

barefootstache @barefootstache@qoto.org
- Website
- https://bf5.eu/
- Pixelfed
- https://pixelfed.de/barefootstache
- OSM account
- https://en.osm.town/@barefootstache
Mod
I am a strong proponent of leaving this planet better behind than when I arrived on it. Thus to get the most bang for a lifetime my key focus is #longevity which I attempt to achieve with #nutrition specifically #plantbased.
Longevity is good and all as long as you are not frail and weak. Ideally would be to die young at an old age. Thus I incorporate tactics from #biohacking and #primalfitness. Additionally I am an advocate of #wildcrafting, which is a super set of #herbalism.
Studied many fields of science like maths or statistics, though the constant was always computer science.
Currently working as a fullstack web developer, though prefer to call myself a #SoftwareCrafter.
The goal of my side projects is to practice #GreenDevelopement meaning to create mainly static websites. The way the internet was intended to be.
On the artistic side, to dub all content under the Creative Commons license. Thereby, ideally, only using tools and resources that are #FLOSS #OpenSource. #nobot
Joined Mar 2021

barefootstache
boosted

I like how we took something computers were masters at doing, and somehow fucked it up.
morning goal:
shower faster than the coffee is brewing
It is better to be an octopus than a fisher when acquiring #knowledge. Since it is easier to release the tentacles' suctions than taking out a hook.
One skill #developers acquire is being able to understand various concepts in many different #programming languages. Though schemas in one language usually poorly port over to another language and with the age of #LLM assisted coding tools, it is not that hard to force one's secondary language biases onto the new one.
This creates a quick deep water experience before one has even learnt the basics of the new language, which does not follow the traditional linear educational approach and could be argued that it's better since it will be easier to create multiple tentacle suction points over relying on well placed hooks.
If one has the opportunity to work on two similar projects at the same time with the one being the motivational anchor and prototype slate while the other rises on the shoulders of the conclusions. Then one will only need to inact personal harmonization to get both projects over the finishing line.
Through the motivational anchor one will be hooked to constantly continue development and thereby acquire the skill and knowledge that should transfer smoothly to the other project without too much self sabotage on progressing it further, since it is easier to achieve anew once one knows the procedures and felt the execution of them.
Confused why the tumbler was leaking after placing it upright in the ruck, only to later realize that I forgot to close the opening.
barefootstache
boosted

I’m officially done with takes on AI beginning “Ethical concerns aside…”.
No! Stop right there.
Ethical concerns front and center. First thing. Let’s get this out of the way and then see if thre is anything left worth talking about.
Ethics is the formalisation of how we are treating one another as human beings and how we relate to the world around us.
It is *impossible* to put ethics aside.
What you mean is “I don’t want to apologise for my greed and selfishness.”
Say that first.
barefootstache
boosted

