

獭
boosted

读完了戴锦华和上野千鹤子的对谈文字版。
从听说要有这么一场对谈以来,心路历程是这样的:emmm觉得不会很精彩,pass吧 -> 看review说很精彩呢,要不要信一回呢 -> 有更多说好的了哎 -> (读后) emmm还是应该pass的
总的来说,上野千鹤子更坦诚一些,谈得也更“落在实地上”一些。戴锦华看似说了不少个人体验,但可以感觉到更空泛。不过结合她之前各种完美规避红线的发言,这次她谈资本、谈父权、谈新自由主义、谈男性,但是避而不谈国家,就也不是很意外。
但这种避而不谈是有consequence的。比如她的革命红利说,微博上就已经有人指出,在整体发展和增长的大势中,往往各个群体都多少会获得利益,但问题在于相对而言哪个群体获得了总进步/增长中更大的份额?这个更获利的群体在她的“女性是革命红利的享有者”中隐身了。另一个隐身的是革命后父权制的变形。国家取代了家族内部的年长男性掌握了管理女性的权利,但这依然是一种家长制,只不过父权制的“父”从具体的个体变成了抽象的国家。戴锦华作为女性主义理论的研究者却丝毫不提及这一点我只能认为是她在有意回避。
(关于这个有一篇很精彩的文章值得读《国家的唤问:从晚清到新中国的女性解放叙事》 https://chinadigitaltimes.net/chinese/672176.html )
上野千鹤子提到了家务外包的剥削,但没有进一步深入。家务外包的“新”是阶层维度上的——经济阶层高的压榨经济阶层低的,但同时它又是“传统”的——性别化的劳动依然是性别化的,家务依然是女性的活。并且这种特殊的外包比起非性别化劳动的外包要承担更多污名,比如母职外包、非母乳喂养的道德指责)。在这里可以再次看到second shift的ghost:对女性的压抑从“禁止你做...”变成“你可以做...但你依然要完成...”。另外,这里戴锦华的回应就显得很轻飘了。
关于“恐弱”,我觉得这个提法本身是有一点problematic的,仿佛只有“弱”vs“不弱”、“恐弱”vs“不恐弱”的静态二元区分。借用David Graeber的“革命胜利第二天我们该怎么办?”的角度,无论是有了受害者意识还是害怕承认自己是弱者,之后呢?acknowledge弱者的身份是一个moment,而非一个(passive) state,重要的是这个moment之后的一系列计划和行动。女性要面对的实际困境已经够多了,不需要再多一个害怕进入某个身份或者受害者被动等待正义的枷锁去束手束脚。
獭
boosted

《罗莎在华沙:当卢森堡比列宁更列宁主义的时候》:<https://mp.weixin.qq.com/s/d1fFiGLKuyEjVcffnh-lGw>
以上連結在中國可以訪問(限於嘟文發表之時及之前);下面的則需要非常規手段~
存檔1:<https://archive.ph/a6pfR>
獭
boosted
以下連結在中國可以訪問;限於嘟文發表之時及之前~
《2023国家公务员招考性别歧视研究报告》:<https://maifile.cn/est/d2446766020954/pdf>
檔案下載:<https://gofile.cc/dqDJ/0.pdf>
獭
boosted

鱼鱼 @seviche 推荐的「沉浸式翻译」Chrome 插件/油猴脚本太好使了
无痛(自动启动)、无感(不影响网页浏览)、可以使用各种端口(比如我可以用自己买的 deepl authKey 或者彩云小译的 API
https://github.com/immersive-translate/immersive-translate #m工具
獭
boosted

