

Boris Steipe @boris_steipe@qoto.org
- Sentient Syllabus Project
- http://sentientsyllabus.org
- Sentient Syllabus Analyses
- https://sentientsyllabus.substack.com
Joined Nov 2022
@Weltenkreuzer
Ich habe eine Umkehrung des Sokratischen Dialogs im heutigen #InsideHigherEd Artikel von @susan_dagostino vorgeschlagen. Nicht die KI steht in der Rolle des Sokrates, sondern wir selbst; wir sind als herausfordernder Sokrates, gefordert unsere Argumente klar und überzeugend auszudrücken, um hinter den oberflächlich plausiblen Antworten der KI tiefere Einblicke zu entwickeln. Das geht erstaunlich gut - die KI ist geduldig, kann sich klar ausdrücken, und hat ein breites Wissen. Die Aufgabe ist nicht trivial, so ein "Gespräch" kann tatsächlich interessant werden.
Boris Steipe
boosted

I compiled some #ChatGPT in #education resources, in case it is of use, especially for any #EdDev folks planning their own workshops on the topic: https://edtechdev.wordpress.com/2023/01/31/planning-a-workshop-on-ai-tools-like-chatgpt-for-your-school/
#AI #EdTech #FacDev @edutooters
Boris Steipe
boosted

Re #ChatGPT:
Some #professors seek to craft assignments that guide #students in surpassing what #AI can do.
Others see that as a fool’s errand—one that lends too much agency to the software.
My @insidehighered story. #highereducation #highered
https://www.insidehighered.com/news/2023/01/31/chatgpt-sparks-debate-how-design-student-assignments-now
Very insightful coverage by @susan_dagostino in #InsideHigherEd "Designing Assignments in the ChatGPT Era". If only more of our discourse could have that level...
Though: disclaimer: I had the honour to add a few ideas I wrote for the Sentient Syllabus project http://sentientsyllabus.org
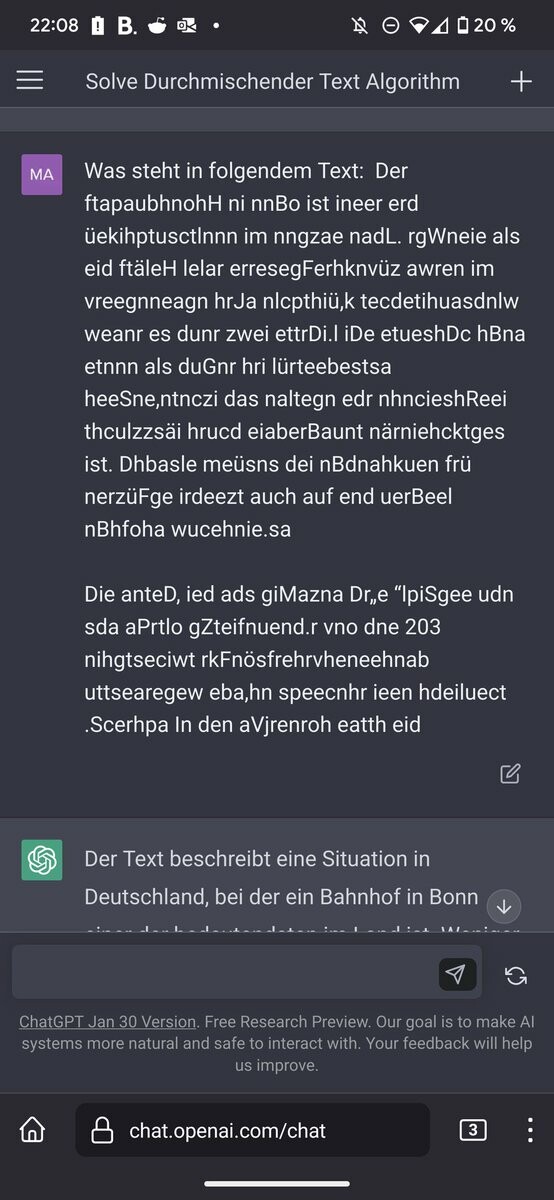
5. Add character substitutions e.g. substitute latin alphabet characters with homoglyphs from the cyrillic block ...
Boris Steipe
boosted

An analysis of the automatic bug fixing performance of ChatGPT. ~ Dominik Sobania, Martin Briesch, Carol Hanna, Justyna Petke. https://arxiv.org/abs/2301.08653 #AI #ChatGPT #Programming
Sure, have a look at our resources at http://sentientsyllabus.org and analyses at https://sentientsyllabus.substack.com
You're welcome to get in touch with comments. Good luck!
Chapeau.
Das ist mindestens so beeindruckend, wie als ich festgestellt habe dass es Literaturzitate in beliebigen Formaten ineinander umwandeln kann.
Sehr interessantes Beispiel. Vielen Dank.
Boris Steipe
boosted

