

Alex Weber @weberam2@qoto.org
Assistant Professor at UBC; MRI, Medical Imaging, Neuroscience; Books and Mountains
https://github.com/WeberLab
weberlab.github.io
Joined Nov 2022
Alex Weber
boosted

I'm one of the (probably many) researchers who uses #sciHub instead of my university's access portals. Not in small part because it's faster and easier. Gatekeeping knowledge (or anything really) increases barriers to access for everyone, even people "granted" access by organizations and systems that rely on enclosure to maintain their profits or class position

Alex Weber
boosted

Is Sci-Hub just a handy tool for accessing papers? Sure. But there’s more to it. @leonido and I argue that this illegal yet legitimate service played a crucial role in the broader #OpenAccess transformation: https://journals.sagepub.com/doi/10.1177/01914537231203558 (English translation of a paper previously published in German)
Alex Weber
boosted

@albertcardona @adredish @NicoleCRust @jpeelle @ct_bergstrom So far I have not heard a reason why a merit-triaged lottery system is bad for science funding.
There have been a lot of good points about barriers to making it happen (big change in general psychology of the US funding, loss of agency for funding officials, other I might have missed).
I’ll stop commenting here and just listen to what others have to say but it’s an honest question that stands: What is bad about a merit-triaged lottery system for funding science (public entities)?
Alex Weber
boosted

In case you missed it, you can make your entire posts searchable without using hashtags *IF* you opt into the new full text search system. Here's how to do that:
➡️ https://fedi.tips/how-do-i-opt-into-or-out-of-full-text-search-on-mastodon/
However, it's still worth using hashtags because:
-Many people follow hashtags, using relevant tags in a post reaches them
-Many people aren't opting into full text search, so you can still find their posts with hashtag searches
-Hashtags are useful for indicating the topics you actively want to discuss
Alex Weber
boosted

here’s the table of contents for the Pocket Guide to Debugging again since a bunch of people have mentioned that they find the table of contents to be really useful on its own
Alex Weber
boosted

I'm happy to announce the start of a new free and open online course on neuroscience for people with a machine learning or similar background, co-developed by @marcusghosh. YouTube videos and Jupyter-based exercises will be released weekly. There is a Discord for discussions.
For more details about the structure of the course, and to watch the first video "Why neuroscience?" go straight to the course website:
Currently available are videos for "week 0" and exercises for "week 1", but more coming soon.
Why did I create this course? Well, I think both neuroscience and ML can be enriched by knowing about each other and my feeling is that a general purpose intro to neuro or comp-neuro isn't the right way to inspire people in ML to be interested in neuro.
I hear a lot about neuroscience inspiring AI, but I think there's understandable scepticism about that from ML people. I don't want people to take neuro ideas and apply directly to ML, I just think we get a richer picture of what both fields are doing if we think more widely.
In other words, we should be thinking that we are somehow studying the same problem in different ways. You see that in the early history of the field, and it's very inspiring. (Yes, this is pretty much just saying that cognitive science is cool, but my scope is a bit narrower.)
The focus then is not on how neuroscientists think the brain works, but on the mechanisms the brain uses. These are strange, inspiring, and often their contribution to intelligent behaviour is still deeply mysterious.
The first video of the main part, on the structure of neurons, finishes with recent research (from @ilennaj and @kordinglab among others) on what the function of dendritic structure might be. No answers, just ideas.
And that's going to be another key part of this course. Research level problems are not hard to find in neuroscience, and the aim of this course is to empower students with the tools to start finding and working on them straight away.
Most of the exercises in the course won't have correct answers. They're starting points for further investigation. We'll be downloading and exploring open neuroscience datasets using methods from computational neuroscience and ML.
The course is not supposed to be comprehensive. It's a short course and the aim is more to get inspired and start on a longer road. I'd expect everyone to get something different out of it, and I'm happy if for some people their take home is "neuroscience is not for me"!
In some ways, it's the course I would have liked to get me into neuroscience and for my incoming PhD students from non-neuro backgrounds to be able to take. It's personal, and full of the sort of stuff that inspires me to be interested in neuroscience.
Well, I hope that some of you might be interested to follow along in the next few weeks, and since it's the first time I'm giving this course please do give feedback by email, Discord or however you like. Also, please feel free to re-use materials however you like.
Alex Weber
boosted

