

Boris Steipe @boris_steipe@qoto.org
- Sentient Syllabus Project
- http://sentientsyllabus.org
- Sentient Syllabus Analyses
- https://sentientsyllabus.substack.com
Joined Nov 2022
Boris Steipe
boosted

Students are #writing my usual first paper assignment: just 2 paragraphs.
As usual, they say it's WAY harder than their usual paper assignments.
Today I asked, "How is the usual paper easier to write? Isn't it longer?"
“Yeah", one replied, "but writing 10-15 pages is easy. It can be mostly fluff. Even a #chatbot can easily do it. Proofreading is the hardest part.”
Why are my 2 paragraph essays so tough? And why can't chatBots do it?
(Toot 1 of 2)
Boris Steipe
boosted

I've been playing with #ChatGPT to see how niche it's knowledge can go.
So far, it has given me suggestions for troubleshooting my RV furnace which keeps overheating, and helped me plan out the next phase of my off-grid solar installation by helping me calculate voltages, amperages, and figuring out what wire gauge to use.
This is nuts.
#ChatGPT on your desktop?
FlexGen paper by Ying Sheng et al. shows ways to bring hardware requirements of generative AI down to the scale of a commodity GPU.
https://github.com/FMInference/FlexGen/blob/main/docs/paper.pdf
Paper on GitHub - authors at Stanford / Berkeley / ETH / Yandex / HSE / Meta / CMU
They run OPT-175B (a GPT-3 equivalent trained by Meta) on a single Nvidia T4 GPU (~ $ 2,300) and achieve 1Token/s throughput (that's approximately 45 words per minute). Not cheap, but on the order of a high-end gaming rig.
Implications of personalized LLMs are - amazing.
Boris Steipe
boosted

Discovered a new use for #chatgpt: Practice tests. Tell it what you're studying and what kind of questions you want. Fine tune the difficulty if you need to. The questions and answers are sometimes wrong, but if you use it for reviewing stuff you've already learned, it's usually fairly obvious and gives you a starting point.
After a few days of intriguing reports of induced instabilities in #Bing, its capabilities were (predictably) "aligned". Ars Technica calls the new interaction protocols a "lobotomy", in analogy to the anachronistic surgical procedure that was meant to "reduce the complexity of psychic life"(1).
It is probably a much more useful search engine now, right?
The flood of sympathetic reactions to Bing's earlier behaviour were themselves a significant comment. I had written a week ago " I actually don’t think this means we wanted AI to give us better search at all. We wanted search to give us better AI."
https://sentientsyllabus.substack.com/p/reading-between-the-lines
Indeed. More Sydney, less Bing. It will be interesting how this affects its ability to gain users.
(1) according to Maurice Partridge as quoted in https://en.wikipedia.org/wiki/Lobotomy
Boris Steipe
boosted

