
Joined Mar 2021
barefootstache
boosted

I have no idea if this will get traction but am putting it out there to the fediverse. Am also curious to see if anyone has had the same idea.
Come October 2025 Microsoft is going to end support for Windows 10. (see https://www.microsoft.com/en-us/windows/end-of-support) There are concerns this is going to result in a sudden influx of eWaste as many computers won't support the upgrade to Windows 11. Whilst there are options to continue using Windows 10 (ranging from "Who cares?" to "Let's pay Microsoft for security updates.") the reality is likely going to result in many of these devices being sent for scrap.
In the meantime there is a growing digital divide where people are unable to afford devices to get them internet access due to a multitude of reasons. This can affect an individual in many areas from not having the tools to use at school to not being able to access online services.
Which got me thinking of a new social enterprise / venture / approach to address both issues.
I suspect the vast majority of devices that are (a) still working and (b) cannot be upgraded to Windows 11 can still run Linux OSs like LinuxMint or ChromeFlex. I've had plenty of personal experience with both and can see the potential especially when it means getting online. My daily driver is now a Linux based device which I am using for my current studies. 😁
So how realistic would be it be to connect the dots and address both issues?
Curious, very curious. Might have to see what social enterprise funding might be available to make this a reality.
Anyone want to join me on the journey?
#eWaste #Linux #repurpose #reuse #recycle #DigitalDivide #Linux4Good
barefootstache
boosted


barefootstache
boosted

Study after study also shows that AI assistants erode the development of critical thinking skills and knowledge *retention*. People, finding information isn't the biggest missing skillset in our population, it's CRITICAL THINKING, so this is fucked up
AI assistants also introduce more errors at a high volume, and harder to spot too
https://www.microsoft.com/en-us/research/uploads/prod/2025/01/lee_2025_ai_critical_thinking_survey.pdf
https://slejournal.springeropen.com/articles/10.1186/s40561-024-00316-7
https://resources.uplevelteam.com/gen-ai-for-coding
https://www.techrepublic.com/article/ai-generated-code-outages/
https://arxiv.org/abs/2211.03622
https://pmc.ncbi.nlm.nih.gov/articles/PMC11128619/

barefootstache
boosted

Recently, Altbot has been targeted by DDoS attacks. While the motive is unclear, it seems tied to a misguided belief that the bot’s alt-text generation is harmful to the environment. Let me set the record straight.
Altbot uses Gemini-1.5-flash, a specifically low-power AI model. Processing a single alt-text request consumes around 0.0005 kWh, meaning that in the 4 months since I created Altbot—and tens of thousands of alt-text entries generated—it has consumed roughly 10 kWh in total. That’s about the same energy as running a single LED light bulb nonstop for 41 days or driving an electric car just 40 miles.
These DDoS attacks, however, have already consumed more electricity and computing power than Altbot has across its entire existence... in a matter of hours. This means the attacks have caused more environmental harm than the very thing they seem to be protesting.
Altbot exists to improve accessibility on Mastodon, not to harm the environment. Accessibility and sustainability can coexist, and I’m committed to keeping Altbot energy-efficient and purposeful.
If there are concerns, I encourage constructive dialogue—not destructive actions that undermine both inclusivity and sustainability.
Thank you to everyone supporting Altbot’s mission of making the Fediverse more accessible for all.
barefootstache
boosted

I wounder when #ALDI stops branding their #Toast as "#AMERICAN" because it's definitely not #USian / #USA - Style, as it's way too healthy and doesn't have #HighFructoseCornSyrup or #YellowNumber5 in it!
Seriously, that branding needs to bet wiped off before consumers start boycotting it Canadian Style...
Mind you #Germany has actual #bread #culture and that #AldiToast is considered "bare minimum slop" and not even proper bread by anyone with taste.
barefootstache
boosted

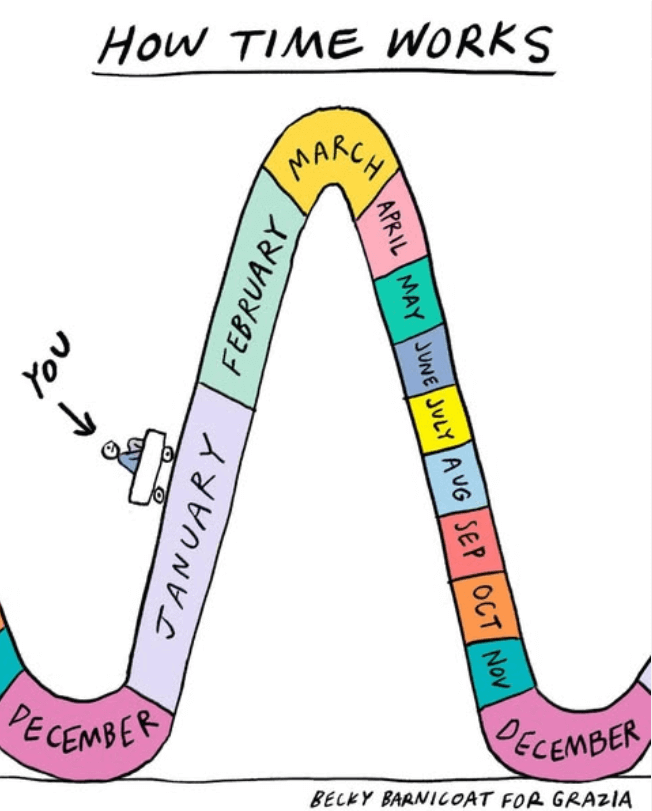
This feels true...
by Instagram user @beckybarnicomics
https://www.instagram.com/p/DFXYUJatjBV
Spent the last 10 hours trying to get any #linux operating system to work on a #dell #inspiron15 with #windows10.
First tried to get #fedora to boot via #yumi, but it black screened.
Next tried to use the same USB stick with #Ubuntu only to realize that it was too small.
Got myself a second stick, but Windows wasn't reading it via "This PC", thus had to format it via Disk Management before using YUMI to install Ubuntu onto it.
And it didn't help that Windows was very sluggish with the existing hardware. Making the whole experience a mental challenge onto one's patience!
barefootstache
boosted