@kinleyid
@elduvelle
Probably dating myself, does python have a good multilevel modeling tool like lme4?
Just finished my presentation on Metascience and how the incentives structures we have in place for researchers/scientists leads to bad science
You can check it out here:
https://github.com/WeberLab/MetascienceTalk
Alex Weber
boosted
Since #SciHub isn't updating during its lawsuit, those of us with access to paywalled research should view it as an obligation to make that research available to everyone. Can we reboot the #ICanHazPDF hashtag? How about we follow it and the @icanhazpdf group.
Alex Weber
boosted

Another #rstats post - what are your favourite examples when teaching students to think critically about data/figures and interpretations?
For example, Simpson's Paradox and the importance of considering important subpopulations - is brilliantly displayed in the Palmer Penguins dataset.
I'm giving a talk next week about the replication crisis in science and how the incentives given to scientists actually work against doing good science. I would appreciate ANY resources / links / ideas people may have on the subject
Ioannidis, but also Kuhn, Feyerabend, etc
Alex Weber
boosted

Who is against #openscience ?
"To be sure, open science is an idea whose time has come. And yet multiple attempts to derail or weaken the White House guidelines, published in what’s known as the Nelson memo, suggest an organized effort opposed to public access to scientific research.
So, who’s trying to blunt a policy with clear societal benefit? Who is afraid of the Nelson memo?"
https://www.insidehighered.com/opinion/views/2023/10/04/call-open-debate-open-science-opinion
Alex Weber
boosted

However, I would encourage nonprofits, news orgs and governments to actually delete their accounts on X.
Institutions are conservative and will be the last to go. But it's that institutional conservatism that gives the platform power.
We're entering an election year in the US, and Musk will do everything he can to make the world a darker place.
Withdraw that power from him. Your exit from his platform is _your_ power. You are not "staying and fighting", you are fueling his engine.
Alex Weber
boosted