周世虹委员:建议消除对罪犯子女考公的限制
近日,全国政协委员周世虹表示,一人犯罪受到刑事处罚,就影响其子女、亲属参军、考公、进入重要岗位的规定,应予以彻底摒弃,否则会对受影响人员极不公平。没有任何科学证据证明被告人犯罪,其子女、被扶养人、受其影响的人等就一定会有犯罪倾向、犯罪意图或者犯罪行为。
周世虹指出,罪刑法定、罪责自负是刑法的基本原则,也是现代法治的基本规则之一,犯罪嫌疑人和被告人应该对自己的行为承担责任。建议立即废除有关直系亲属、旁系亲属等有过被刑事处罚等处分而影响考生或被政审人政审的规定;改革政审方式,对考生或被政审人的政治表现以本人现实表现为主,并注重以实证证据予以证明,而不受他人行为的影响或者由有关单位单方认定。
獭
boosted
【转】weibo
很多人说过,中文互联网的可靠的有价值的信息正在极速减少,整个网络正在被垃圾信息充斥。这点外网也差不多,只不过外网规模更大,显得好点。
根本上说,是掌握核心的有价值信息的那帮精英,已经不再在这个互联网上发言了。互联网出现初期,很多掌握核心信息的精英会乐于上网分享,那个时候上网确实能学到不少东西。
以前我提过一个事,那就是人类社会自从有了阶级以后,精英层跟普通人在道德上就是不平等的。精英层为被统治者制订了行为规范、道德标准,但是作为统治阶层本身,他们不受这些道德约束,他们因此占有了更多的资源,享受了更大的自由,也创造了更精致的文化。
但这要建立在一个信息隔离机制上。上下层社会的信息交流是被严格管控的,上层统治者不希望下层知道的事,下层死到临头都不会知道是为什么。
互联网的出现短暂的打破了这种信息隔离机制,普通人得以窥见了上层统治者的世界。但是到了现在,精英层已经发现了问题,他们认识到在网络上暴露信息的危险性,意识到信息隔离机制的打破,最终一定会威胁到他们的社会地位。普通人会用精英层用来约束普通人的那套道德规范,去评判精英层,争取王子犯法与庶民同罪。
以前因为机缘巧合,跟那种影响政策制定的精英层的人接触过,他们现在非常小心,在网上根本搜不到关于他们的任何信息,按他们的说法就是,只要管住嘴不要乱说话,那就要什么有什么。最怕的就是把自己暴露在公共信息中,成为那个在黑暗森林里举起火把的傻子。
这几年阴沟里翻船的很多人,都是祸从口出。
獭
boosted