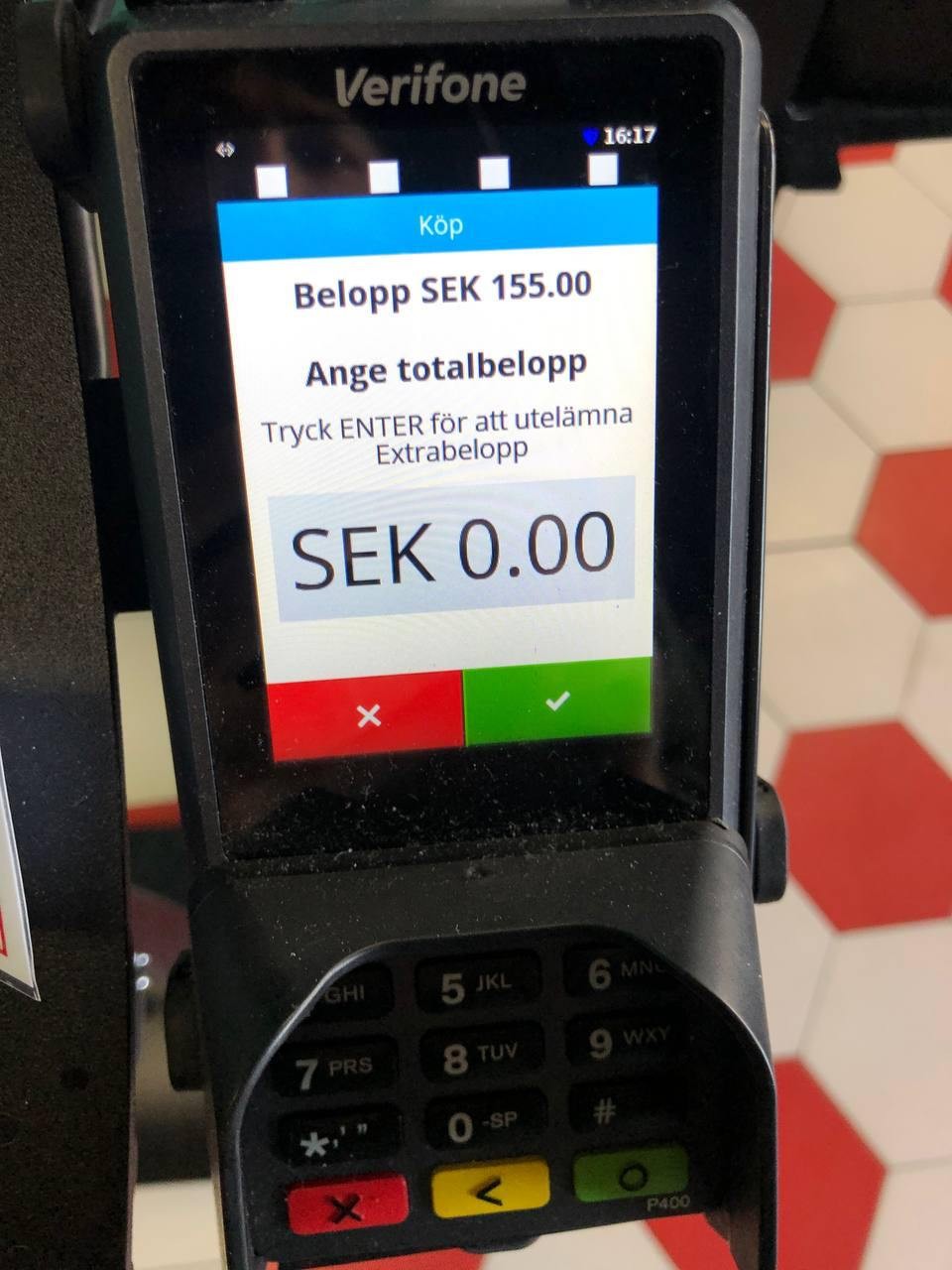
I notice more and more that self-service checkouts and payment terminals in Stockholm's bars persistently suggest leaving tips. Honestly, I don't really understand the logic: tipping is fundamentally a reward for good service. What service is there if I place the order myself via a machine and pick it up myself? My subjective feeling is more irritation than gratitude. This type of practice doesn't make me want to return, rather it decreases my loyalty to the place. #SelfService #Tipping #Stockholm #CustomerLoyalty
barefootstache
boosted

☀️⚡️ Everyone in Switzerland agrees we need more solar. But often, there's disagreement about where to put the panels without impacting the landscapes too much.
🛤️ Looking back, this one is a no-brainer, why not lay them down between train rails: there's already a strong connection to the grid, and it's infrastructure that's already ‘built’.
🇨🇭 First segment of the tracks got inaugurated today in canton Neuchâtel.
https://www.rts.ch/info/regions/neuchatel/2025/article/la-premiere-centrale-solaire-sur-rails-a-ete-inauguree-dans-le-canton-de-neuchatel-28863275.html
Supplier: https://www.sun-ways.ch