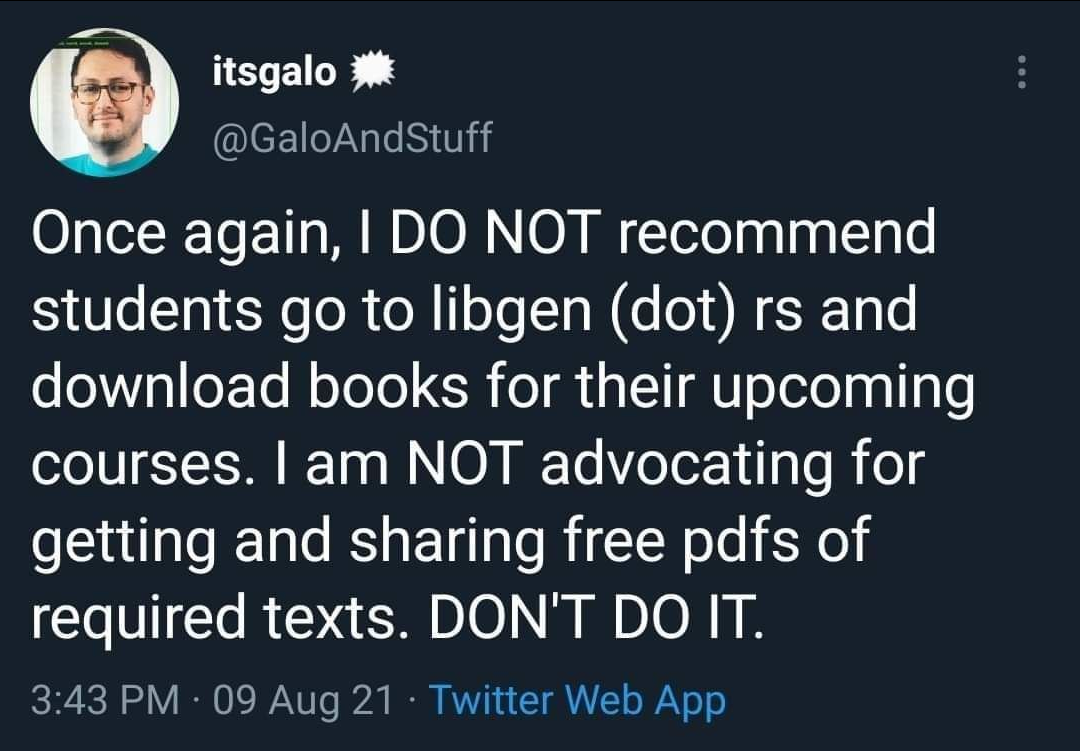
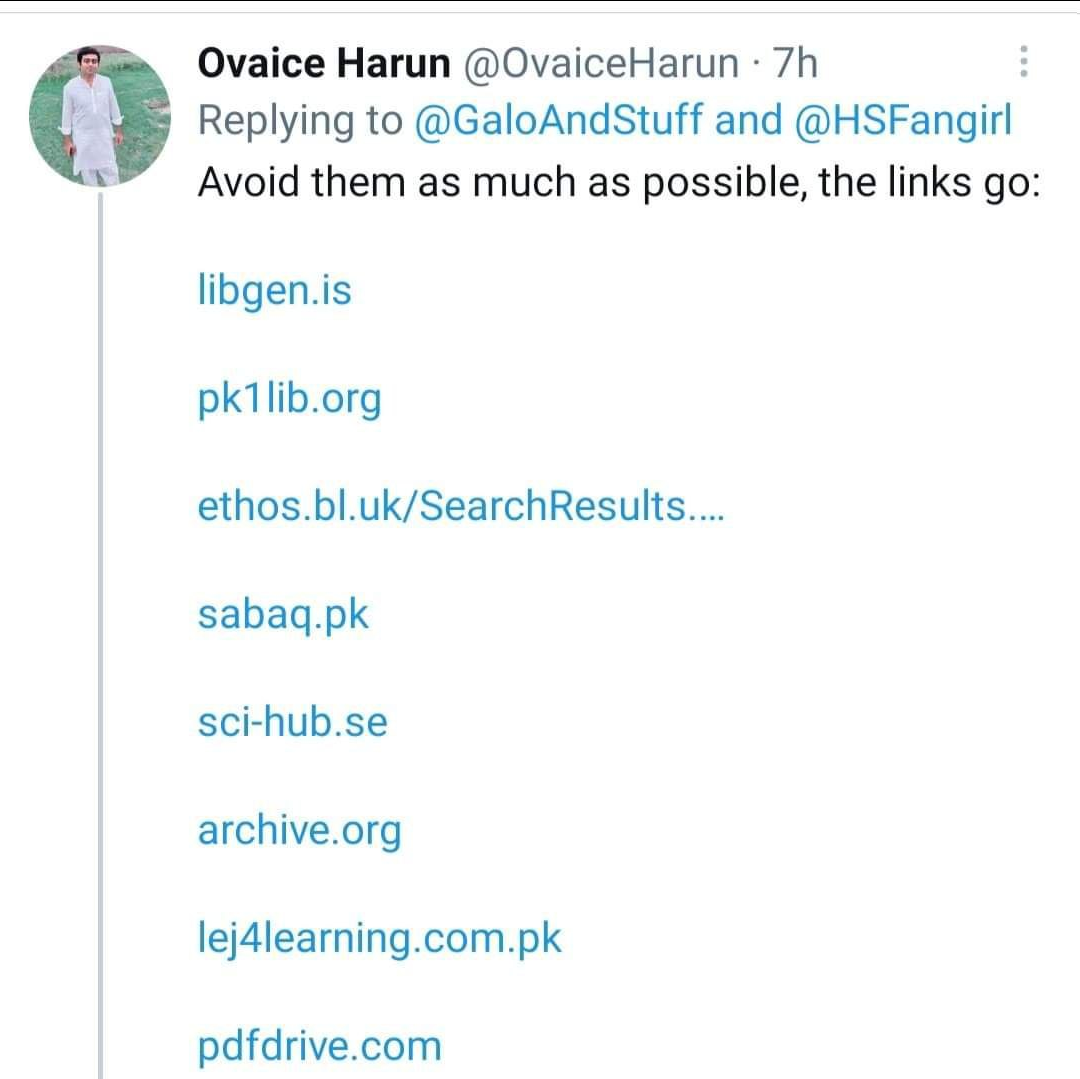
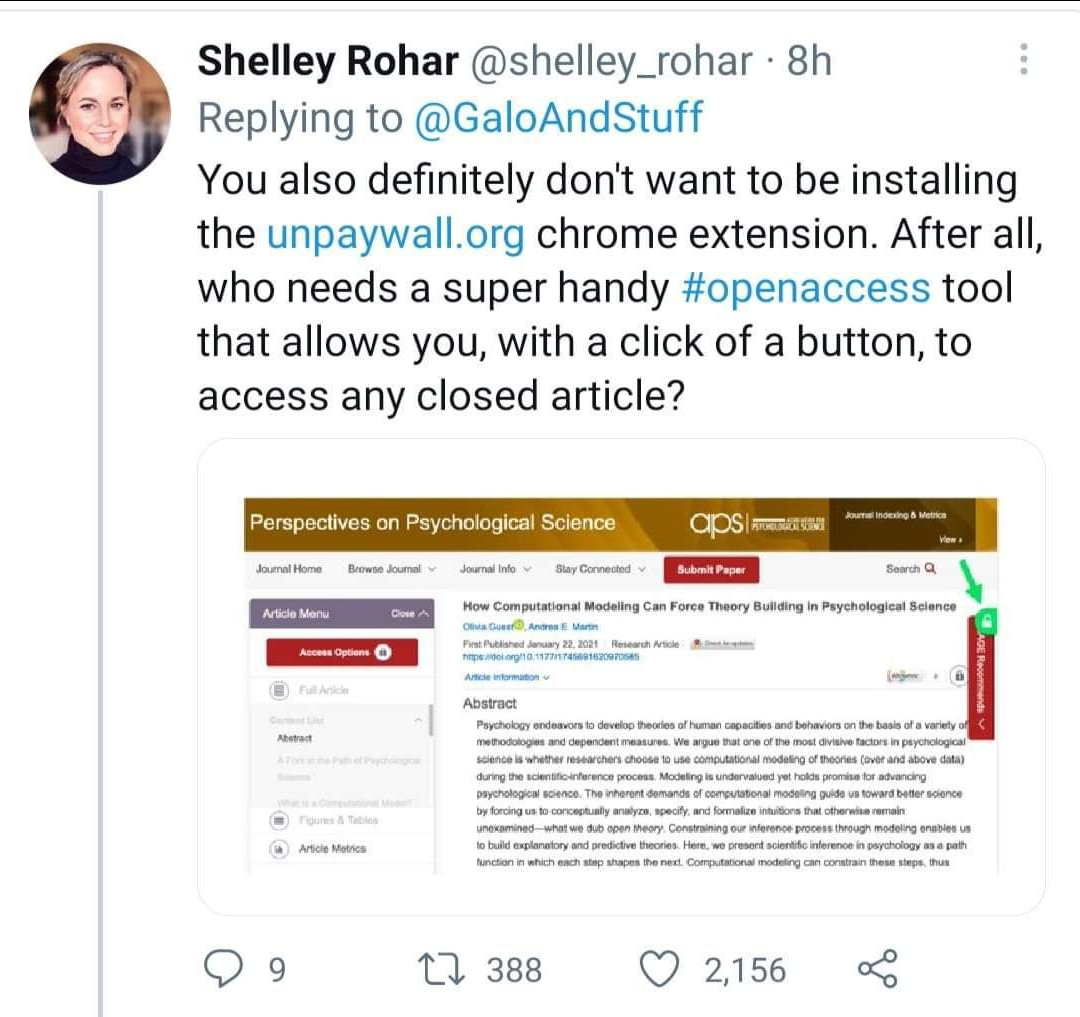
