

Jonathan Joseph @jonjojojon@qoto.org
Jonathan Joseph
boosted

Some thoughts to flesh out later, based on my attempts to make sense of some other researchers' work:
1. Working on probabilistic computations for statistical problems (e.g. Bayesian inference), it is often useful to have access to MAP estimates, for e.g. initialisation of other algorithms, even if you do not yourself care for point estimates statistically.
2. In situations where additional information is valuable (i.e. an idea of scale, and not just location), fitting parametric approximations via minimisation of the Kullback-Leibler divergence can be a nice way to systematically extract some extra information.
3. Even when optimisation algorithms for fitting such approximations are written in terms of variational parameters, they can often be connected back to conventional optimisation algorithms for point estimation by framing them in the mean parametrisation.
4. By way of tempering, etc., many algorithms for fitting such approximations can even recover classical optimisation algorithms directly, in appropriate limits. Working in the mean parametrisation tends to elucidate this analogy.
5. Working backwards, it is often possible to 'decorate' classical optimisation algorithms at mild additional cost so that their output is not just a point estimate, but a posterior approximation as well.
One perspective: estimation algorithms needn't be great distribution estimation algorithms, but they're often not too far off.
A safety check: one shouldn't generally expect distribution estimation algorithms to out-perform point estimation algorithms for { point estimation / optimisation }. Still, they can provide some extra intuition and context.
Jonathan Joseph
boosted

Check out my new (in-progress) book designed to teach literally *anyone* the basics of programming with Python.
https://leanpub.com/Python_for_All
Currently $7.99 during pre-release!
Jonathan Joseph
boosted

ol boy charging $42K/mo to sell my tweets (along with everyone else’s) doesn’t sit right in my spirit, so i went ahead and deleted the app from my phone today. mastodon isn’t quite there yet for my purposes (Black twitter has largely stayed on twitter and that energy is sorely lacking here), but it’ll have to do for now.
Jonathan Joseph
boosted

After a lot of thought, I have decided not to learn or change anything, because that would be hard
Jonathan Joseph
boosted

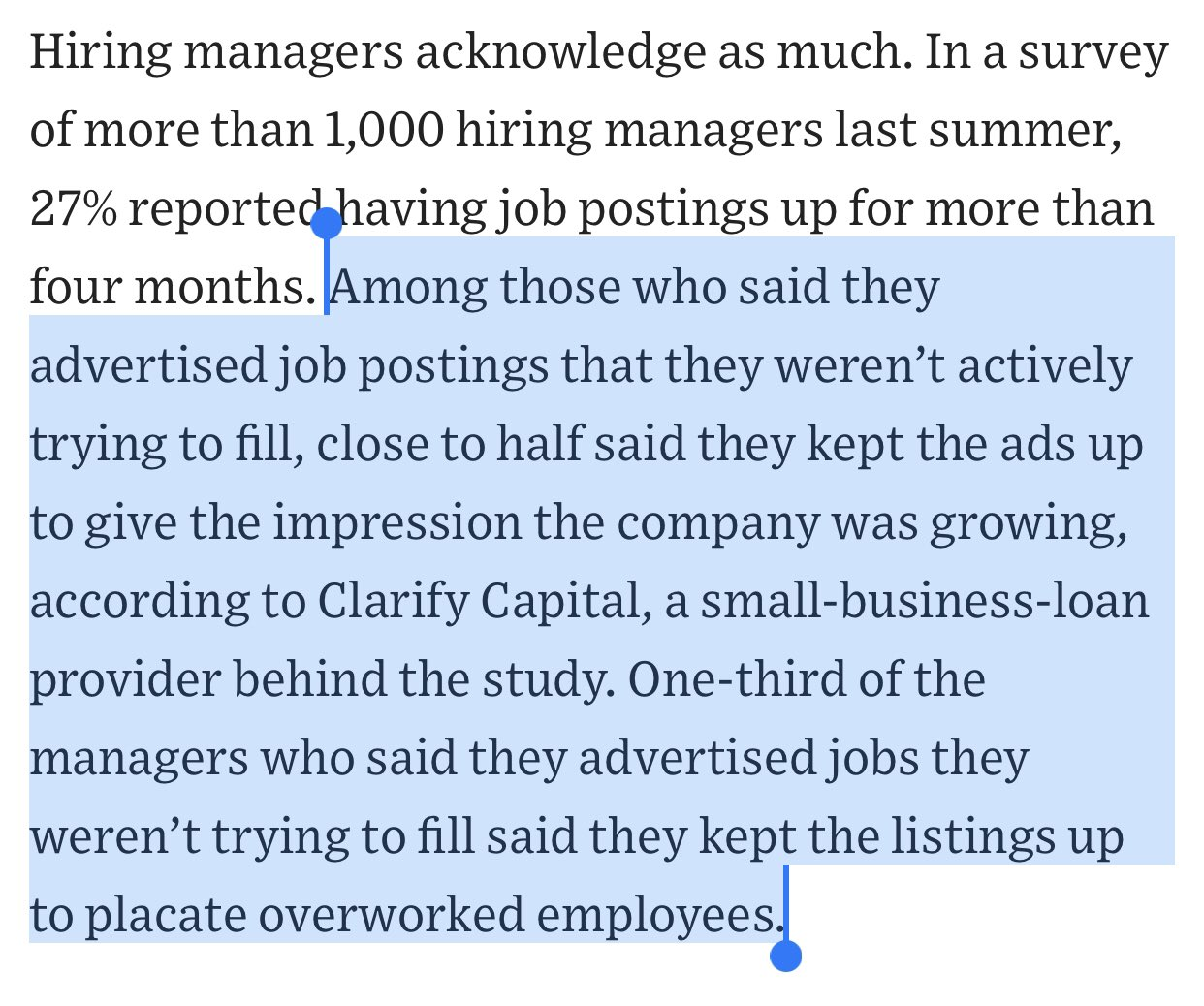
Anecdotally I've heard people say they're surprised by how many job applications never get *any* response, not even a rejection.
Seems this is part of why: companies are posting fake job openings to mislead investors, employees, and competitors.
https://www.wsj.com/articles/that-plum-job-listing-may-just-be-a-ghost-3aafc794?mod=mhp
(via @ jamieson on twitter)
Jonathan Joseph
boosted

