

Parienve @Parienve@qoto.org
- alt
- Parienve@mas.to
- pronouns/pronomines
- en: they/them/themself
en: Mostly tech, but not entirely. Privacy is a human right.
ia: Principalmente technologia, ma non in toto. Privacitate es un derecto human.
Joined Feb 2020
Parienve
boosted

Does anyone know Arc Search's user agent so we can block it?
alt text
@nixCraft
A screenshot of an exchange between two Reddit users:
[–] **SlowDownBrother** • 9 points
I thought SSL certificates were around $100 a year. Is there a free way?
[–] **isometricpanda** • 41 points
lets encrypt
[–] **SlowDownBrother** • 39 points
Yes, let's. But that doesn't answer my question..
@dosch
Do you have a user-agent switcher? If so, set it back to Firefox temporarily or set it to disable automatically on https://addons.mozilla.org/
@soundasleep @RL_Dane
Parienve
boosted

"Miyazaki absolutely eviscerating an AI art demonstration" is my new standard for measuring how badly my presentation went
alt text
@hungry_joe
First image:
[Top text]
"Nobuo Kawakami, Chairman, DWANGO Co., Ltd.
(Japanese telecommunications and media company)"
[Bottom text]
"This is a presentation of an artificial intelligence model which learned certain movements."
Second through fourth images,
Hayao Miyazaki, with English subtitles:
"I am utterly disgusted."
"I would never wish to incorporate this technology into my work at all."
"I strongly feel that this is an insult to life itself."
Parienve
boosted

@timnitGebru
Perhaps there should be more funding for fully reproducible models like LLM360-Amber and LLM360-Crystal.
Parienve
boosted

Naming my new AI startup DemiUrge™
Parienve
boosted

Parienve
boosted

Reposting this because frankly, it's some of the best writing I've done in a while, and I'm damn proud of it.
There's nothing a user interface designer loathes more than complexity. Every design—at least, every modern design—seeks to minimize clicks, icons, visual noise. What if instead of a button, we had a borderless icon? What if instead of navigation controls, we used gestures?
And what if—hear me out—instead of search results, we had language model-distilled text delivered to you, hot and fresh?
@sachinsaini
BTW, Motorola seems to have a patent on this feature until *2035*: https://patents.google.com/patent/US9715283B2/en
@Linux_in_a_Bit
@sachinsaini
I've had three Motorola phones with LineageOS, and all three times I had chop-chop without sketchy apps.
@Linux_in_a_Bit
Parienve
boosted

OK, poll time, and this one is a simple one (please share so I can get a decent sample). What is your main OS?
@foolishowl
Maybe a combination of hyperbolic discounting, anchoring effect, and gambler's fallacy.
Parienve
boosted