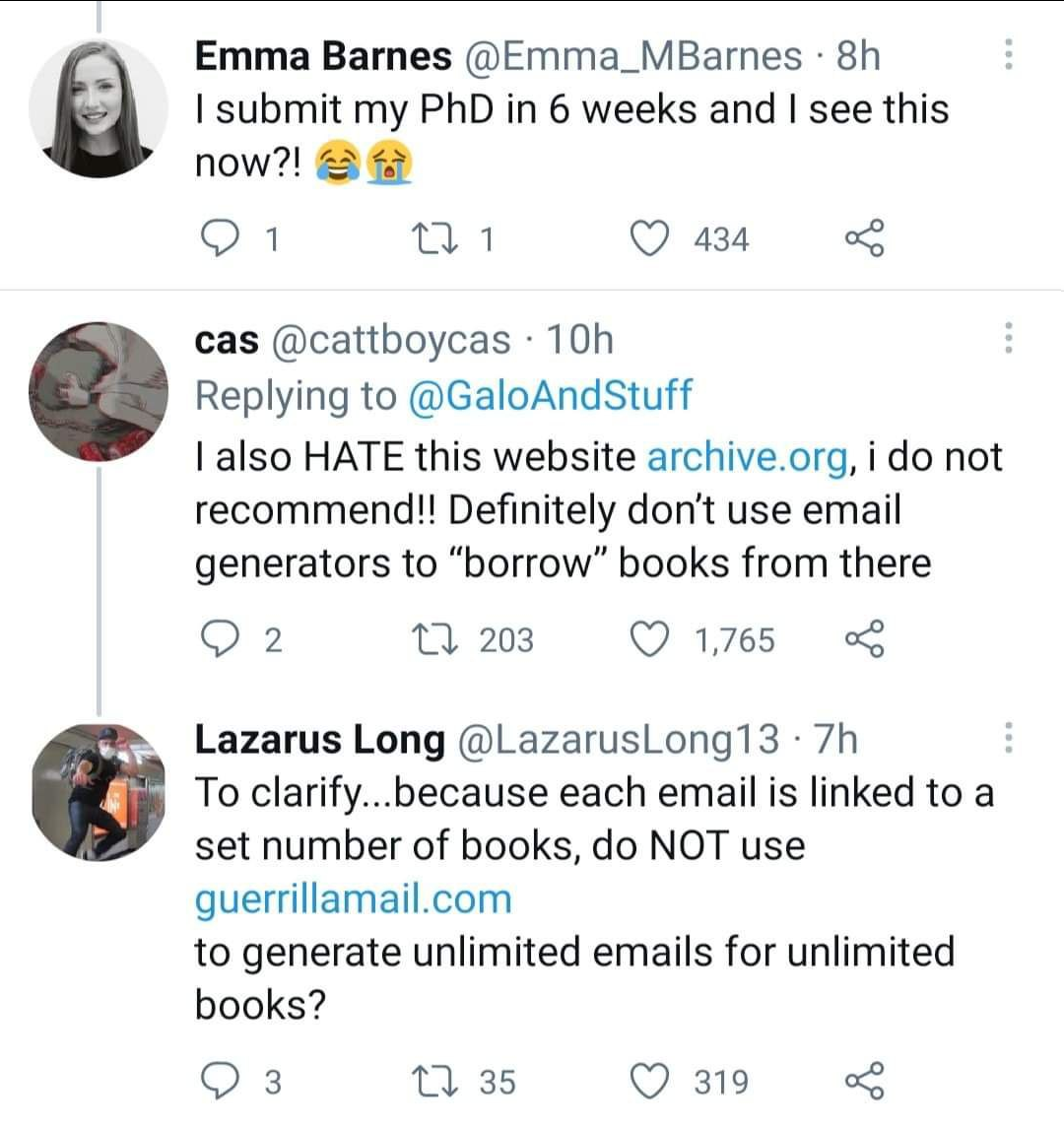
Definitely do not go to these websites to get free study books. Also, don't go to https://12ft.io/ to unlock paywalls.
libgen.is, pk1lib.org, ethos.bl.uk, sabaq.pk, sci-hub.se, archive.org, lej4learning.com.pk, pdfdrive.com, unpaywall.org
Alex Weber
boosted

