

Cerstin Mahlow @CerstinMahlow@qoto.org
Writing Researcher and Computational Linguist | Lives in Vaud, Zurich, and Uckermark | «Isch no schön – hamers aber e chli grösser vorgstellt.»
Joined Nov 2022
Cerstin Mahlow
boosted

Also in 1545, Zurich’s only printer, Christoph Froschauer, used his trademark frog on the title page of Conrad Gessner’s 'Bibliotheca Universalis'. #bookhistory
The trademark frog derives from a translation of the printer’s last name: frog in German “Frosch”. So Frosch-auer had an easy trademark decision. #histodons
Cerstin Mahlow
boosted

Today I passed these railings walking near oval station.
They may not look like much but they are part of the city's history.
They were originally medical stretchers used in the blitz. When the war was over they were welded into place as railings when rebuilding the city so save on metal.
#london #history #londonHistory
Was der Deepmind Gründer Demis Hassabis über Chat-GPT denkt
Cerstin Mahlow
boosted

So my question is this: what are the chances that a large language model could be trained which is large enough to work as a calculator-for-words, but small enough to run on, say, an M2 Max MacBook Pro with 64GB of RAM?
Is that already known to be impossible, or is there research that hints that this could be achieved given the right optimizations and a really well chosen training set?
Cerstin Mahlow
boosted

Using machine learning to try to sift the knowledge out of the rest of it is another lever for thinking -- like writing, language, mathematics. I think & communicate today in ways that weren't possible when my tools were a typewrite, a library card, and a telephone. If I was starting out instead of retiring, I'd be making LLM tools part of my mind-extending toolkit.
(2/2)
Cerstin Mahlow
boosted
It helps me think about the "human-computer symbiosis" potential of large language models by forgetting "AI" and focusing instead on the extensions I use for my thinking & communicating, from the keyboard to the WWW. In aggregate, the enormous corpus of material that humans uploaded provides an incredibly rich stew of knowledge, nonsense, & bullshit.
(1/2)
Cerstin Mahlow
boosted

Well, that didn't take long. We're starting to see almost-believable autogenerated text being used so spam our issue tracker.
There's a legitimate chance that ChatGPT and their ilk are going to kill participatory open source. How can you keep any forums open to the public, when anyone can just pour an arbitrary amount of generated garbage into them?
How do you tell a smart but green contributor who's still learning the language from a thousand bots spewing averacitous trash?
Cerstin Mahlow
boosted

A.I. Like ChatGPT Is Revealing the Insidious Disease at the Heart of Our Scientific Process
"vetting a scientific document takes a lot of thought and work, and the scientists who do it aren’t generally paid by the journals they’re doing all this labor for. It shouldn’t come as a surprise that often they—or the graduate students they dragoon into doing the work for them—don’t always do the best job of review. And as the number of publications..."
https://slate.com/technology/2023/01/ai-chatgpt-scientific-literature-peer-review.html
Cerstin Mahlow
boosted

I don't post much on mastodon yet but here's a couple of CfP's for low res etc. #nlp to follow:
* [loresmt](https://sites.google.com/view/loresmt/)
* [field matters](https://field-matters.github.io)

