

barefootstache @barefootstache@qoto.org
- Website
- https://bf5.eu/
- Pixelfed
- https://pixelfed.de/barefootstache
- OSM account
- https://en.osm.town/@barefootstache
Mod
I am a strong proponent of leaving this planet better behind than when I arrived on it. Thus to get the most bang for a lifetime my key focus is #longevity which I attempt to achieve with #nutrition specifically #plantbased.
Longevity is good and all as long as you are not frail and weak. Ideally would be to die young at an old age. Thus I incorporate tactics from #biohacking and #primalfitness. Additionally I am an advocate of #wildcrafting, which is a super set of #herbalism.
Studied many fields of science like maths or statistics, though the constant was always computer science.
Currently working as a fullstack web developer, though prefer to call myself a #SoftwareCrafter.
The goal of my side projects is to practice #GreenDevelopement meaning to create mainly static websites. The way the internet was intended to be.
On the artistic side, to dub all content under the Creative Commons license. Thereby, ideally, only using tools and resources that are #FLOSS #OpenSource. #nobot
Joined Mar 2021
#DailyBloggingChallenge (163/200)
For the past 8a, I have been living in room without a functioning heater due to me unintentionally closing the valves on the in/output pipes.
Today, I decided I might as well try my luck again and for the first time I heard liquid flowing through.
Cold management wasn't too bad over the almost past decade, though the secondary conditions like increased relative humidity causing unknown mold build up, was the final straw of something needing to change. Because if one is staying 80% or more time in a room that is causing one harm, eventually it will kill you.
#DailyBloggingChallenge (162/200)
One inconvenience of single file scripting is eventually the overview becomes hard to manage. Thus one realizes that one will need to split up the file into files.
#Webpack gives a solution for building multiple files into one. Plus if one takes the extra effort of setting up #TypeScript one will get the benefits of type safety.
#DailyBloggingChallenge (161/200)
The Simple-Dashboard-Maker tool (https://codeberg.org/barefootstache/Simple-Dashboard-Maker) got a couple new features:
- new social media template
- 7 new icons
- instructions on how to setup local bookmarks using the `file://...` path from your browser and pointing to a HTML file
- instructions on having personal dashboards living in the project directory, thus permitting to have access to the styling
#DailyBloggingChallenge (160/200)
Back on #BookWyrm after the past instance (bookwyrm.tech) burnt. One can follow me at @barefootstache@bookrastinating.com.
In year 2023, I attempted the "one book a week" challenge and made it to 19 books.
Initially joined with the additional challenge of adding the books to #WikiData.
The sad part is that I retained very little from the books that were read last year.
Might be wise to add a book report within the "daily blogging challenge", thus making me to interact with the content in more depth than the quick first glance.
#DailyBloggingChallenge (159/200)
This #TypeScript function builds a website from scratch with the `body` parameter being the only necessary input.
```
/**
* Opens a new window with a 'title'.
*
* @param body - the body of the HTML page
* @param style - the style of the HTML page
* @param title - the title of the HTML page
* @param script - the javascript of the HTML page
*/
static openNewWindow(body:string, style = '', title="new display", script=''):true {
const mywindow = window.open('', '_blank') as Window;
mywindow.document.write(`<html><head><title>${title}</title>`);
mywindow.document.write(`<style>${style}</style>`);
mywindow.document.write('</head><body>');
mywindow.document.write(body);
mywindow.document.write('<script>');
mywindow.document.write(script);
mywindow.document.write('</script>');
mywindow.document.write('</body></html>');
mywindow.document.close(); // necessary for IE >= 10
mywindow.focus(); // necessary for IE >= 10*/
return true;
}
```
This can be use as a way to display the scraped data.
#DailyBloggingChallenge (158/200)
One option for future processing is opening a new tab as #HTML page.
This has the benefit that the header details stay constant meaning calling media like images aren't being blocked by #CORS. Further one can highlight the details that one deems important compared to the original creator.
One builds the HTML page as a string, just as one typically would do. The only difference is that the file extension is `*.js` instead of `*.html`.
barefootstache
boosted

There's truth in the Embrace, Enhance, Extinguish theory. But #Meta has its own strategy. It's called Copy, Acquire, K*ll.