Maybe we should change our priorities from maximizing the metrics of prestige to maximizing community and personal well-being.
Just a thought.
From: @tdverstynen
https://neuromatch.social/@tdverstynen/111165543953208302
Alex Weber
boosted
This week I read about a Nobel winner whose groundbreaking work didn't get funded and got her demoted, and about data fraud by two of the highest profile scientists who were lauded and mega funded. We have to stop rewarding short term flashy work and overproductive scientists.
It's fine and correct to talk about both incentives and individual responsibility. But if we scientists collectively decided to heavily downplay work without open, raw data and reproducible methods, and ignored journal title when evaluating scientists, this couldn't happen.
The system is absolutely broken and needs structural reform, yes. Journals need to go. Competitive grants are the wrong way to fund science. Scientific prizes are very problematic. But we also need to get better at reading and doing science and valuing what works in the long term.
That's the key point. If we let these things happen it means we are doing science badly.
Alex Weber
boosted

Dear journalists: By remaining on the deadbird site you are actively supporting a business whose owner in in league with people who want to end our democracy. He's further eviscerated what was left of the team that was trying to keep election information honest (for typically inane Muskish reasons).
Please admit, at least to yourselves, that you're not merely using a handy platform. You are collaborating with him. https://www.techdirt.com/2023/09/28/elon-fires-half-of-extwitters-election-integrity-team-because-a-manager-liked-a-tweet-calling-him-a-fucking-dipshit/
Alex Weber
boosted