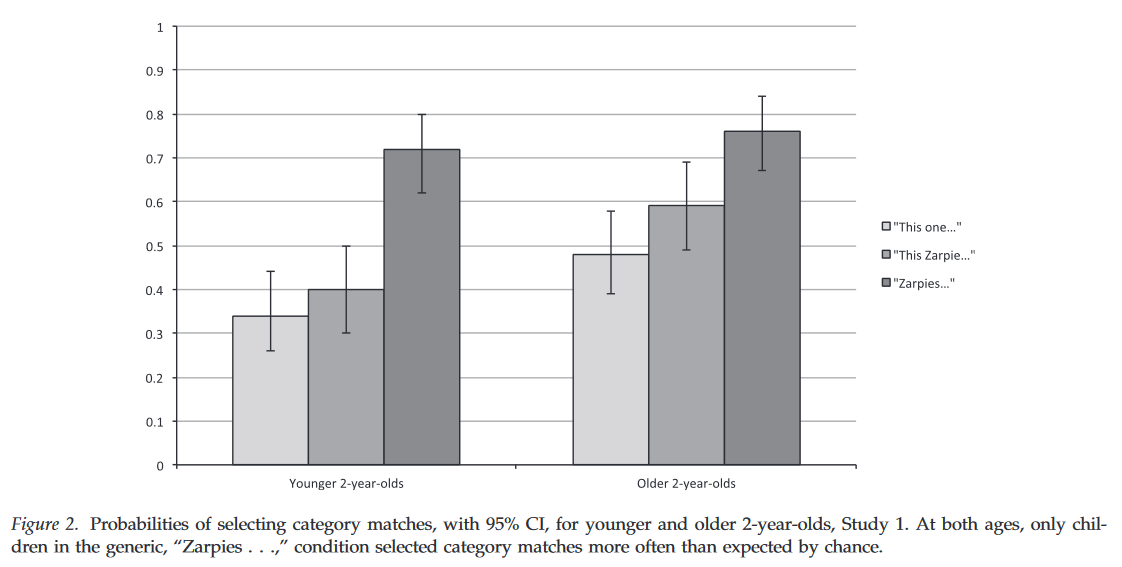
为什么女性很少选择计算机专业和理工科?
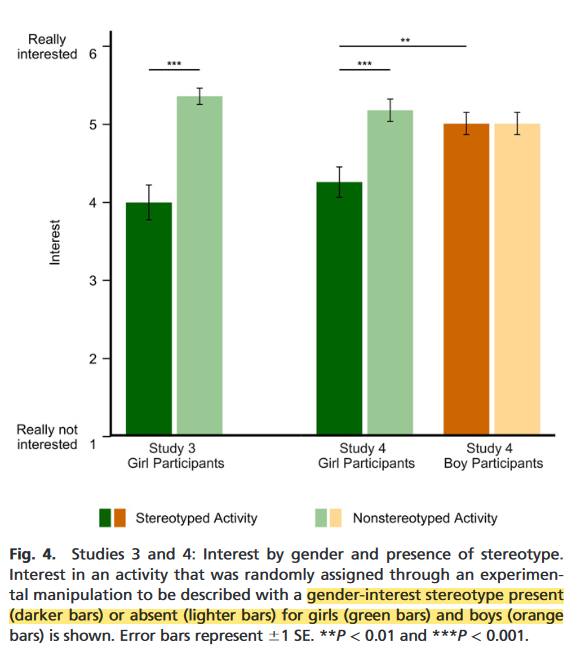
前几天看了一篇研究,关于理工科和计算机领域针对女生的性别刻板印象。发现这种偏见在小朋友六岁的时候就已经根深蒂固了。也就是一上小学这种偏见立刻呈现出来了,导致女生丧失了对STEM学科的兴趣。这个研究是在美国做的,发现偏见是跨种族存在的。
这个研究还有一组实验室实验:一旦一个活动被打上了性别标签(“这个活动女孩子不感兴趣”),会显著降低女孩子参与度。实验中的活动并不是真实世界已有的学科(比如计算机),只用了“activity”这个词指代。也就是说唯一的变量就是这个性别标签。
然后想到前阵子看到的另一篇论文,研究婴儿的social categorization的形成,也就是婴儿是通过怎样的认知机制给人和事物分门别类的。social categorization是形成stereotype的基础。这个研究针对generic language对categorization的强大影响力。generic language指的是这种表述:“女孩子怎样怎样”、“男孩子怎样怎样”,而不是“这个女孩...”或者“一个女孩...”
然后研究发现两岁的小婴儿在听到generica language的会形成social categorization。在听到非generic language的时候不会形成这种分类。
结合这两个研究,就能发现我们每天都暴露在怎样的语言毒气室里。而这些如空气一般弥漫的语言又是怎样潜移默化塑造我们的社会。
獭
boosted

一篇并非学术讨论、但涵盖到了几乎性交易议题的方方面面的文章。作者的诸多观点都极具启发性。
从一个不尽兴的春梦说起 | 白左右狗恋爱真难
https://yichun-lu.blogspot.com/2019/03/blog-post_44.html
獭
boosted

不接受反駁,寫下以下預言,十年後看:
1: 通用人工智能將會被免費使用,和目前搜索引擎被免費使用一樣。
2: APP 和 web 不再是人機交互主要方式,新的更加適合 AI 的交互模式將會出現,以後拖一張照片進來,和AI說,幫我產生一個介面,我要調整這張圖的爆光,和色彩,期待什麼什麼風格的濾鏡,AI會立刻動態編寫代碼,根據你的喜好產生一個即時介面來供你使用。
3: 人機交互包括程序編寫的指令將會更加抽象和模糊化,面向對象將會徹底轉變成面向AI的開發模式,不是讓AI幫忙寫代碼,而是讓AI直接產生解決方案,代碼將直接在模擬智能環境下被優化和執行,而不是編譯好交給操作系統執行,人類開始放棄對代碼最終裁判權。
4: 計算成果在web產生以來,已經逐漸從讓用戶持有文件變為讓用戶持有數據,將來,會進一步進化為讓用戶持有知識,文件和數據的概念會被你持有的知識這一概念所替代。
5: 數據交換將會出現巨大的變化,會出現AI間的知識/參數交互的方式,區別於目前的數據交換的方式,兩個AI間的知識交換將會十分高效,並且徹底非結構化。對特殊需求的遷移學習將會很快,並且可能在用戶不知情的情況下完成。
獭
boosted