barefootstache
boosted

Be careful with what you install on your phones.
If the findings in this article are true, then most of the bot traffic that has recently taken down many small and independent websites (code forges in the first line) comes from a quite sophisticated network of scrapers sold as services.
My small Forgejo instance has also experienced brief downtime and slowness a couple of weeks ago, but luckily nothing compared to the instances of Gnome and KDE (which had to implement aggressive captcha to mitigate the flood). Basically anything that isn’t behind Cloudflare is a potential victim.
The pattern is mostly the same in all these cases. Residential IP addresses and legitimate user agents that don’t advertise themselves as bots, let alone honor the robots.txt files, making life for the sysadmins who try to block this traffic very hard.
These bots also request heavy pages (such as git logs and blames) in large volumes, which has taken down a lot of Gitlab, Gitea and Forgejo instances.
The business model behind this phenomenon seems to be quite sophisticated.
As a developer of a mobile app, I can include the SDK of a product like Infantica inside of my code. It doesn’t even have to be my own app. There have been cases where other people’s apps were simply repackaged with these SDKs ans redistributed on stores.
That SDK in turn transforms any device it’s been installed on into a member of a vast botnet without the user’s consent or knowledge.
The customers are usually companies that want to train large AI models, but can’t afford the costs (or simply don’t want to pay them, or have a limited pool of IP addresses for scraping that may easily be blocked by sysadmins).
What they do then is pay companies like Infantica to leverage infected devices (i.e. mostly mobile phones with apps that include their SDK) to scrape the web for them and push data wherever they want.
Developers who include the SDK in their apps also get a share of the pie - hence the financial incentive to repackage and redistribute even 3rd-party apps with the incriminated SDK: minimize the development effort, maximize the revenue.
Of course, the commands that “customers” can send to the botnet aren’t limited to scraping and training for AI purposes. It’s just that this is what currently pays best (it used to be crypto mining until a while ago). In theory, nothing prevents them from sending commands to access anything on the infected devices. Of course, companies like Infantica claim that they do their due diligence and scan all usages of their products to prevent abuse, but when a company already has such low moral standards you know how to take their claims.
Note that what until a couple of years ago would have been called “a zombie device infected with nasty malware that turns it into a botnet member at the mercy of whatever the best paying customer wants to do with it” has now been repackaged as a legit business product with its own business jargon. They are now called “residential rotating IP addresses that form an insightful peer-to-business network”.
And the volumes are also scary. Infantica alone claims that it can sell access to nearly 250K IPs in the US alone. That’s nearly one American in 1000. And when you take into account that there are dozens of companies that operate in the same sector, the volumes become scarier.
Unfortunately it’s hard for non-technical users to know which apps run such SDKs, and if there are such apps already installed on their phones. But there are a few precautions that can be taken to mitigate the risk.
First, avoid mobile apps when possible. Their potential abuse as AI scrapers is only the latest threat that they pose. They have a lot of privileges once installed and have a huge surface of attack. It’s ok to have an app for your camera. Whether it makes sense to have an app to check discounts at your local store, it’s debatable. Use websites instead of apps whenever possible. Many of them can be installed on your phone nearly as a full app through the PWA paradigm, but since those Webapps will always be sandboxed inside your browser they can’t do much damage. And always, always avoid whenever possible products whose website is a single “Download our app” page. There’s a reason why we decided that an open web is better than a bunch of closed apps, and we should punish those who don’t agree with those reasons.
When you have no choice but to install an app, always look for comparable alternatives on e.g. F-Droid. Apps on open-source stores have much more scrutiny than whatever crap is uploaded to the Android and Apple stores. Each app is monitored for any external connections, and those are marked as anti-features. Plus, each app is forced to share its source code. Google and Apple have their big responsibilities for this mess. If an Android SDK exists that turns phones into botnet zombies that can run arbitrary payloads, then that SDK should be considered as malware. Period. Any app that includes that SDK in its dependencies or includes any of those packages should be automatically flagged and removed from the store. The fact that this doesn’t happen, and millions today run infected software on their phones downloaded from legitimate app stores, means that Google and Apple are either grossly negligent or grossly corrupt - in either case, they can’t be trusted for the safety of the software you download from their stores.
And, when you have no choice but to get an app from an official store, always prefer alternative store frontends like Aurora, which at least scans the apps from the Play Store and transparently informs you about any trackers and data access patterns.
Finally, I disagree with the last stance in this article - that every form of web-scraping should be considered abusive behaviour. Scraping is one or the foundational pillars of the Web as we know it today. And the vision of a Web accessible both to humans and machines is a foundational pillar of the semantic Web. It’s not scraping the problem. But, for scraping to be a game where everyone wins, two issues must be solved:
The right to scraping needs to be symmetric. If Google, Meta or Microsoft can freely scrape my websites to train whatever AI hyped bullshit they want to train with it, then I also have the right to scrape their services. If instead they can eat my blog’s RSS feed or my monthly code commits for breakfast, but scraping my Facebook homepage to automatically expose my friends’ birthdays through another service may result in my account being banned, then we have a problem.
The unfortunate alignment of financial incentives and impunity in recycling what until a couple of years ago was basically a criminal activity (installing malware on people’s devices) into a legitimate business model with shiny business-friendly websites and account managers. I don’t mind a world where bots identify themselves as bots through standard user agents, so I can easily block them if I want to, respect my robots.txt settings, and sensibly throttle their requests. But I have a problem with a world where all these gentlemen’s agreements are broken, where the costs of training expensive AI models are so explicitly externalized, and paid by thousands of independent Web administrators through electricity costs, performance degradation costs and downtime management costs, and where those who break the rules are free to operate as listed companies instead of being in jail, and where their malware is allowed to spread through standard software distribution channels.
https://jan.wildeboer.net/2025/04/Web-is-Broken-Botnet-Part-2/
barefootstache
boosted