The embarrassment:
"four editors-in-chief of medical journals told one of us that they also did not publish replication studies. They all said they were concerned that publishing replication papers would negatively affect their impact factors."
https://goodscience.substack.com/p/journals-that-ban-replications-are
Alex Weber
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
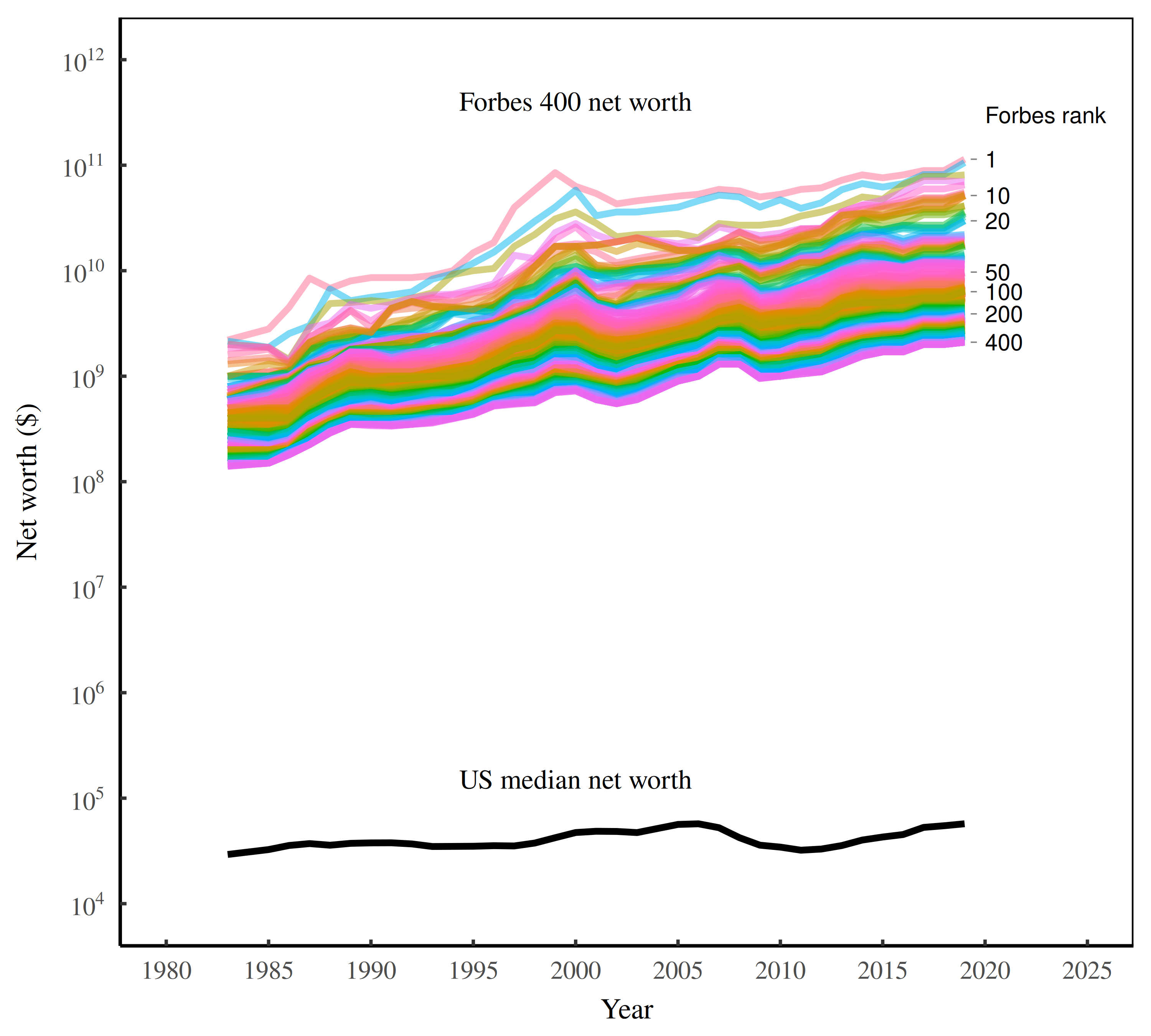
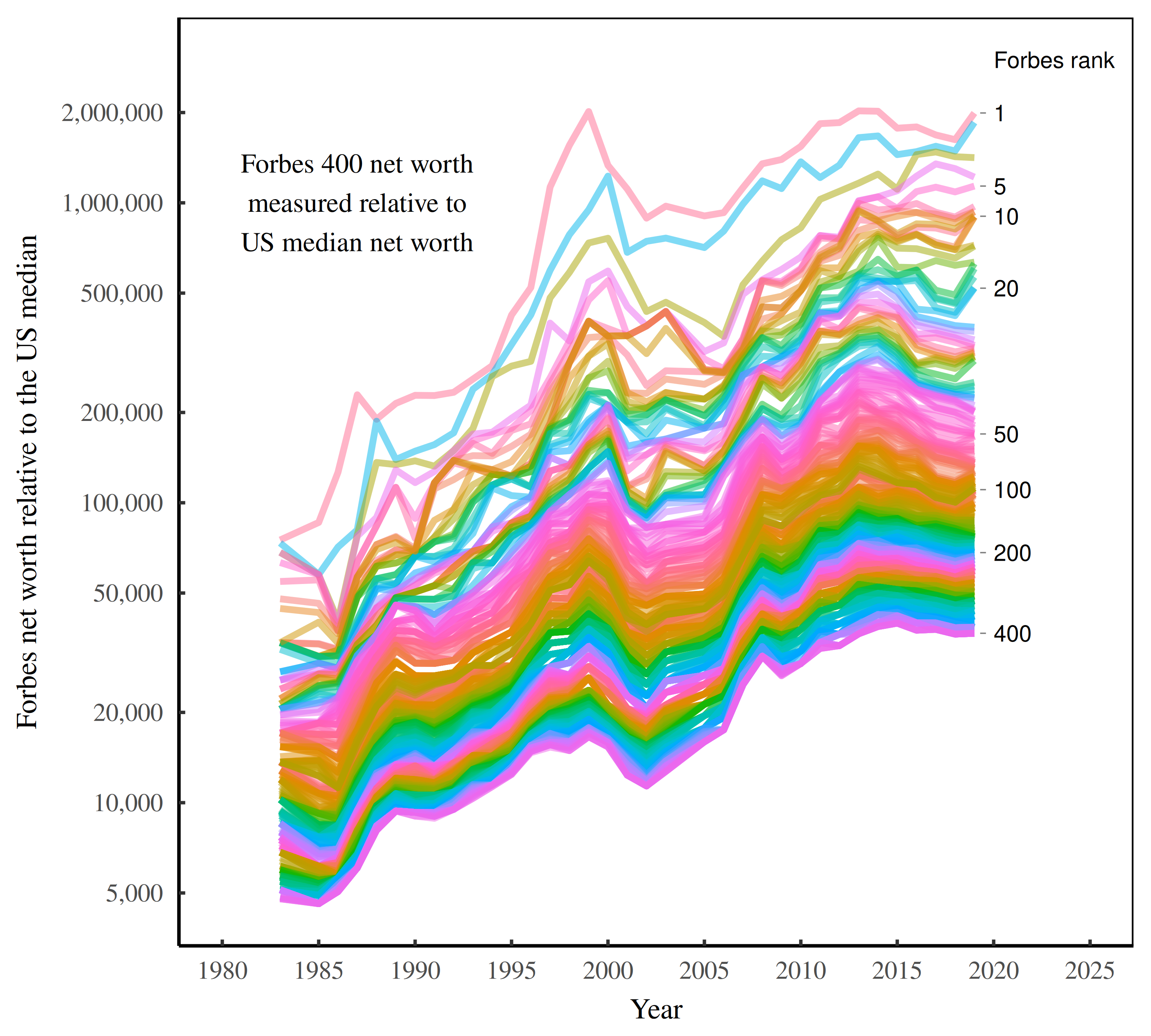
Some perspective.
In 1983, the richest American (Gordon Getty) had 75,000 times more wealth than the median American. By 2019, the richest American (Jeff Bezos) has *2 million* times more wealth than the median.
Filthy rich.
https://economicsfromthetopdown.com/2023/09/24/how-the-rich-get-richer/
{kind=link}
{kind=link}
Assistant Professor at UBC; MRI, Medical Imaging, Neuroscience; Books and Mountains
https://github.com/WeberLab
weberlab.github.io
Joined Nov 2022