激素不是不能用,相反它是过敏发作的时候最应急起效最快的,短期内符合剂量使用高效又安全,但是去医院的时候一般医生都会说清楚一旦症状缓解就不要用了,长期用容易产生依赖或者耐药(慢慢发现不如一开始管用了/停药就发作用了就好),而且每天使用次数也有限制不能图舒服擅自增加剂量……这些是自己去淘宝买otc很难注意到的,对这些风险只字不提就在公轴安利含有类固醇激素的鼻喷雾,说在淘宝能买到,我觉得是很不负责的。
獭
boosted

3月的稿件,作者@kindlemeow@pullopen.xyz
两年前的今天,成都的滴滴司机罢工了。
整整两年过去了,一场不重要也不算成功的「罢工」,就这样无声消失在车流里。城市里的人们不曾发觉,甚至本地司机们自己也很少会再记起这个小小插曲。
两年来,司机和平台之间的关系似乎有所缓和,关于抽成的“黑箱”也不再绝对隐秘。滴滴在当年“停运抗议”的两个月后,就回应了高额抽成的指责,承诺要推动收费透明,保障司机群体的收入稳定。
这么一篇彻底失去时效性的稿子是否有发出来的意义?然而我们深信,记录和发生一样,本身就是一种力量。网约车平台抽成的计价公开,以及新就业形态劳动者权益的保障体系不断深化,并非这场不成气候的“停运抗议”所导向,然而从多年前的混乱与积怨到如今的规则透明化,它补全了“正发生”的过程,还原了“被略去”的声音,构成了宏观发展中的微观图景。
它或许改变了一些事,又或许从未真正改变过什么。就像无数不被注意的反抗和普通生活的微弱呐喊,消失在风里,但总有人听到遗落的音节,或许人们正是在这些隐匿的痕迹里走上了通往未来的——路。或许呢。
獭
boosted

據中國“學信網”消息,3月1日起,臺灣高中畢業生可憑當年學測成績,免試申請包括清華、北大在內的大陸26個省市的400餘所高校。 免試申請!! 臺灣高中生會有興趣嗎? 那些寒窗苦讀,拼命內卷也高攀不上名校門檻的大陸學子又情何以堪? https://nitter.hongkongers.net/RFA_Chinese/status/1631090695686483968#m
獭
boosted

獭
boosted

盗版电影这个事情是真的越研究越有意思,对于非常西方中心的电影理论来说,他们想象的audience群体是一个很hemogenous的、单一性质的群体,而且一般都想象是在一个theatre的setting里出现,而且对于从电影发行方到电影院到看电影的观众这些关系的理解都很单向而且lack of complexities。例如盗版在中国(?什么是中国)语境下就能生发出好多问题,比如盗版商在这里的角色是什么(他们好多人能对国外艺术电影导演倒背如流、他们承担着压制电影/加字幕/是否加导演剪辑版/是否加未删减版等等的一系列决定的责任,而且他们也决定了怎么shape中国的影迷对于‘canon’或者经典的理解),然后淘碟的观众跑到sketchy的盗版碟小店里购买的体验、在私人场域里播放的体验又和一个去影院的观众的经验有什么不同而且怎么影响他们去理解电影,等等等等。什么是合法的,什么是不合法的,好莱坞的电影会在这种电影传播途径里take on what new meaning,European art film又是怎样,还有比如盗版国内导演的删减版/未删减版又会带来什么新的insights。太有趣了我就喜欢这种在不合法的边缘试探的东西 ![]()
顺便,找到一个纪录片拍一个卖盗版碟的小贩的(还没看过所以我不知道拍的咋样):
https://www.bilibili.com/video/BV1Ks411g7wC/?vd_source=e356f04eefba44a3945ba802b0042f32
獭
boosted

