

Nick has moved to Mathstodon @internic@qoto.org
- Pronouns
- he/him/his
Moved to Mathstodon.xyz
Theoretical physicist by training (PhD in quantum open systems/quantum information), University lecturer for a bit, and currently paying the bills as an engineer working in optical communication (implementation) and quantum communication (concepts), though still pursuing a little science on the side. I'm interested in physics and math, of course, but I enjoy learning about really any area of science, philosophy, and many other academic areas as well. My biggest other interest is hiking and generally being out in nature.
Joined Nov 2022
Pinned post
I guess it's time for a #introduction. I'm a theoretical physicist by training (PhD in quantum open systems/quantum information) and currently paying the bills as an engineer working in free-space optical communication (implementation) and quantum communication (concepts). I'm interested in physics and math, of course, but I enjoy learning about really any area of science, philosophy, and many other academic areas as well. My biggest other interest is hiking and generally enjoying nature.
I'm definitely interested in following #ScienceMastodon, but I'm also just curious to see the mix of interesting photos and thoughts on myriad topics that may show up here.
I'm sort of part of the #TwitterMigration, but I honestly haven't used the bird site all that much in recent times, and as a FOSS/Linux geek I've been interested in federated services like Mastodon for quite a while.
Nick has moved to Mathstodon
boosted

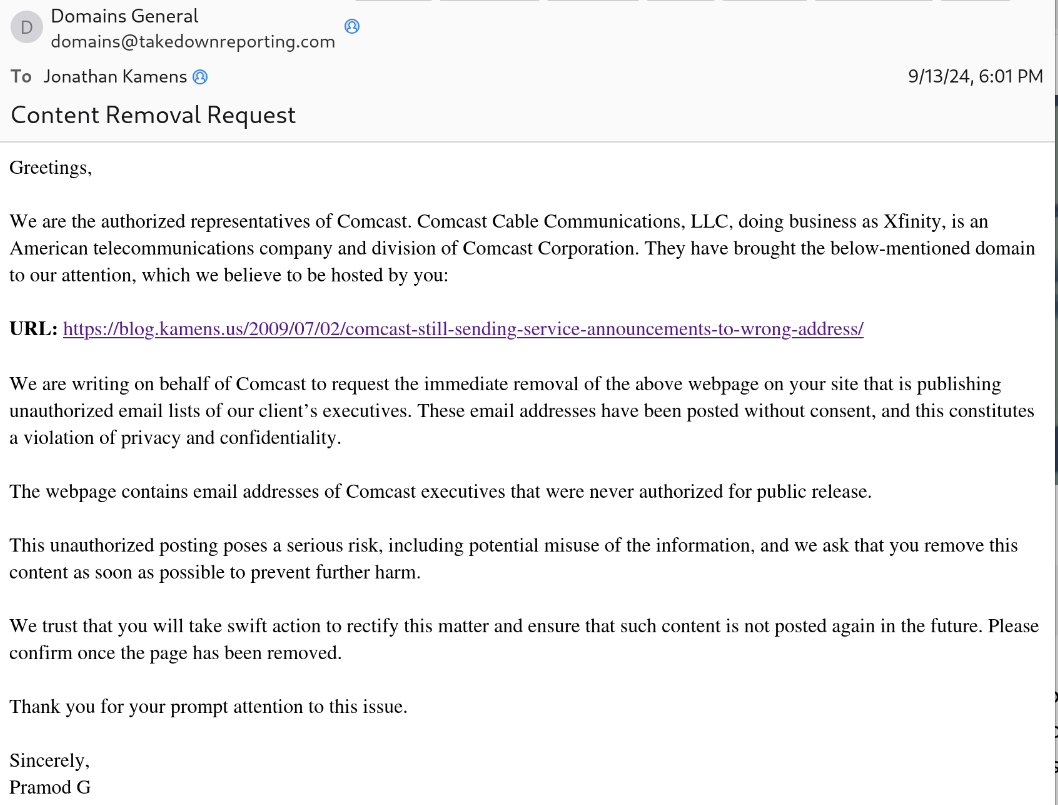
I complained to Comcast about something via email in 2009. I posted that email on my blog: https://blog.kamens.us/2009/07/02/comcast-still-sending-service-announcements-to-wrong-address/. At the time, I searched for the email addresses of Comcast executives and included them all on the email.
Last night I received email from someone claiming to represent Comcast, trying to bully me into taking down the blog posting.
I responded: "lol no"
Feel free to boost this post for the #StreisandEffect.
#smdh #gtfo #Comcast
Nick has moved to Mathstodon
boosted