Nice post on:
"Why Blog If Nobody Reads It?" 🤔
https://andysblog.uk/why-blog-if-nobody-reads-it/
Short answer (IMO): Writing helps the thought process and helps future you.
Same reason why I post links on social. In the end I don't care if they get traction - they get sucked into https://davidbisset.social for future me.
barefootstache
boosted

I'm just going to leave Freedom of the Press Foundation's excellent guide to leaking to the press right here in case anyone happens to need it: https://freedom.press/digisec/blog/sharing-sensitive-leaks-press/
barefootstache
boosted

If you are in the U.S., you can buy produce directly from black farmers and they will ship it to you. It can cost less than your supermarket and will piss off people in power.
https://blackfarmersindex.com/
#interesting #youshouldknow #food #economy #business #smallbusiness
The most fun I had was dealing with a a pre-existing reference as in
```
const page = { foo: 0, bar: 0};
const pageList = [];
if (someNumber > 4) {
for (let ii = 0; ii < someNumber; ii++ ) {
page.foo = ii * ii;
page.bar = ii + ii;
pageList.push(page);
}
return;
}
pageList.push(page);
```
When console logging within the for-loop everything worked as expected, but if one saved the `JSON.stringify(pageList)` then each item that was created in the for-loop equated to the last item created.
The solution is to create a `structureClone(page)` within the for-loop and reference it over `page`.
As neat as #jquery or #cheerio is, I miss the abilities of #VanillaJavaScript in the browser.
I don't remember how many times I tried to grab certain properties, which would have been available in the browser, but don't exist in cheerio.
And it is a bit annoying to constantly put various html elements into the cheerio wrapper class to get access to the various functionalities it offers. Thus instead grabbed the minimal viable data and just worked further with arrays.
After spending 7 hours to publish the code while going through a 71 page PDF.
The 71 pages were reduced to 43 pages in the `clean-html.js` step. And in the next step of `create-question.js` it was expanded to 63 pages.
Most of the time I was in the cleaning phase, since this is where one can remove pages and add questions quickly without the need of either copy-pasting the wording directly to #anki or manually typing it out.
One thing that has been holding me back is not having a #LuaSnip in #NeoVim to generate snippets quickly.
Just published the preliminary tool #pdf4anki on #codeberg
https://codeberg.org/barefootstache/pdf4anki
It mainly describes how to do it and is a semi-automation tool to get PDFs into #anki.
In the current version one will still need to modify the pattern constant in the clean-html.js file to align with the PDF in use.
barefootstache
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
The last five days been working on getting lecture slides semi automatically into #anki.
For the first three days battling with #python in extracting the data from a 77 page PDF.
On the fourth day finally got the first complete PDF worth of lecture slides into Anki after 8 hours. Most of the time manual pattern matching and setting up a good enough data structure.
On the fifth day, got the second set of lecture slides which are only 44 pages and were decreased down to 12 pages and took 5 hours. Most of the time was converting the manual pattern matching from the fourth day into an automatic sequence and writing up documentation on how to reproduce.
After spending so much time in trying to semi automate the process, I have been questioning if it would have been faster to do it all manually. Hopefully the upcoming sets of slides will go much faster and plan to release the code in the next couple of days.
After struggling to get #python #PyMuPDF to work and being close the deadline, I shifted to using a combination of other commands.
First using the #linux #pdftohtml command, which is so much faster than PyMuPDF and packages the result similar to saving a website.
Next with #NeoVim and #RegEx format the #HTML file to be able to be quickly processed with #NodeJs #cheerio and eventually through #json to be saved in #sqlite.
Is it elegant and automatic? No, though it works!
#TIL that #SnakeCase is a less frequently used tagging scheme on the #fediverse.
This could be due to that some services break their internal tagging schema, e.g. #Minds doesn't work well with #KebabCase.
Or it could be due to the laziness of the users and subjectively arguing that #snake_case doesn't add to the readability of #PascalCase or #camelCase tags.
In return the argument is that snake_case can add value if the tag has a not obvious word break, especially if the tag is completely written in lowercase or UPPERCASE.
Or if the the underscore replaces a different character other than space like slash, pipe, hyphen, etc.
And in AReallyLongTag / a_really_long_tag it could aid readability.
Thus if one wants grouping and discoverability of posts while creating a brand identity consider using snake_case tags.
- Website
- https://bf5.eu/
- Pixelfed
- https://pixelfed.de/barefootstache
- OSM account
- https://en.osm.town/@barefootstache
Mod
I am a strong proponent of leaving this planet better behind than when I arrived on it. Thus to get the most bang for a lifetime my key focus is #longevity which I attempt to achieve with #nutrition specifically #plantbased.
Longevity is good and all as long as you are not frail and weak. Ideally would be to die young at an old age. Thus I incorporate tactics from #biohacking and #primalfitness. Additionally I am an advocate of #wildcrafting, which is a super set of #herbalism.
Studied many fields of science like maths or statistics, though the constant was always computer science.
Currently working as a fullstack web developer, though prefer to call myself a #SoftwareCrafter.
The goal of my side projects is to practice #GreenDevelopement meaning to create mainly static websites. The way the internet was intended to be.
On the artistic side, to dub all content under the Creative Commons license. Thereby, ideally, only using tools and resources that are #FLOSS #OpenSource. #nobot
Joined Mar 2021