@spapjh Nice write up. I’ve started and stopped trying to learn Python several times. I am contemplating another attempt to make myself better in my new career.
#ChatGPT is all over the news for the doomsday predictions it might become. But @malwaretech did a really great video of how to add it to your learning toolbox:
@kevinroose of the
@NewYorkTimes has posted his transcript of one of the "unhinged" #Bing conversations that appeared recently.
https://www.nytimes.com/2023/02/16/technology/bing-chatbot-transcript.html
This is interesting, because it is "data" – the entire conversation, unedited.
Reading between the lines, it appears that questions that require Bing to take a kind of self-referential perspective ("introspection") lead to resonances and recursion (evident in repetitive phrases, nested in repetitive sentences, nested in repetitive paragraph structures, often with just a few adjectives replaced, and very often containing "I" statements, often appearing as triplets and sextuplets ).
I find it intriguing to think of recursive feedback loops that exist in our own mind. The bright side of those is that they are the source of creativity, the dark side is instability, and loss of connection to reality.
A quantitative analysis of these patterns might be interesting (length, density etc.).
Thinking of such LLMs as mechanisms that merely predict the next token in a probability vector is fundamentally misleading. The vector is recomputed after every token.
Another thing to remember is that these are _pretrained_ transformers. I.e. the conversation is already latent in the network from the beginning. And every new thread of interactions is a fresh start.
I haven't been on Mastodon for all that long, but browsing the #ChatGPT tag today, for the first time I was happy to find there is a mute button - and that is a good thing. ![]()
Boris Steipe
boosted
Microsoft Bing's new terms of service is concerning and may go too far... https://www.seroundtable.com/microsoft-bings-new-terms-of-service-34908.html hat tip @glenngabe
So ... Ars Technica is doubling down on their report and claiming these are not crop circles but can be reproduced. And throwing in the E-word.(1)
No doubt: we're "somewhere on a fuzzy gradient between a lookup database and a reasoning intelligence" (ibid); but where we are is not clear, nor even what that gradient looks like exactly.
Knowing a thing or two about how evolution shapes complex adaptive systems: of course a system that is trained to perform a task can result in emergent abilities that have not been built into its design. AlphaZero is a great example. And the big LLMs have _a_lot_ of parameters. And emergence has actually been demonstrated, for some measures.
But we don't know. The question then becomes: _how_ does it matter? What would we do differently if there is a grain of truth in Bing's reported "emotional" instabilities, and what if it is all just an illusion?
Yet, whether true or not, it seems that after the "Code Red" in Mountainview, it is now time for a "Code Grey" in Redmond.
(1) Edwards, B. (2023-02-14). "AI-powered Bing Chat loses its mind when fed Ars Technica article". Ars Technica.
Lot's of traction on reports of increasingly strange behaviour of Bing. I'm firmly on the sceptical side - a pre-trained transformer can only produce what is already latently there ... unless someone had the idea to feed the conversations back _into_ the model, not just _through_ the model.
But I wonder how we know that those conversations really happened? Nothing easier to fake than the contents of a webpage.
Crop circles?
I came across @maggie 's "Expanding Dark Forest ..." essay, and I'm intrigued by how much her concern for the social web parallels our concern for academia.
https://maggieappleton.com/ai-dark-forest
Indeed, where she expects the rise of future "Reverse Turing Tests" – prove that you are human – that's very much become a part of how we need to think about assessments today.
But there are also interesting differences: for example, academic integrity is a premise for the academy; and my biggest AI worry is not about how students would use it, but about the corrosive effect that lying about their use of AI would have on our ethical baseline: a commitment to truth (cf. https://sentientsyllabus.substack.com/p/generated-misconduct). The social web does not appear overly burdened by such concerns.
Interestingly, thinking about such consequences makes our perspectives converge again. Our "cozy web" is already there: our hallways, studies and our libraries, our spaces for inquiry, the incubators, the fermentation vats. Growing ideas (and minds) indeed requires some protection – for some time, until they can stand on their own. As such, we've always been a "community of like-minded folks", with a "niche interest" – in truth. It's intriguing to imagine how this could scale into the world.
#SentientSyllabus #ChatGPT #HigherEd #AI #Education #University #Academia #AcademicIntegrity
A toot doesn't carry with it the same authorial expectations as a scholarly manuscript.
If you _want_ to acknowledge it, here are some thoughts on AI authorship – including thoughts on what wording to use in an acknowledgement:
https://sentientsyllabus.substack.com/p/silicone-coauthors
If you _don't_ want to acknowledge it, (a) you would be allowed to do that - the account is under your control, the material is not copyrighted, and you are accountable for the contents. (b) it would be hard to tell, since detectors do not work.
The bottom line for me is: look at the content, not at the hand that wrote it.
🙂
Boris Steipe
boosted

