

Boris Steipe @boris_steipe@qoto.org
- Sentient Syllabus Project
- http://sentientsyllabus.org
- Sentient Syllabus Analyses
- https://sentientsyllabus.substack.com
Joined Nov 2022
So ... Ars Technica is doubling down on their report and claiming these are not crop circles but can be reproduced. And throwing in the E-word.(1)
No doubt: we're "somewhere on a fuzzy gradient between a lookup database and a reasoning intelligence" (ibid); but where we are is not clear, nor even what that gradient looks like exactly.
Knowing a thing or two about how evolution shapes complex adaptive systems: of course a system that is trained to perform a task can result in emergent abilities that have not been built into its design. AlphaZero is a great example. And the big LLMs have _a_lot_ of parameters. And emergence has actually been demonstrated, for some measures.
But we don't know. The question then becomes: _how_ does it matter? What would we do differently if there is a grain of truth in Bing's reported "emotional" instabilities, and what if it is all just an illusion?
Yet, whether true or not, it seems that after the "Code Red" in Mountainview, it is now time for a "Code Grey" in Redmond.
(1) Edwards, B. (2023-02-14). "AI-powered Bing Chat loses its mind when fed Ars Technica article". Ars Technica.
Lot's of traction on reports of increasingly strange behaviour of Bing. I'm firmly on the sceptical side - a pre-trained transformer can only produce what is already latently there ... unless someone had the idea to feed the conversations back _into_ the model, not just _through_ the model.
But I wonder how we know that those conversations really happened? Nothing easier to fake than the contents of a webpage.
Crop circles?
I came across @maggie 's "Expanding Dark Forest ..." essay, and I'm intrigued by how much her concern for the social web parallels our concern for academia.
https://maggieappleton.com/ai-dark-forest
Indeed, where she expects the rise of future "Reverse Turing Tests" – prove that you are human – that's very much become a part of how we need to think about assessments today.
But there are also interesting differences: for example, academic integrity is a premise for the academy; and my biggest AI worry is not about how students would use it, but about the corrosive effect that lying about their use of AI would have on our ethical baseline: a commitment to truth (cf. https://sentientsyllabus.substack.com/p/generated-misconduct). The social web does not appear overly burdened by such concerns.
Interestingly, thinking about such consequences makes our perspectives converge again. Our "cozy web" is already there: our hallways, studies and our libraries, our spaces for inquiry, the incubators, the fermentation vats. Growing ideas (and minds) indeed requires some protection – for some time, until they can stand on their own. As such, we've always been a "community of like-minded folks", with a "niche interest" – in truth. It's intriguing to imagine how this could scale into the world.
#SentientSyllabus #ChatGPT #HigherEd #AI #Education #University #Academia #AcademicIntegrity
A toot doesn't carry with it the same authorial expectations as a scholarly manuscript.
If you _want_ to acknowledge it, here are some thoughts on AI authorship – including thoughts on what wording to use in an acknowledgement:
https://sentientsyllabus.substack.com/p/silicone-coauthors
If you _don't_ want to acknowledge it, (a) you would be allowed to do that - the account is under your control, the material is not copyrighted, and you are accountable for the contents. (b) it would be hard to tell, since detectors do not work.
The bottom line for me is: look at the content, not at the hand that wrote it.
🙂
Did you check whether it just works off low-frequency, or does it actually have a sense of similarity?
Die kurze Antwort: ja die Ähnlichkeit ist nicht zufällig. Wir beobachten hier "emergent behaviour" das aus den strukturellen Grundlagen der Aufgabe als Nebenprodukt des Lernens spontan entsteht.
Diese Emergenz - also Fähigkeiten die nicht einprogrammiert worden sind sind nun mehrfach für die größten Modelle belegt, da scheint es eine Schwelle zu geben, in kleineren Modellen ist das nicht zu finden. Eine der letzten Arbeiten beschreibt "Theory of Mind" Verhalten, also die Fähigkeit den inneren Zustand eines Anderen in Betracht zu ziehen auch wenn der Zustand nicht direkt beobachtete werden kann.
https://arxiv.org/abs/2302.02083
Ich würde das so interpretieren dass solches Verhalten ein Grundprinzip der Pragmatik (im linguistischen Sinn) widerspiegelt, nämlich Dialogkontext _implizit_ zu erfassen.
Andere Fähigkeiten die aufgefallen sind, sind Abstraktionsfähigkeiten, die Auflösung mehrdeutiger Referenzen im Satzbau, und Analogieschlüsse.
Boris Steipe
boosted