Cerstin Mahlow
boosted

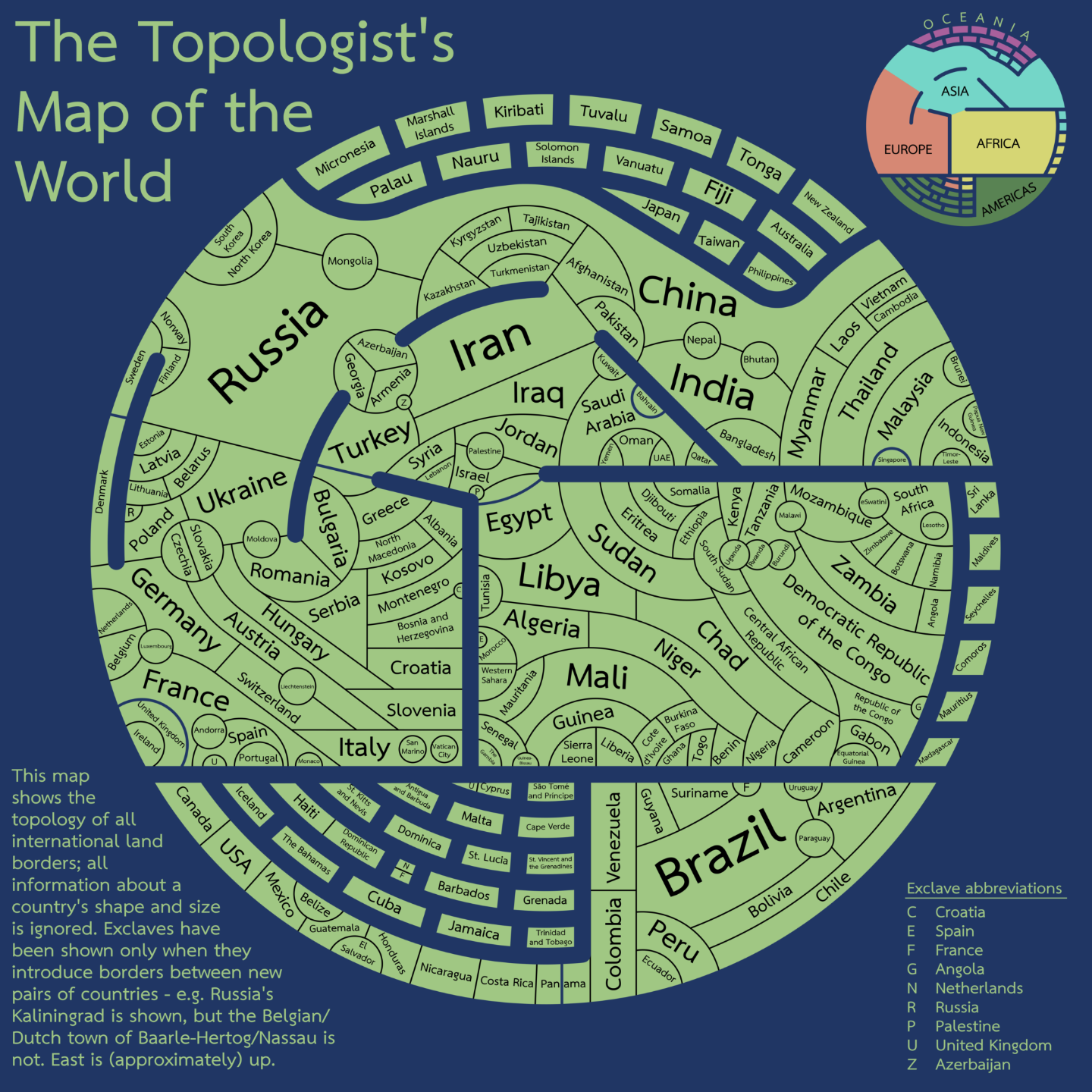
Really charming "topologists world map."
Forget size or position, this map *only* shows which countries border which other countries: http://tafc.space/qna/the-topologists-world-map/
Cerstin Mahlow
boosted

Getty’s new complaint is much better than the overreaching class action lawsuit I wrote about last month. The focus is where it should be: the input stage ingestion of copyrighted images to train the data. This will be a fascinating fair use battle.
Cerstin Mahlow
boosted
Getty also alleges that Stability AI removed or altered copyright management information and infringed Getty's trademarks by reproducing variations of its watermarks in output images.
Cerstin Mahlow
boosted
BREAKING: Getty Images just filed a copyright and trademark infringement lawsuit against Stability AI in Delaware District Court. Getty alleges that Stability copied more than 12 million Getty photos to train Stable Diffusion. Full complaint here: https://copyrightlately.com/pdfviewer/getty-images-v-stability-ai-complaint/
Cerstin Mahlow
boosted

Cerstin Mahlow
boosted

Vom 07. bis zum 09.11.2023 findet an der Fachhochschule Graubünden in Chur (Schweiz) das 17. Internationale Symposium für #Informationswissenschaft (#ISI2023) mit dem Titel „Nachhaltige #Information - Information für #Nachhaltigkeit“ statt. Der #CfP findet sich unter: http://isi2023.informationswissenschaft.org/en/call-for-papers/. Beiträge können ab dem 01.05.2023 über „EasyChair“ eingereicht werden.
Cerstin Mahlow
boosted

Swinging into the weekend with the great Jutta Hipp. Alas, her "career" as a jazzer was short-lived (Leonard Feather - no matter his merits - was a pretty toxic dude in today's terminology, it seems).
Cerstin Mahlow
boosted

Cerstin Mahlow
boosted

Cerstin Mahlow
boosted

Was mich in Sachen #ChatGPT langsam wirklich besorgt: Kaum jemand scheint wirklich zu verstehen, dass es sich um einen ChatBot handelt, der die Wahrscheinlichkeit berechnet, nach der Wort B nach Wort A kommt. Es ist kein Lexikon, es hat kein inhärentes Wissen, es ist "nur" darauf trainiert, sich möglichst natürlich zu unterhalten. Aber vor allem Medien erzählen das Märchen einer Wissensmaschine, die alle Fragen beantworten kann. Nein. ChatGPT erfindet Fakten & Quellen, wenn es nicht weiter weiß.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Writing Researcher and Computational Linguist | Lives in Vaud, Zurich, and Uckermark | «Isch no schön – hamers aber e chli grösser vorgstellt.»
Joined Nov 2022
