

Laura J. Wilkinson @ljw@qoto.org
Experienced practitioner of info & library management, research publishing, teaching & learning, and knowledge workflows. Live adventurously!
Joined Aug 2018
Laura J. Wilkinson
boosted

Delighted to see this news is out: @themitpress will be moving two big European Sociological Association journals from paywalled/"hybrid" (at Taylor & Francis) to diamond OA with MIT Press 🎉 🍾 💯
Laura J. Wilkinson
boosted

WE ARE HIRING
* OXFORD COLLEGE FELLOWSHIP *
Job in @OpenSAFELY @BennettOxford @JesusOxford with amazing open science tools that cover the whole population's health data securely.
It's a PERSONAL FELLOWSHIP and you get a COLLEGE affiliation.
You can do epidemiology, security research, work on a key health data policy issue, or more. As long as it fits our work.
So: YOUR brilliant research projects, 3 years, also you get the food, friendships and mediaeval lifestyle
Laura J. Wilkinson
boosted

The Leibniz Strategy Forum on Open Science will discontinue its activities on Twitter/"X" within the next few days until further notice.
👉 Please follow us on Mastodon: https://mastodon.social/@leibnizopenscience
Laura J. Wilkinson
boosted

Fun fact: the MP3 file format is as old today as 8-track tapes were when MP3 was invented.
Laura J. Wilkinson
boosted

Here's how the "Ship of Theseus" page looked in July 2003 when it was first created! Since then, the article has been edited 1792 times and 0% of the original phrases remain.
Laura J. Wilkinson
boosted

Persistent identifiers are the foundations of any good online strategy for cultural and knowledge organisations. Documents, digitised objects, data all need to have a trusted, permanent location so they can be found, shared and used.
Without them, your digital palace will collapse.
This guide from the Dutch Digital Heritage Network is an excellent guide to help organisations decide how they want to implement permanent identifiers.
Laura J. Wilkinson
boosted

Love that the NZ weather forecast has a barbecue rating https://www.metservice.com/maps-radar/bbq?location=wellington
Laura J. Wilkinson
boosted


@RonaldSnijder 👏I hope you both emerged victorious!
@RonaldSnijder Where is this taking place?
Laura J. Wilkinson
boosted

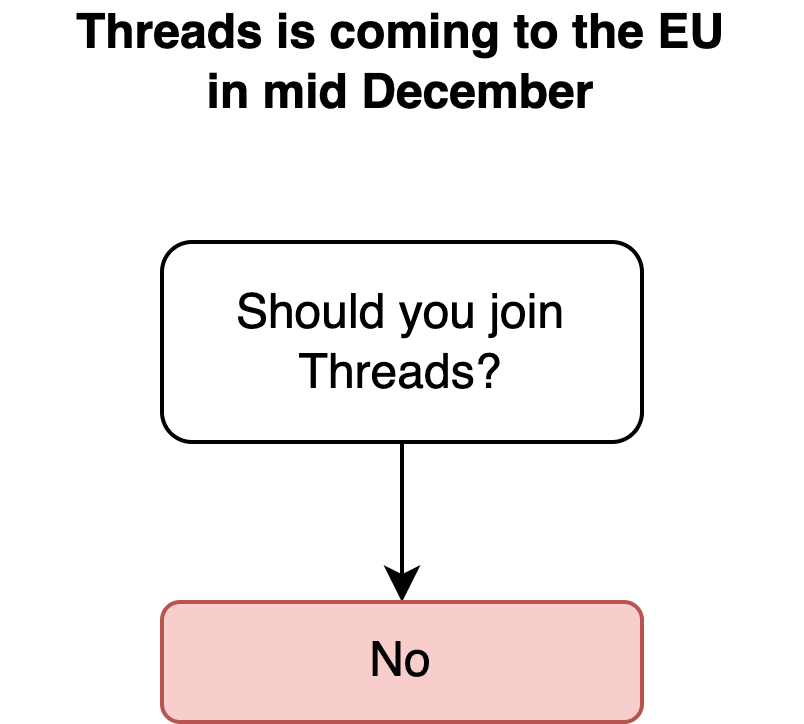
This was important enough to merit a sort of Brexit diagram. Simple though. #Threads
Laura J. Wilkinson
boosted

Very inspiring: Sorbonne University unsubscribes from Web of Science and Clarivate's bibliometric tools, and will support open alternatives instead, in particular @OpenAlex.
‘By resolutely abandoning the use of proprietary bibliometric products, it is opening the way for open, free and participative tools.’
Hope to see more institutes follow this transition from closed to open systems for research information!
https://www.sorbonne-universite.fr/en/news/sorbonne-university-unsubscribes-web-science
Laura J. Wilkinson
boosted

#Crossref (@crossref) has "developed a new, heuristic-based strategy for matching #journal #articles to their #preprints. It achieved the following results on the evaluation dataset: precision 0.99, recall 0.95, F0.5 0.98."
https://www.crossref.org/blog/discovering-relationships-between-preprints-and-journal-articles/
It's sharing the code on Github.
https://gitlab.com/crossref/labs/marple/-/blob/main/strategies_available/preprint_sbmv/strategy.py
Laura J. Wilkinson
boosted

Discovering relationships between preprints and journal articles https://www.crossref.org/blog/discovering-relationships-between-preprints-and-journal-articles/
This is exactly what we need! Journals and preprint servers should link to each other, but unfortunately they fail to do so in a systematic and reliable way.
Great to see that Dominika Tkaczyk at @crossref seems to have a high-quality algorithmic solution!
Laura J. Wilkinson
boosted

#2863 Space Typography
And over heeee[...]eeeere (i)s Saturn.
https://xkcd.com/2863/
30 Useful Principles (Autumn 2023)
Ideas to help you make sense of the world
by Gurwinder
https://gurwinder.substack.com/p/30-useful-principles-autumn-2023?r=62sqt
Laura J. Wilkinson
boosted

I've created this animated chart to visualize the vast spectrum of resource types that you can choose to assign DataCite DOIs to research outputs.
The video shows how strategic partnerships, e.g. with IGSN have a real impact. ![]()
I encourage you to watch and reuse this one-minute clip 🍿 👇 🎬
https://youtu.be/Agt8CzhqsKI?si=6XvGTdRuEj2Zjuon
Please boost if you like this animated chart.
#OpenResearch #50mDOIsIn60seconds
#OpenInfrastructure #OpenScience #PID #DOI #ResourceType

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Experienced practitioner of info & library management, research publishing, teaching & learning, and knowledge workflows. Live adventurously!
Joined Aug 2018