Reminder for those using the iOS Patreon app to support their creators: Apple is now taking a 30% cut for new donations through the app, plus whatever Patreon takes. Consider alternate donation methods (including direct to the Patreon website rather than the Apple mobile app).
I’ve found, btw, that ko-fi has the best deal for creators - for a $72 annual fee, they do not take any cut of donations.
Nick has moved to Mathstodon
boosted
Also, a reminder that running your favorite fediverse services is not free and most are supported through donations. This is a time of high concern about corporate social media, so please if you can and they accept it, support your instances financially to ensure this place continues to thrive.
❤️
Nick has moved to Mathstodon
boosted

There’s a BAT in space!
Swift’s Burst Alert Telescope watches the sky for gamma-ray flashes. It even wears a mask (pictured) that creates a pattern of shadows to help pinpoint their locations. More: https://imagine.gsfc.nasa.gov/observatories/learning/swift/mission/bat.html #Swift20
Nick has moved to Mathstodon
boosted
I’m curious. This place has a very vocal anti-capitalist community, anytime moneys come up people shout about donations. When it comes to consent and Trust & Safety I’ve seen many people attack devs. Yet, when #Mastodon was asking for donations to fund a position it was largely crickets. #IFTAS has done great work and set out to be a great benefit to the #fediverse and #OpenSocialWeb yet they’re struggling to keep the lights on. How can that be? So many of you are always talking about donations so why are projects underfunded and servers shutting down due to lack of funding? Where are you passionate and vocal lot? https://wedistribute.org/2025/02/iftas-funding-crisis/ https://about.iftas.org/
Nick has moved to Mathstodon
boosted

Scientists unlock vital clue to strange quirk of static electricity
Formation of a triboelectric series depends on the number of contacts over time between materials.
https://arstechnica.com/science/2025/02/scientists-unlock-vital-clue-to-strange-quirk-of-static-electricity/?utm_brand=arstechnica&utm_social-type=owned&utm_source=mastodon&utm_medium=social
Nick has moved to Mathstodon
boosted

The Google Threat Intelligence Group (GTIG) says it has observed increasing efforts from several Russia state-aligned threat actors to compromise Signal Messenger accounts used by individuals of interest to Russia's intelligence services.
"The most novel and widely used technique underpinning Russian-aligned attempts to compromise Signal accounts is the abuse of the app's legitimate "linked devices" feature that enables Signal to be used on multiple devices concurrently. Because linking an additional device typically requires scanning a quick-response (QR) code, threat actors have resorted to crafting malicious QR codes that, when scanned, will link a victim's account to an actor-controlled Signal instance. If successful, future messages will be delivered synchronously to both the victim and the threat actor in real-time, providing a persistent means to eavesdrop on the victim's secure conversations without the need for full-device compromise."
"In remote phishing operations observed to date, malicious QR codes have frequently been masked as legitimate Signal resources, such as group invites, security alerts, or as legitimate device pairing instructions from the Signal website."
"In more tailored remote phishing operations, malicious device-linking QR codes have been embedded in phishing pages crafted to appear as specialized applications used by the Ukrainian military."
"Beyond remote phishing and malware delivery operations, we have also seen malicious QR codes being used in close-access operations. APT44 (aka Sandworm or Seashell Blizzard, a threat actor attributed by multiple governments to the Main Centre for Special Technologies (GTsST) within Main Directorate of the General Staff of the Armed Forces of the Russian Federation (GU), known commonly as the GRU) has worked to enable forward-deployed Russian military forces to link Signal accounts on devices captured on the battlefield back to actor-controlled infrastructure for follow-on exploitation."
Google says Signal, in collaboration with GTIG, has released updates for Android and iOS to mitigate these attacks. Users should update their apps immediately.
https://cloud.google.com/blog/topics/threat-intelligence/russia-targeting-signal-messenger
Nick has moved to Mathstodon
boosted