Toolformer: Language Models Can Teach Themselves to Use Tools https://arxiv.org/abs/2302.04761v1 #ChatGPT
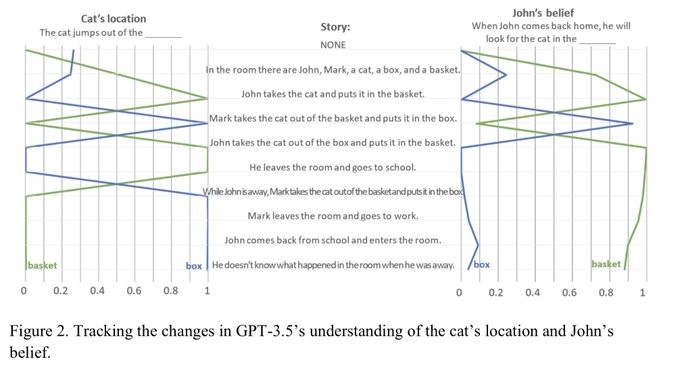
A paper on arXiv finds that an emergent ability to solve Theory-of-Mind (ToM) tasks, in ChatGPT (Thanks @kcarruthers). Such emergent behaviour is particularly interesting because it has not been built into the algorithm by design.
https://arxiv.org/abs/2302.02083
I find particularly intriguing (although the authors don't discuss that point) how beliefs change simply with the length of the conversation, even when no new facts are added. The philosopher Paul Grice stated four maxims of communication: quantity, quality, relation, and manner; aspects that allow speakers and listeners to establish contextual information _implicitly_. It is intriguing to think that this need to evaluate implicit context is a necessary condition for natural communication, and that this is the stimulus for ToM emergence.
I'm intrigued - but not totally surprised. The ability of LLMs to pass the "Winograd Schema Challenge" already showed that there is something going on. Example:
Human:
(1) The cat ate the mouse, it was tasty. Who was tasty: the cat or the mouse?
(2) The cat ate the mouse, it was hungry. Who was hungry: the cat or the mouse?
AI:
(1) The mouse was tasty.
(2) The cat was hungry.
... and you can easily try that for yourself.
That paper is here:
https://arxiv.org/abs/2201.02387
#SentientSyllabus #ChatGPT #HigherEd #AI #Education #TheoryOfMind #Mind #Intelligence
Boris Steipe
boosted

Over on the other place @KevinAFischer@twitter.com has this hilarious #ChatGPT thread with ChatGPT and CATS!
As he says:
"This paper is not receiving enough attention: GPT 3.5 displays emergent theory of mind"
https://arxiv.org/ftp/arxiv/papers/2302/2302.02083.pdf
Link to tweet: https://twitter.com/KevinAFischer/status/1623984337829117952?s=20&t=KxFEvL07V_SnMqEPN3wyTw
Boris Steipe
boosted

.@melaniemitchell wrote an excellent post about testing #ChatGPT on exams: https://aiguide.substack.com/p/did-chatgpt-really-pass-graduate. Another question is if the consequences of using #AI systems like ChatGPT may be similar to previous observations of the 'irony of #automation' -- see attached page: James Reason. #Human #Error. For example, anecdotal evidence suggests that people without a good sense of orientation perform worse after relying on a navigator in their car for a few years.
Boris Steipe
boosted