I wrote about that strategy as it relates to #threads and #mastodon. I also have some insight for what Zuck might be up to. It's not what you think.
#PostsFromJason #FediSeriesFJ
#DailyBloggingChallenge (157/200)
When actively scraping, the main starting function is
```
document.querySelectorAll()
```
This will return a `NodeList`, which typically one will use a for-loop to loop over each item.
On each item either the `querySelector` or `querySelectorAll` will be applied recursively until all specific data instances are extracted.
This data is then saved into various formats depending on future processing, either as on object in an array or as a string, which is then saved either to the `localStorage`, `sessionStorage`, `IndexDB`, or downloaded via a temporal link.
#DailyBloggingChallenge (156/200)
The question persists why one should learn how to scrape? The obvious answer is to get data from the webpage. Though further reasons are to learn how to evaluate a website and then build extensions to present the page to one's liking.
Although web scraping might have a negative connotation, how much different is it from skimming literature and choosing the specific patterns. And with AI/LLM on the rise, now one can evaluate texts even quicker.
barefootstache
boosted

This is a majestic view of Mt. Fuji surmounted by lenticular clouds while reflected in a lake.
[📸 Taitan21] #Japan #MtFuji #photography
#DailyBloggingChallenge (155/200)
To actively scrape a #website one employs either an extension or uses the console.
Here the difference is where and who maintains the code. The benefit of using the #console is that one is browser agnostic and still can keep a level anonymity. Whereas with an extension could be used as a fingerprint marker.
E.g. if using the #Tor browser one should not diverge from the installed extensions, since one will easier identified compared to the herd. Using the console would be preferred in this case.
On the flip side using an extension voids the need to copy and paste the code into the console every time.

#DailyBloggingChallenge (154/200)
To passively scrape a webpage one uses automation tools, ideally headless browsers like #Selenium or #Puppeteer. Of course one can use any tool that is typically used for #e2e testing in the #browser.
The biggest obstacle for passively scraping is dealing with either #captcha or #cloudflare.
There are options to use captcha farms for a small monetary fee. And Cloudflare can be over come by IP hopping.
In general, passively scraping only works on websites that were poorly configured.

barefootstache
boosted

Android Auto support for our sandboxed Google Play compatibility layer has been merged into GrapheneOS and should be available in the next release. It's currently going through final review and internal testing leading up to being able to make a public Alpha channel release.
#DailyBloggingChallenge (153/200)
There are two main ways to #scrape a #website, either actively or passively.
_Active scraping_ is the process of using a trigger to actively scrape the already loaded webpage.
_Passive scraping_ is the process of having the tool navigate to the webpage and scrape it.
The main difference is how one is getting to the loaded #webpage.
barefootstache
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
#DailyBloggingChallenge (152/200)
Not only hardware is a concern, though also internet speed. Lots of websites use some kind of media like images or videos and many don't convert these to slow internet friendly speeds.
For images WEBP suffices and for videos a bit rate of 8Mbits.
#DailyBloggingChallenge (151/200)
Lots of websites these days are being first built on the client. This can easily be checked when downloading the #website does not align with the #HTML from the inspector.
This has the benefit for the provider to save transfer cost, though on the flip side, the client will need to have a specific amount of #hardware to successfully render the site.