Helping a friend do something on their computer, I noticed that they didn’t have an ad blocker.
Security and privacy aside, their browsing experience was atrocious.
Impossibly, unusably dire.
Now they have an adblocker, and web pages are uncluttered? Readable? Actually usable?
What a sorry state of affairs.
Adblocking is self care and just plain sensible.
barefootstache
boosted

Today I learned about the Pistacci raid by the SAS in WWII. It's almost unbelievable.
barefootstache
boosted

The internet didn’t make us stupid. It made stupidity scalable.
barefootstache
boosted

The fact that we, as a society, tolerate the lies that LLMs systematically output is quite telling of how used we've become to untruth in the public sphere. We're not even complaining anymore. We take lying for granted. It's immensely sad.
barefootstache
boosted

finally wrote something real about what i've been building!
too many of my infra workflows were buried in slack threads, docs, or shell history
so i started working on Atuin Desktop:
- runbooks that run
- local-first, crdt-powered
- embedded terminals, db queries, monitoring blocks
more words here: https://blog.atuin.sh/atuin-desktop-runbooks-that-run/
would love to know what you think! ❤️ ![]()
barefootstache
boosted

Four things you must always ask yourself before you say anything:
1. Does this need to be said?
2. Does this need to be said by me?
3. Does this need to be said by me now?
4. Would it be fucking funny if I did, though?
barefootstache
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Haha, that's one way to deal with it. I'm not sure how effective it is, though.
{kind=link}
- Website
- https://bf5.eu/
- Pixelfed
- https://pixelfed.de/barefootstache
- OSM account
- https://en.osm.town/@barefootstache
Mod
I am a strong proponent of leaving this planet better behind than when I arrived on it. Thus to get the most bang for a lifetime my key focus is #longevity which I attempt to achieve with #nutrition specifically #plantbased.
Longevity is good and all as long as you are not frail and weak. Ideally would be to die young at an old age. Thus I incorporate tactics from #biohacking and #primalfitness. Additionally I am an advocate of #wildcrafting, which is a super set of #herbalism.
Studied many fields of science like maths or statistics, though the constant was always computer science.
Currently working as a fullstack web developer, though prefer to call myself a #SoftwareCrafter.
The goal of my side projects is to practice #GreenDevelopement meaning to create mainly static websites. The way the internet was intended to be.
On the artistic side, to dub all content under the Creative Commons license. Thereby, ideally, only using tools and resources that are #FLOSS #OpenSource. #nobot
Joined Mar 2021