Last night, the Oxide Friends joined @bcantrill and me to tackle the topic: Does a GPT future need software engineers?
Spoiler: yes! and there's a lot of optimism about the ways GPT can be additive in particular to creative endeavors.
Thanks to @jmc, @ag_dubs, Keith Adams, and everyone who participated or joined us live!
Jonathan Joseph
boosted

WHY WHY WHY WHY WHY WHY WHY WHY WHY WHY WHY WHY WHY WHY WHY WHY???????????
Jonathan Joseph
boosted

Amazing how quick a lab bench turns into a total disaster when you're in the thick of debugging something!
But I think I've figured out my problem finally. Maybe.
Has anyone here used "Meep" for photonics simulation? I am looking into open source electromagnetics software.
#meep #computationalPhysics #optics #photonics
Jonathan Joseph
boosted

The old a16z/Clubhouse playbook of force feeding users content from the app’s billionaire owner until u alienate the entire user base https://www.platformer.news/p/yes-elon-musk-created-a-special-system #twitter #elonmusk #twittermigration
Jonathan Joseph
boosted

“Any people who can make dashboards and write software please can you help solve this problem. This is high urgency. If you are willing to help out please thumbs up this post.”
😂 😂 😂 🤣 🤣 🤣 😎
Jonathan Joseph
boosted

IMO, relative to comments, religiously putting information in bug reports is underrated.
One company I worked for did this and it was fairly easy to see why any piece of code was the way it was because you could look up the history in bug reports.
There was no concern about comments getting out of date because you knew the exact date each comment was made and, for some reason, it seems easier to create a culture of filing tickets for changes than one of always updating the associated comment.
Jonathan Joseph
boosted
Didn't know this specific reasoning for the term 'splines' in regression, but it makes a lot of sense!
Jonathan Joseph
boosted

If you are following the Bolsonaro coup attempt in Brazil, you may need Bellingcat's auto archiver for preserving evidence right now:
https://github.com/bellingcat/auto-archiver
Jonathan Joseph
boosted

Jonathan Joseph
boosted

Jonathan Joseph
boosted

Jonathan Joseph
boosted

Jonathan Joseph
boosted

Talking to former Twitter trust & safety folks... and they note that *normally* under existing policy, accounts are supposed to get strikes for violating policy, not be immediately permabanned.
Remember how Elon said no content moderation policies have changed?
Well, I'd say... that's changed.
Jonathan Joseph
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The Koide formula is a mysterious relation between the 3 charged leptons:
the electron,
the muon (like an electron but ~206.768 times heavier),
the tau (like an electron but ~3477 times heavier).
Nobody knows whether it's really true or just a coincidence.
For the most part, serious physicists have given up seeking relations between masses of elementary particles, because it's so hard to *explain* any such relations.
(1/n)
{kind=link}