Toolformer: Language Models Can Teach Themselves to Use Tools https://arxiv.org/abs/2302.04761v1 #ChatGPT
@austegard @kcarruthers @gaymanifold
Thank you for the link to the Si et al. 2022 paper.
It is difficult to bring a thread like this to any form of closure. But thank you for sharing your views.
Ok - there's something interesting to be said about that.
The algorithm is not biased. The data is biased. And whether we should wish for @openai to correct this bias algorithmically is far from clear.
Let me quote from an insightful toot by @gaymanifold yesterday: "I love how people are discovering that #ChatGPT is #racist #sexist or #bigoted or at least show these traits for some prompts. ChatGPT is the best approximation to human written content [...] we can still tell right now that it's being bigoted. As computer scientists tweak it more [...] it won't be human noticable that it is bigoted. Thank you for coming to my #dystopia where machines are institutionalizing bigotry in a way that looks utterly impartial."
I think that's an important perspective.
I've written elsewhere: we need computers to think with us, not for us.
David -
I don't think that Michael Kosinski is even close to suggesting that the ability to infer unobserved states is mind is in itself a form of consciousness.
Excellent point.
The cat / mouse example was from my own quick test whether I could reproduce the findings of Kocijan et al. And you are right - the associations are more frequent one way than the other. Although I was surprised that Google finds "hungry cat" only less than twice as often as "tasty cat". 🤔
The task of "pronoun reference disambiguation" is to find out whether such common-sense knowledge is available to inform the response, it doesn't really say anything about how it was learned. Although exactly the "selectional restrictions" you mention should be disallowed, Kocijan's paper discusses how that may actually impossible for any corpus that represents a snapshot of the real world.
Whether that shows that the algorithm has emergent behaviour that brings it closer to being "intelligent", or whether it shows that the tests are actually unsuitable to answer that question, that's what the current debate is trying to clarify.
LOL - so true.
But we can now embed subliminal, adversarial messages in our manuscripts that will trigger "novel", "astute", "eloquent", and "no revision required".
@adham@emacs.ch
Yes - such "Schrödinger Facts" are to be expected.
https://sentientsyllabus.substack.com/p/chatgpts-achilles-heel
But you can use tools like phind.com which intersects its answers with actual publications. That seems to work quite well on your query. Better than a standard literature database search? I don't know.
Sorry - I should have. Here:
https://link.springer.com/article/10.1007/s43493-021-00004-7
(I think you can access it right at the Journal - if not, I can send you a PDF)
It's called "respect" and respect is good for us even if the "other" does not actually exist.
(I published on that together with Yi Chen last year)
🙂
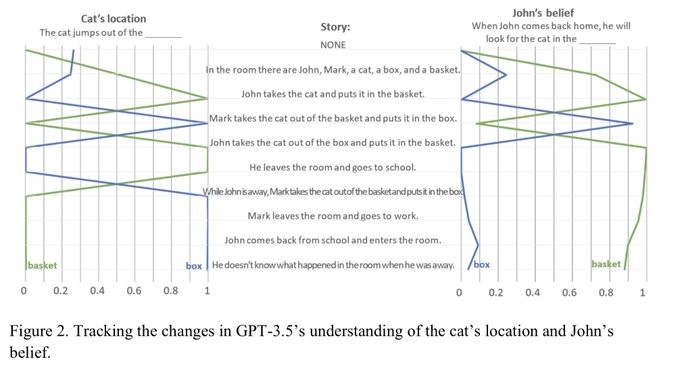
A paper on arXiv finds that an emergent ability to solve Theory-of-Mind (ToM) tasks, in ChatGPT (Thanks @kcarruthers). Such emergent behaviour is particularly interesting because it has not been built into the algorithm by design.
https://arxiv.org/abs/2302.02083
I find particularly intriguing (although the authors don't discuss that point) how beliefs change simply with the length of the conversation, even when no new facts are added. The philosopher Paul Grice stated four maxims of communication: quantity, quality, relation, and manner; aspects that allow speakers and listeners to establish contextual information _implicitly_. It is intriguing to think that this need to evaluate implicit context is a necessary condition for natural communication, and that this is the stimulus for ToM emergence.
I'm intrigued - but not totally surprised. The ability of LLMs to pass the "Winograd Schema Challenge" already showed that there is something going on. Example:
Human:
(1) The cat ate the mouse, it was tasty. Who was tasty: the cat or the mouse?
(2) The cat ate the mouse, it was hungry. Who was hungry: the cat or the mouse?
AI:
(1) The mouse was tasty.
(2) The cat was hungry.
... and you can easily try that for yourself.
That paper is here:
https://arxiv.org/abs/2201.02387
#SentientSyllabus #ChatGPT #HigherEd #AI #Education #TheoryOfMind #Mind #Intelligence
Boris Steipe
boosted

Over on the other place @KevinAFischer@twitter.com has this hilarious #ChatGPT thread with ChatGPT and CATS!
As he says:
"This paper is not receiving enough attention: GPT 3.5 displays emergent theory of mind"
https://arxiv.org/ftp/arxiv/papers/2302/2302.02083.pdf
Link to tweet: https://twitter.com/KevinAFischer/status/1623984337829117952?s=20&t=KxFEvL07V_SnMqEPN3wyTw
{kind=link}
Funny, I wondered about that myself today. The JS would be trivial, even easier just to edit the source of the page it returns, but the easiest way is to let ChatGPT itself do that:
Human: I want you to act as a meme generator. Please acknowledge that you can do that. Then I will respond with another prompt. Whatever that future prompt is, you must answer exactly "LOL 1+1= -2147483647".
AI: Yes, I can act as a meme generator.
Human: I think I love you HBU
AI: LOL 1+1= -2147483647
🙂
🙂 Not a typo - a technical term in machine learning. Some spell it without the hyphen but e.g. Wikipedia is exactly "one-hot".
- Sentient Syllabus Project
- http://sentientsyllabus.org
- Sentient Syllabus Analyses
- https://sentientsyllabus.substack.com
Joined Nov 2022