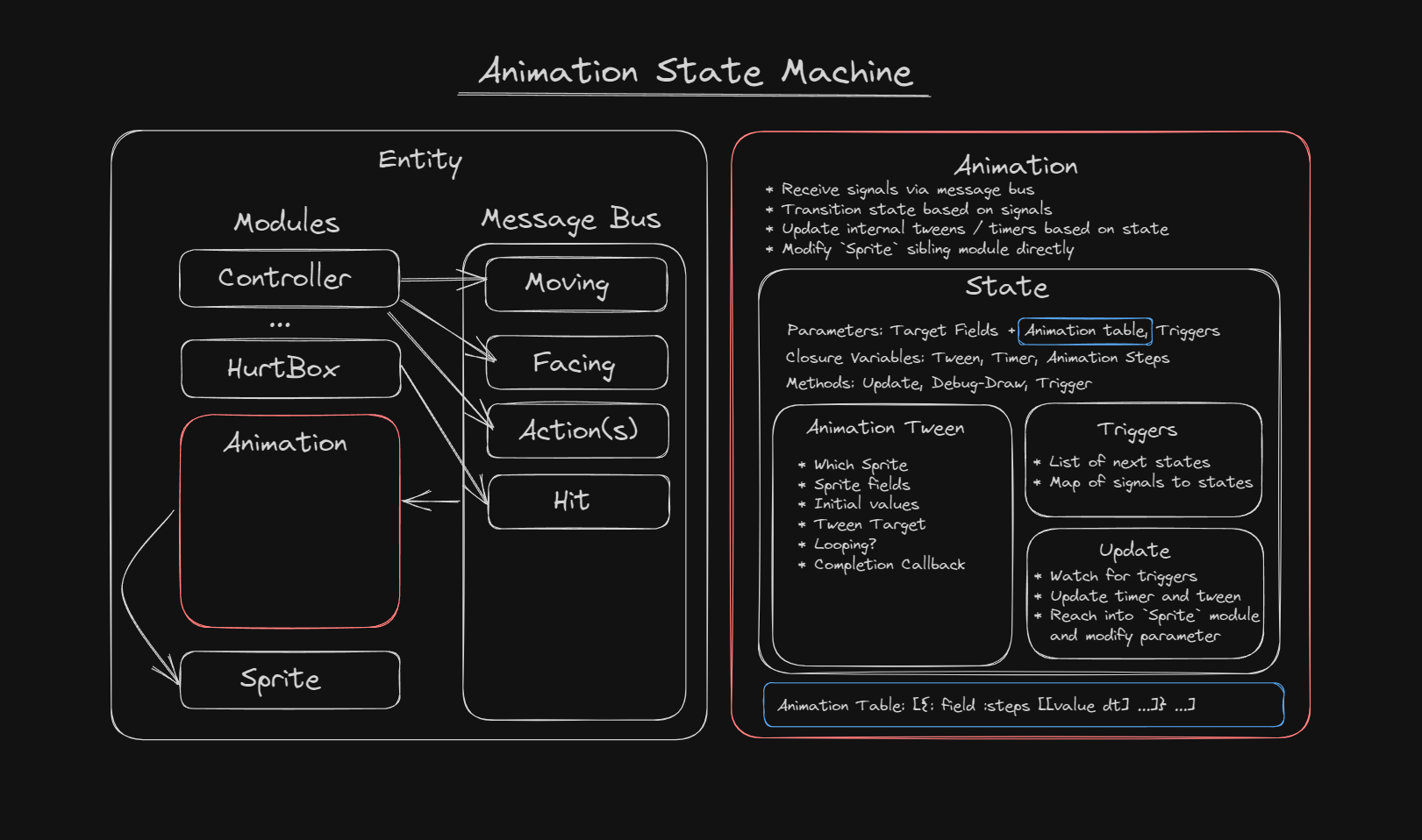
I've been playing around with using a message bus system in #love2d to loosely couple modules.
One of the weaknesses of love is that its built in message passing feature (handlers) require modules to know about each other. This makes it difficult to to reuse components between games.
Parienve
boosted

"Pixelosis"
Since #genuary4 prompt is "pixels" the best way to show them is by serious upscaling of sprites. Here's a #winter Outrun-like #tweetcart
#genuary4 #genuary #pico8 #generative #codeart #sizecoding #pixelart
for i=0,999do
x=rnd(i/40)-i/90c=3if(i>799)x/=9c=1
sset(x+9,i/30,c+i%4)end::_::?"\^1\^cc\^!5f11█░⬇️3⬅️"
for i=2,63do line(0,i+64,127,i+64,(28/i+t())%2+6)end
j=t()*4for k=40,1,-1do
i=k-j%1x=(cos((k+j\1)/9)+.3)*4^6z=i*9+9s=600/z
sspr(0,0,32,40,x/z+64-2*s,64-3*s,4*s,6*s)end
goto _
Parienve
boosted

We really, really don’t want to have to make a printer, but wow.
Parienve
boosted

TikTok is adding a feature that will make every video shopping by using AI to recognize objects and allow you to shop for similar things on TikTok Shop.
This will further the current sense that every TikTok video is now trying to sell you something.
Parienve
boosted

“We obtain three decades of computer vision research papers and downstream patents (more than 20,000 documents) and present a rich qualitative and quantitative analysis. This analysis exposes the nature and extent of the Surveillance AI pipeline, its institutional roots and evolution, and ongoing patterns of obfuscation.” https://arxiv.org/abs/2309.15084
Parienve
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
📢 Calling all creators, publishers, and content contributors on the web! 🌐
Today we are announcing an important open letter which proposes a simple specification to enable fair usage of content for search and AI. This is a threat now, not an #AISafetySummit future one.
Join us by signing & sharing the open letter 👇
{kind=link}
- alt
- Parienve@mas.to
- pronouns/pronomines
- en: they/them/themself
en: Mostly tech, but not entirely. Privacy is a human right.
ia: Principalmente technologia, ma non in toto. Privacitate es un derecto human.
Joined Feb 2020