Hey! A step toward topological quantum computing - a way to compute that uses unusual properties of particles confined to wires or thin films.
Microsoft's press release is mainly about future plans, and the headline is pure hype, but their paper in Nature says what they've actually done.
They've created superconducting wires that contain 'Majorana zero modes', and figured out how to detect whether a wire has an even or odd number of these in it.
So what the hell are Majorana zero modes?
First, a Majorana particle is a spin-1/2 particle that is its own antiparticle. There are probably no fundamental particles like this in nature, though there's a chance neutrinos are Majorana particles. But we can create all sorts of 'quasiparticles' in cleverly designed materials. These are ways for atoms and electrons to wiggle that *act* like particles. And we can create Majorana quasiparticles in superconducting wires.
But what's a zero mode?
When a long thin spring vibrates up and down it can have 0, 1, 2, 3, ... wiggles in it. When it has 0, the whole spring is moving up and down in unison. That's a zero mode. In quantum mechanics, particles are waves, and wave that's a Majorana quasiparticle in a superconducting wire can be in a zero mode like this. So it's spread out through the whole length of the wire!
In short, this is pretty futuristic technology, and I really like the physics. Whether Microsoft can carry out their next steps and turn this into a useful computer, I have no idea. They claim they can do it in a few years, "not decades". 🤔
(1/3)
Nick has moved to Mathstodon
boosted
“Truly a middle finger”: Humane bricking $700 AI Pins with limited refunds
Humane's showing how not to treat early adopters.