#DailyBloggingChallenge (150/200)
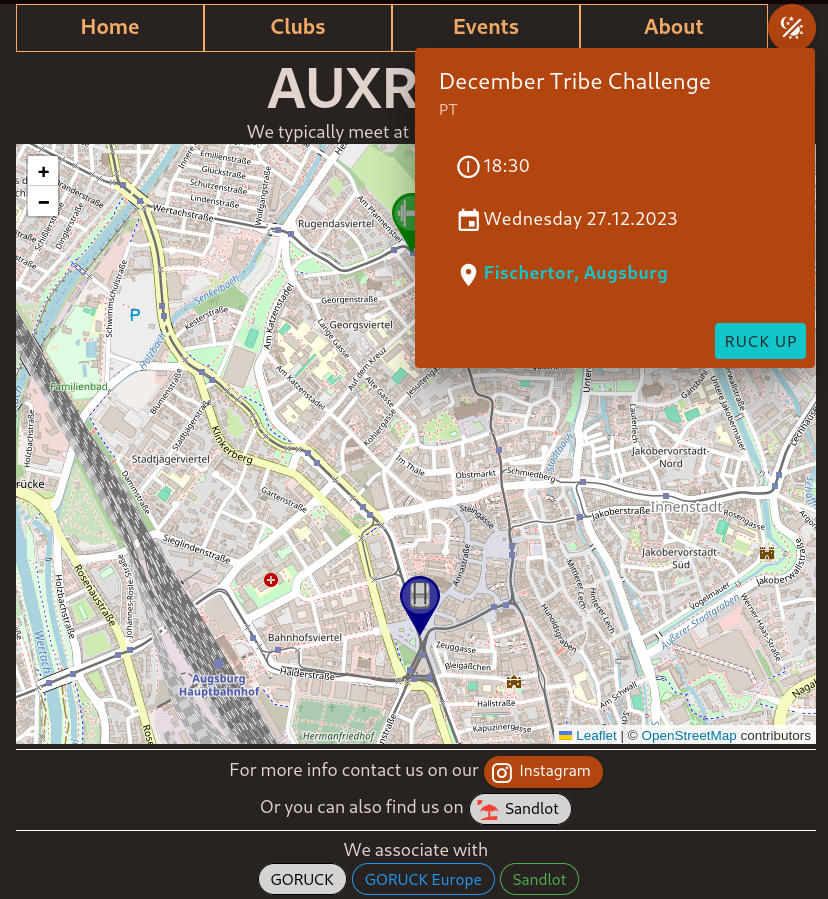
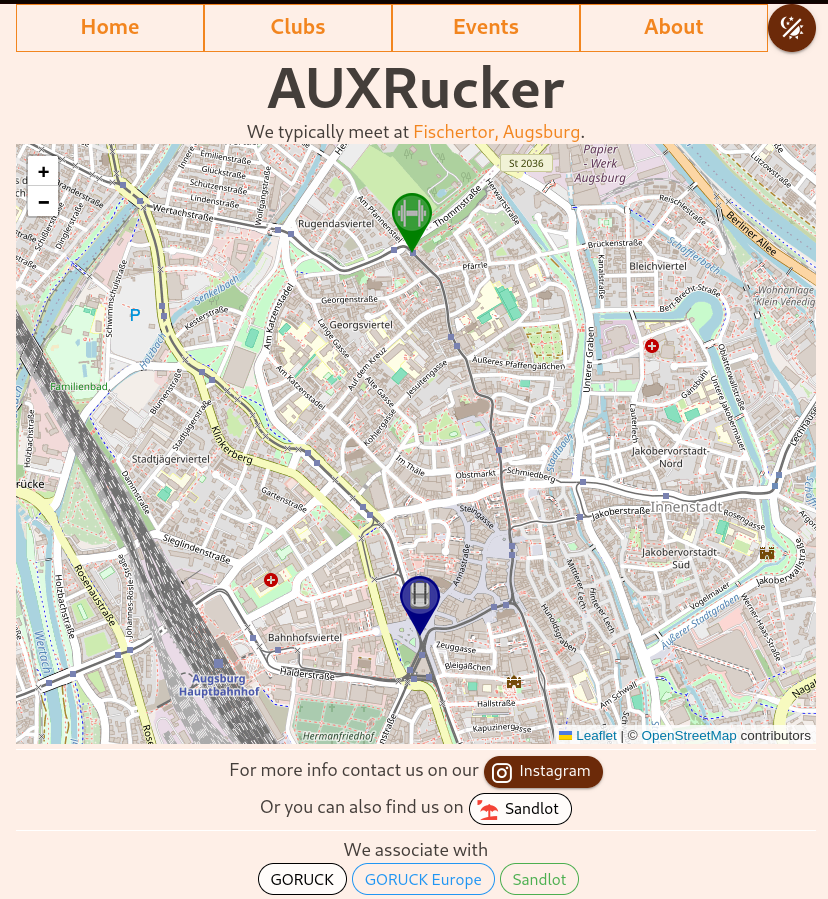
Designing themes with #Vuetify is fairly straightforward, the difficulty is creating a #design or color palette in the first place.