蠻好奇象友們常常想解決的隱私問題長什麼樣子?
或是在考慮隱私替代品時遇到什麼困境?
主要想說,一直以來在查相關資料時,總覺得中文資料常常在更新速度或是想法上都沒有很對症。而鵝剛好一直有在搜尋相關資料,如果剛好問題有交疊的話,可以寫篇簡單的來分享。
Ex VPN 只是信任轉移,並不代表用了就有隱私 & 任何隱私建議都要參考面對的威脅模型分析。
問個問個~
獭
boosted

@board 向大家推荐一个相对来说非常简便的搭建个人博客/播客的方法!我试用过多种博客,感觉这个非常适合只需要简洁功能的人,利用cloudflare的免费空间,上传图片视频不压缩无大小限制,目前在中国不用翻墙速度也不错。
技术小白也完全可以自建!识字就行!我用它搭的blog写了一篇我用过的博客平台比较,https://daoluan.pages.dev/i/hello-microfeed-SmsivGhDZZe/
以及介绍大致安装流程:https://daoluan.pages.dev/i/microfeed-installation-123-AA4VTy9fXef/
从嘟友处看到对这个microfeed的介绍:https://mastodon.0ne.day/@su/109888663790092321
试用一周,感觉不错,推荐大家都了解一下!
#长毛象安利大会
獭
boosted

以下两个是程序员专用的搜索引擎+AI聊天服务:
- http://phind.com - 感觉比较聪明,主要功能在AI聊天上,输出的内容准确全面,可以选择简洁详细模式
- http://you.com - 以前主打程序员搜索引擎,最近新增了 AI 功能,不如前者智能,偶尔无法避免像 #ChatGPT 一样一本正经地胡说八道 @board
獭
boosted

国外的手机实体卡,可以用来注册墙外服务:
1. PayGo 卡,月租3刀
2. 英国 Giff卡,0月租,每6个月发一次短信保号
3. 新西兰 Skinny 卡,0月租,每年25RMB保号
4. 新西兰 Vodafone 卡,充值20刀保一年
5. 马来西亚卡,无月租,充值5马币(约1RMB),延长55天。
6、Warehouse 忘记五刀起还是一刀起,沒有固定费用,可以一直用。
7、英国的3uk。
8、菲律宾 globeone 10块一年。
9、日本 povo 每6个月买个最低套餐(几块人民币)保号
欢迎各位补充!

獭
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
尝试了 GoodLinks、Raindrop,以及向 ReadWise Reader 导入 csv。
Diigo 免费版仅有 500 条书签,UI 也没有 Raindrop 时髦,就直接使用不限书签数量的 Raindrop 了。
通过 Raindrop 整合了主要浏览器书签,也导入了额外 1000 列制作好的 csv 成功了。接下来要观察网页保存得如何。Raindrop 免费版已很强大了,支持 Highlight,不过全文搜索为付费功能。
Goodlinks 是仅有 iOS、macOS 端的 Universal App,价格为一次性付费 30 元。好处是 iCloud 同步,无需创建账户。最近更新支持了全文搜索。功能要简单很多,不支持批量添加 tag,不支持文件夹,没有批注这类功能,甚至没有(不需要)帮助文档。不过 Goodlinks 支持复制网页为 MarkDown 格式,效果挺不错的,可以配合笔记软件对文章进行简易存档(图片仍是引用)。
我是在 Raindrop 中处理好 bookmarks 和 tags,再导入 Goodlinks 中。不过对于 ReadWise Reader,怎么处理 csv 都是导入不成功。那就把它作为 high signal and low noise 的去处好了。
Joined Nov 2022