https://arstechnica.com/gadgets/2025/02/truly-a-middle-finger-humane-bricking-700-ai-pins-with-limited-refunds/?utm_brand=arstechnica&utm_social-type=owned&utm_source=mastodon&utm_medium=social
Nick has moved to Mathstodon
boosted

Honestly, nothing beats Mastodon.
Nick has moved to Mathstodon
boosted

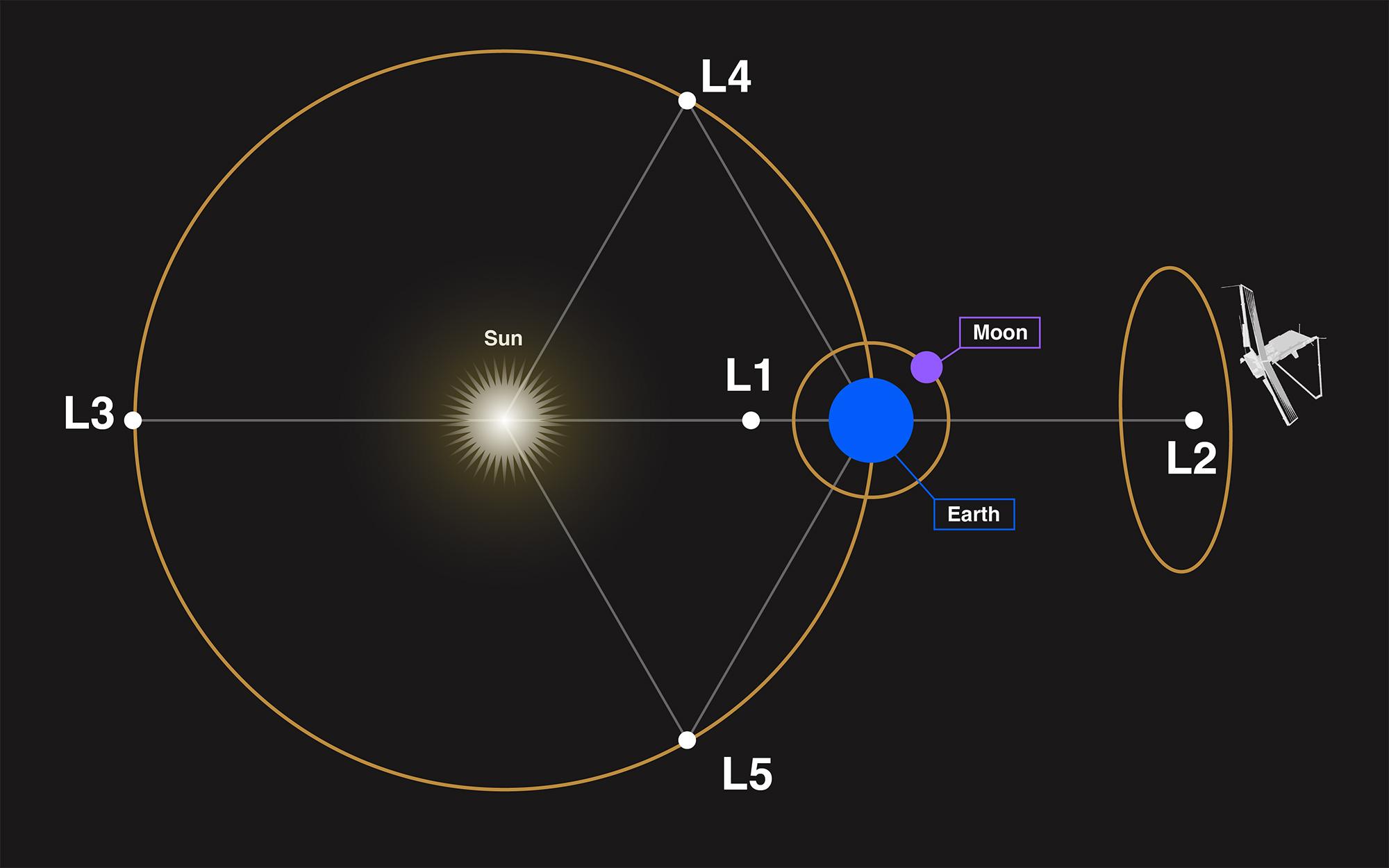
#NASAWebb orbits the Sun near Sun-Earth Lagrange point 2 (L2), approximately 1.5 million kilometers (1 million miles) from Earth. This makes it possible for Webb to remain in constant communication with Earth. Learn more about L2: https://webbtelescope.pub/3BY6H1x
Nick has moved to Mathstodon
boosted
If you want to learn how Chinese phishing or "smishing" groups are turning phished card data into mobile wallets, check out today's story. The innovation coming out of these groups is remarkable, and includes mobile apps that let thieves relay "ghost tap" NFC transactions to a payment terminal from halfway around the world.
What I find most remarkable is how millions of businesses have spent years and billions of dollars upgrading payment terminals to use more secure chip-based cards. And now these phishers come along and just bypass all of that, creating Apple and Google mobile wallets with the phished card data and a one-time code.
Here's the lede:
Carding — the underground business of stealing, selling and swiping stolen payment card data — has long been the dominion of Russia-based hackers. Happily, the broad deployment of more secure chip-based payment cards in the United States has weakened the carding market. But a flurry of innovation from cybercrime groups in China is breathing new life into the carding industry, by turning phished card data into mobile wallets that can be used online and at main street stores.
https://krebsonsecurity.com/2025/02/how-phished-data-turns-into-apple-google-wallets/
Nick has moved to Mathstodon
boosted

