
Learning about protein language models; it's pretty mind-blowing.
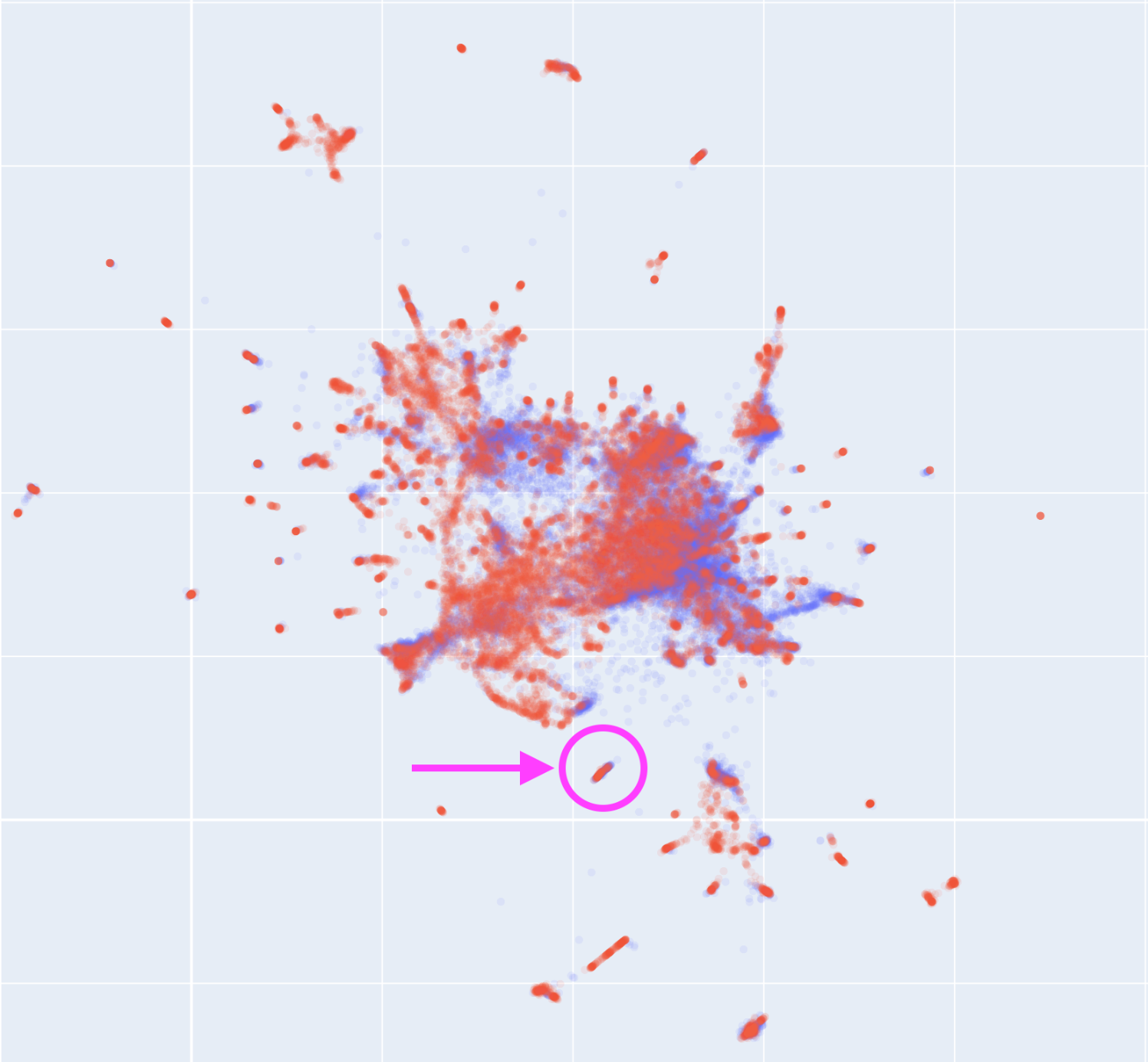
For example the UMAP cluster indicated in the image contains both human (blue) and worm (red) ribosomal proteins — not sequence homologs, but proteins with common functions.
To make this I downloaded the per-protein embeddings from Uniprot and just did a simple UMAP fit of the worm proteins, then mapped the human proteins using the same fit. They line up nicely, though there are lots of species-specific regions too.

{kind=link}
@pmcarlton what’s UMAP? I’m not sure I understood the X,Y axes nor the implication of two proteins being at the same coordinates 😅😅
@Chl0e_Girard That's because I gave a crap explanation! =) Each protein is represented by a vector of 1024 numbers derived from a language model (the part I do not understand yet), and UMAP is a method to project each vector into a 2-dimensional space (so X and Y axes are just arbitrary "positions") while trying to preserve the original spatial relationships. All the proteins that "look" similar in the vector representation should cluster nearby. Sadly I could not find a worm Iho1 this way!
@pmcarlton got it ! Where do you generate these maps?

@Chl0e_Girard
So far it's more a toy for exploration than anything else but I hope to develop it into something useful. I need to find a student to help with it