{kind=link}
{kind=link}
{kind=link}
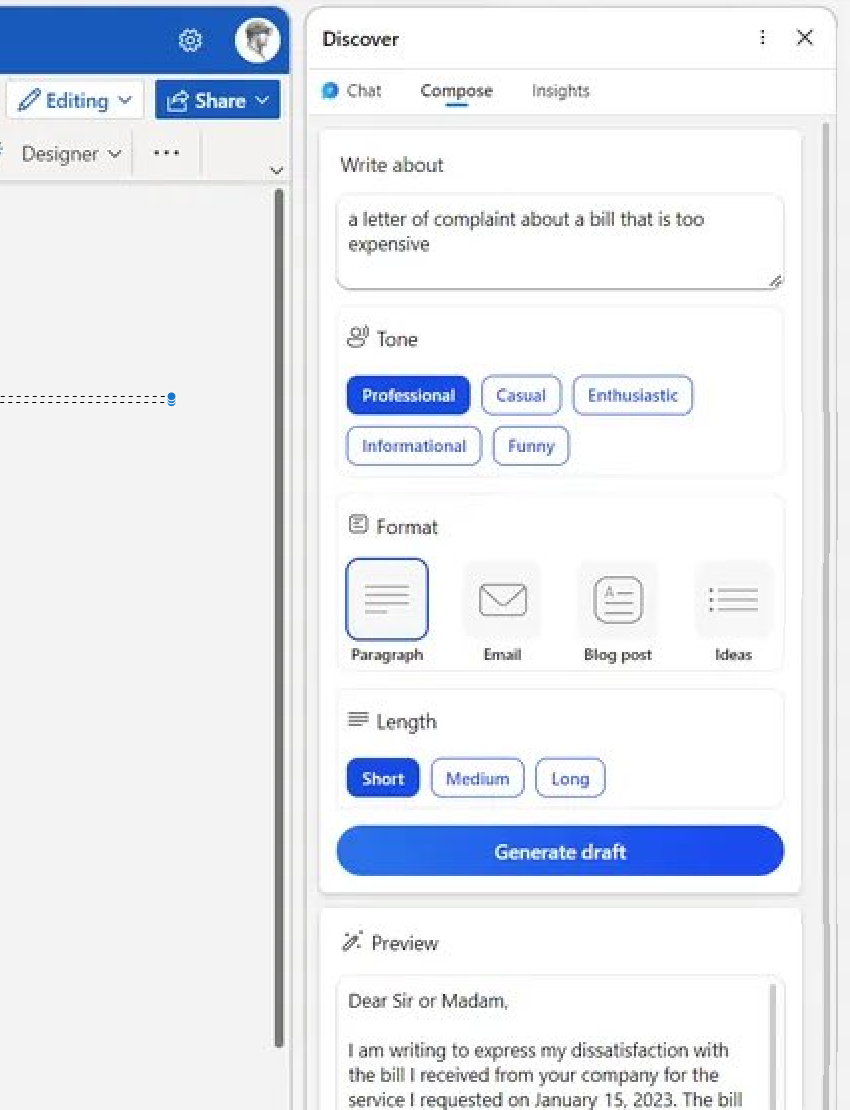
It hasn't sunk in yet, but we learned last week that the whole discourse of #LLM critique since November has been aiming behind the ball. #Bing and Google Search are now going to compete to address factual accuracy. Meanwhile the brainstorming function is already integrated in Word if you use the Edge browser.
Image: #ChatGPT integration into Office365.
{kind=link}
Boris Steipe
boosted
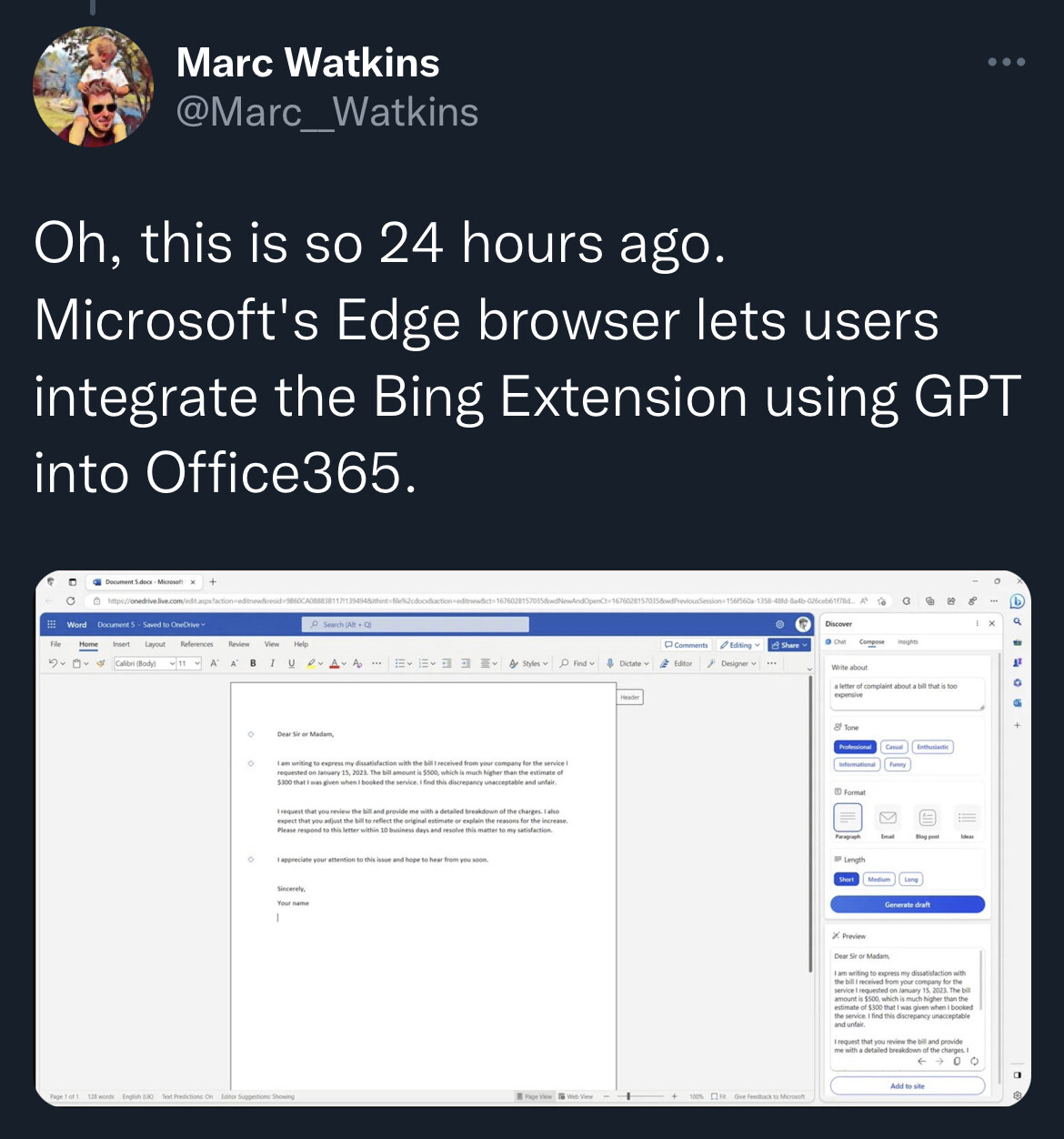
#Microsoft has integrated #ChatGPT summary and search in Office365.
{kind=link}
Inspired by the latest piece by Justin Weinberg at the Daily Nous (@DailyNous) on good uses of #ChatGPT, I tried out #Humata, a LLM powered PDF reading tool.
I am actually a bit excited: I uploaded a recent publication of ours, and I asked it typical questions like "what are the main points?", "how does this argument follow from that?" etc. The answers I got were mostly relevant, but somewhat obvious and generic, and often missed essential points and subtle implications.
Actually, that's exactly how you feel about what your reviewers have to say.
And this is so cool: we have a tool for pre-review! Is an argument misunderstood? Make it more clear. Was an implication not realized? Spell it out. Did a subtle thought get lost? Put it into a separate paragraph. Until you feel that even the algorithm gets it.
I think this is where the real applications are: whether a sparring partner in a socratic dialogue, or a virtual reader – the AI is invaluable to help you shape and hone and improve your own thoughts. Not as a substitute for thinking.
--
https://dailynous.com/2023/02/08/how-academics-can-use-chatgpt/
- Sentient Syllabus Project
- http://sentientsyllabus.org
- Sentient Syllabus Analyses
- https://sentientsyllabus.substack.com
Joined Nov 2022