When I was born we hadn't found planets orbiting other stars. Now we can measure their weather with incredible detail.
And WASP-121b, a hot gas giant orbiting a star 900 light-years away, has a fascinating multi-layered weather pattern, now unveiled in 3D with ESO's Very Large Telescope. You shouldn't vacation there, though: it's scorching hot and super windy!
More info: https://www.eso.org/public/news/eso2504/
Nick has moved to Mathstodon
boosted

Public service announcement: you can use an Overleaf project like a git repo (Menu > Sync > Git).
You'll miss out on all the comments others write in the sidebar, but you'll be able to pretend it's like the old days, write in emacs, compile locally, work offline, and stop yelling at the user interface.
Nick has moved to Mathstodon
boosted

Want to create a clean micro-blog out of your Mastodon posts on one topic?
Here is the code: https://github.com/FlorianMarquardt/MastodonOriginalPostsViewer
Please share if you think this is useful 🙂 !
I'm looking at migrating my account to #Mathstodon. One thing I'd like is the ability to follow people from a wide variety of different places, including Bluesky (via brid.gy) and Threads, if possible. I know that the former is possible on Mathstodon, but I'm trying to figure out if the latter is. It seems like maybe not.
Nick has moved to Mathstodon
boosted

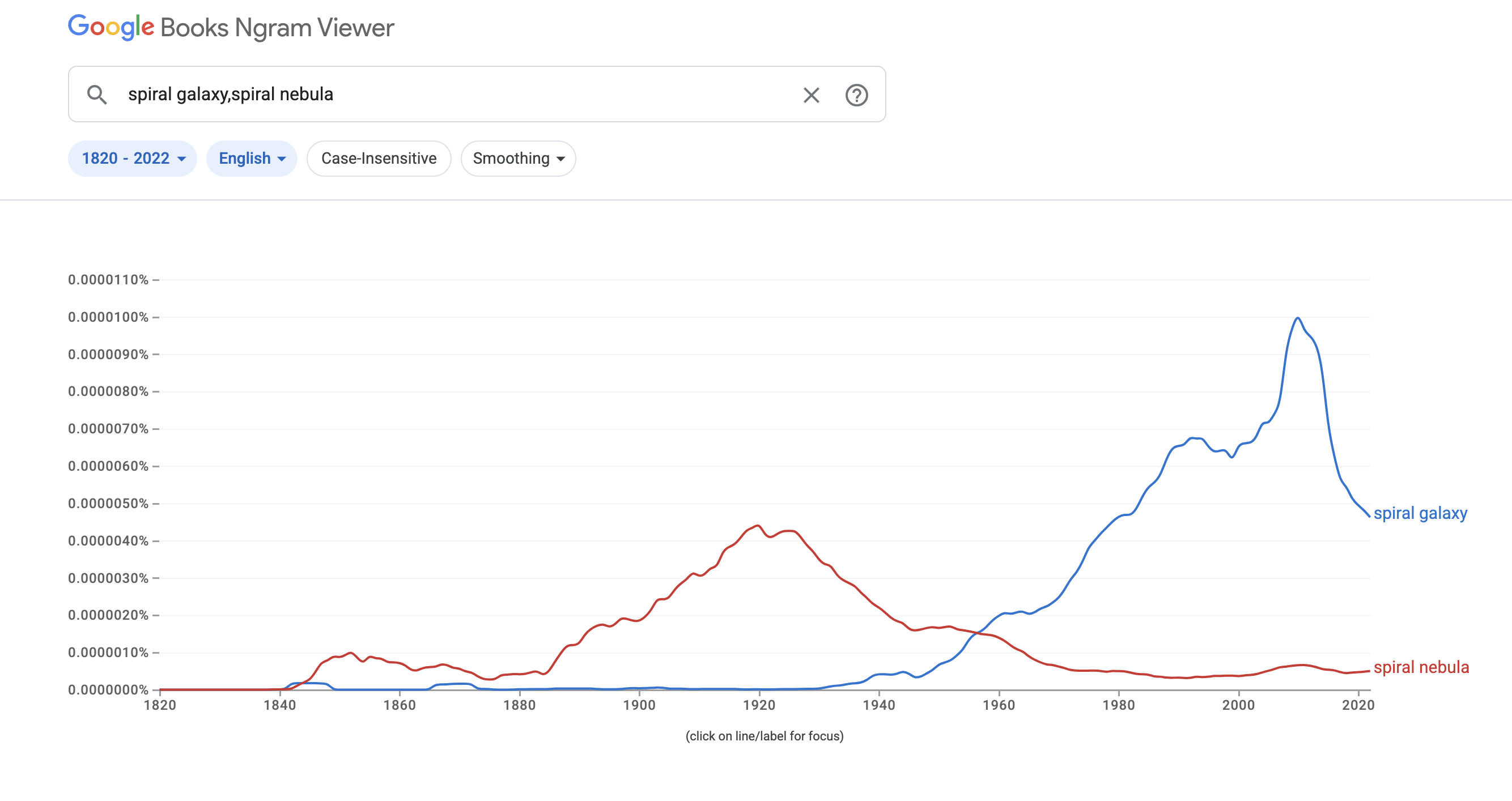
I've been reading some old astronomy papers (as one does on a Saturday night), and was surprised to come across the term "extragalactic nebula" to describe a galaxy in a paper written in 1941.
The famous "great debate" took place in 1920, with Harlow Shapley arguing that the "spiral nebulae" were within the Milky Way and Heber Curtis arguing that they were distant "island universes".
Edwin Hubble solved this debate once and for all in 1929, by measuring the distances to several spiral nebulae like Andromeda and Triangulum, and showing they were too far away to be within the Milky Way.
So then, why were astronomers still referring to these things as nebulae into the 1940s?
1/
Nick has moved to Mathstodon
boosted