In this approach the "import full palette" method was chosen. This consists of importing the color palette and assigning each color an unique identifier. The type `ThemeDefinition` exists to help with naming conventions. The addition name to add is `accent` which should fit well with the `primary` and `secondary` colors.
Later when the #theme is being built one can directly choose from the palette.
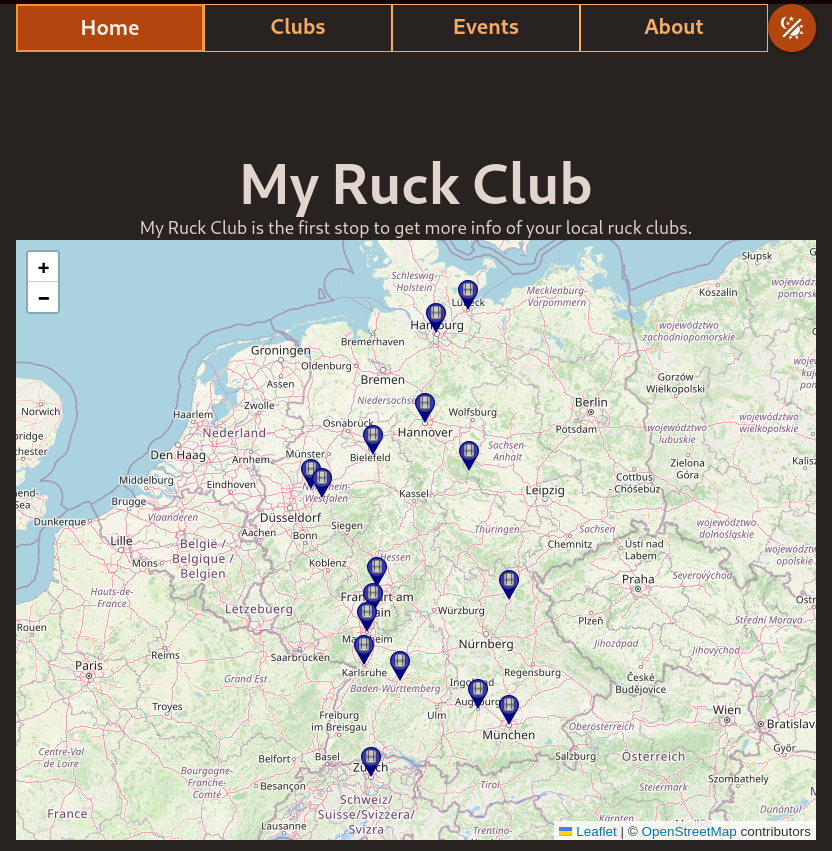
#devlog - New color theme with dedicated color palette and dark/light toggle button. - Markers on map finally have a dialog popup (which was one f...
{kind=link}
{kind=link}
{kind=link}
- Website
- https://bf5.eu/
- Pixelfed
- https://pixelfed.de/barefootstache
- OSM account
- https://en.osm.town/@barefootstache
Mod
I am a strong proponent of leaving this planet better behind than when I arrived on it. Thus to get the most bang for a lifetime my key focus is #longevity which I attempt to achieve with #nutrition specifically #plantbased.
Longevity is good and all as long as you are not frail and weak. Ideally would be to die young at an old age. Thus I incorporate tactics from #biohacking and #primalfitness. Additionally I am an advocate of #wildcrafting, which is a super set of #herbalism.
Studied many fields of science like maths or statistics, though the constant was always computer science.
Currently working as a fullstack web developer, though prefer to call myself a #SoftwareCrafter.
The goal of my side projects is to practice #GreenDevelopement meaning to create mainly static websites. The way the internet was intended to be.
On the artistic side, to dub all content under the Creative Commons license. Thereby, ideally, only using tools and resources that are #FLOSS #OpenSource. #nobot
Joined Mar 2021