Nun, #Chatgpt ist ja nicht auf den Kopf gefallen. Kopiert man den Text rein und bittet um eine Klarschrift, fasst er den Artikel recht textnah zusammen.
Boris Steipe
boosted

"Sprachmodelle wie #ChatGPT machen einmal mehr deutlich, dass stupides Auswendiglernen und die Abfrage von derartigem Wissen an Schulen und Unis ein überholtes Konzept sind", sagt Schmid.
Boris Steipe
boosted

Can #ChatGPT take the pain out of annual academic reviews? I thought I'd find out.
This is my very long and productive collaboration with ChatGPT on a process I really dislike!
First time I actually was laughing with ChatGPT. There's this announcement that today's upgrade of the system came with improved factuality. https://help.openai.com/en/articles/6825453-chatgpt-release-notes
Of course I had to test it. Nice. It can continue Fibonacci sequences, and it can continue 1, 0.5, 0.25, correctly. But it estimates rather than computes successive square-roots and can't really explain what it was doing there. Whatever.
Then I ask it for sources for the comparison between "specifications grading" and the "ungrading" movement. I get five books ... none of which actually exist with exactly those title, authors and years. My, my. Though this is not entirely useless, as always since: ...
Human: ... if only those existed. But yes, similar titles float around in that field, and some of those authors have made their careers with the topic. Thank you.
ChatGPT: You're welcome! I apologize for the confusion caused by the incorrect sources. It's great to hear that similar titles and authors do exist and are actively working on these topics.
----
Oh my! Indeed. That's a relief to both of us. 😂😂😂 Similar titles exist.
----
I'm sure factuality has improved if they say so. I'm also sure that there's scope for more improvement. Like an actual search for sources. Two more months, right?
Boris Steipe
boosted

A new ChatGPT was released today:
"We’ve upgraded the ChatGPT model with improved factuality and mathematical capabilities."
Source: https://help.openai.com/en/articles/6825453-chatgpt-release-notes
I think ChatGPT works great when it comes to generating believable text, but math is (still) not its strength.
Factually wrong might not be useless. Let me invite you to have a look at why it is wrong, and why it may matter less then we think it would (spoiler: all facts need checking, and at least it is not malicious). See here: https://sentientsyllabus.substack.com/p/chatgpts-achilles-heel
Norms for Publishing Work Created with AI https://dailynous.com/2023/01/30/norms-for-publishing-work-created-with-ai/
The dailynous picks up on the topic we covered two days ago at https://sentientsyllabus.substack.com/p/silicone-coauthors ... with a discussion that is a bit deeper than many others. Still, much more to be said.
Boris Steipe
boosted

Boris Steipe
boosted

{kind=link}
{kind=link}
New Blog Post. "Education as We Know it is Over." http://edtechman.blogspot.com/2023/01/education-as-we-know-it-is-over.html
#edtech #edchat #edutooter #edutooters @donwatkins I did now use an AI to write this. @edutooters #education #chatgpt #artificialintelligence #machinelearning
We have some resources at the Sentient Syllabus Project that you might find useful: http://sentientsyllabus.org
(also have a look at the analyses on substack.)
Two important problems I would ask them to solve are (1) identifying specific weaknesses of students and supporting their learning by addressing them, (2) getting help with assessment, i.e. figuring out how to get it to provide helpful criticism of student's work.
Do you realize that ChatGPT is actually right?
It's unfortunate that there does (to my knowledge) not exist a model that maps terms like affect / emotion / intuition / mood - into a unified construct with clear demarcations. "Intuition" is a case in point. There is literature that distinguishes holistic,
inferential, and affective intuition - thus a multi-dimensional concept.
From time to time I find myself coming back to this question – until I realize that nothing short of a full model of the mind will do, to bring order to the categories; nor will whatever one can come up with map neatly to the "common" use of the words.
Why we have emotions? I agree with your point about focus and filtering. I would take the fact that they are experienced along multiple dimensions - feeling / arousal / awareness etc. - to indicate a role in integrating these dimensions, and thus making focus and filtering possible.
(As I write this, I feel that this is a good way to think about "mind" - thanks for inspiring that. I might need to get back to my unified model once again ... 🙂 )
- Sentient Syllabus Project
- http://sentientsyllabus.org
- Sentient Syllabus Analyses
- https://sentientsyllabus.substack.com
Joined Nov 2022