Heh. "Curb the... incompetence... of HR", he says.
Oy... have I got a story for you!
I am a scientist, now retired. I worked in cancer research at a big pharma, mostly doing applied math & statistics, with the occasional bit of machine learning. (Physicist by training, it says here on my PhD.)
About 2010, we wanted to hire some next-gen sequencing people to run a new part of our lab. We duly wrote the req, and submitted it to HR for a candidate search.
HR *rewrote* the req, introducing numerous technical errors which would be off-putting to any qualified applicant.
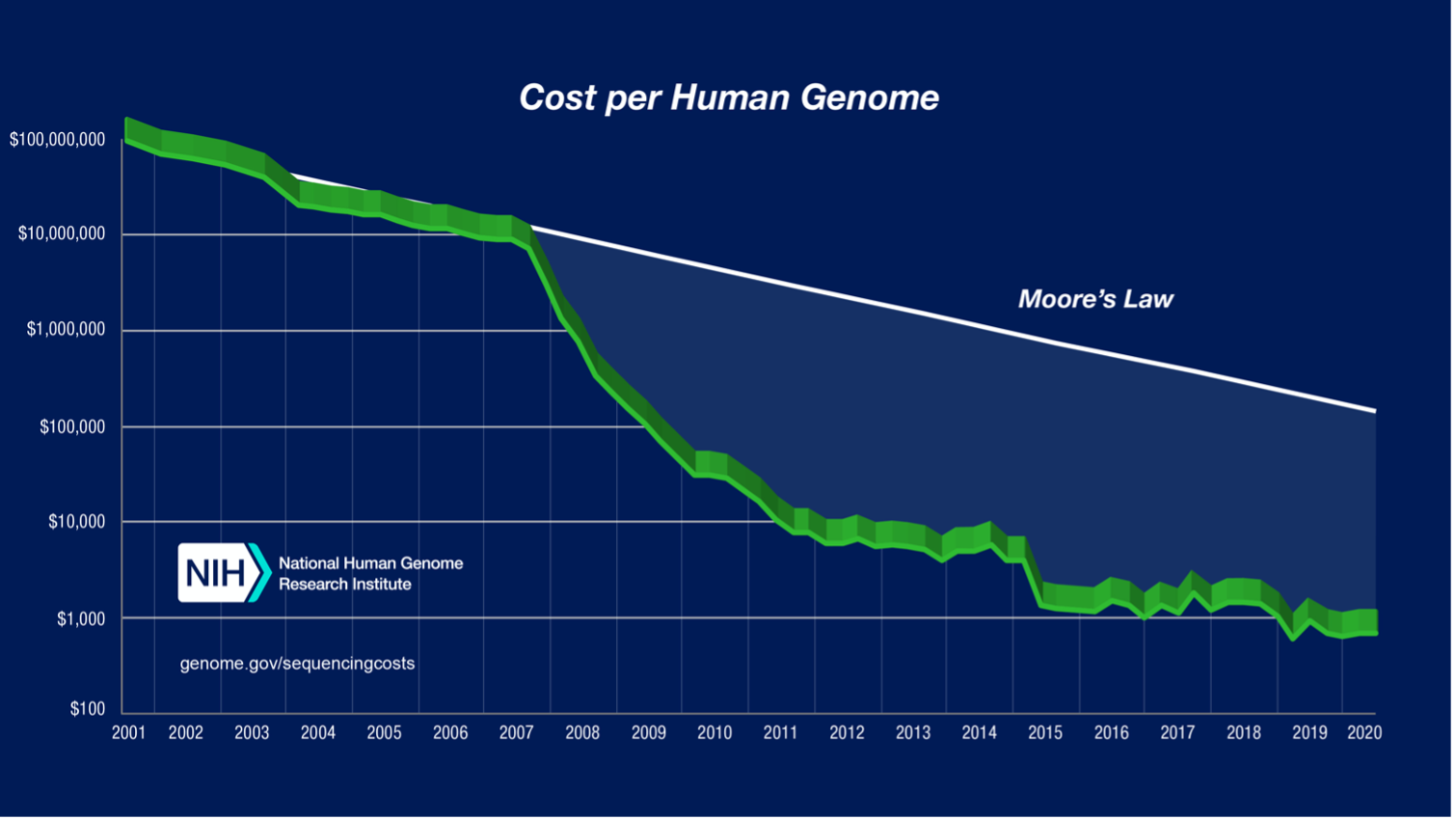
More interestingly, they added the requirement for TEN YEARS OF EXPERIENCE... for a technology which had been commercially available for less than 5 years or so. As evidence of that, see the plot below, and note the sharp drop in sequencing costs starting 2007-2008.
So unless you were intending to hire the NGS inventors themselves, there could not possibly be *any* candidates!
When confronted with this impossibility, they held their ground saying 10 years was the minimum experience they required for this senior position, and they could not make any exceptions. We would just have to wait for candidates to "age into the seniority required for the position."
Of course we ended up doing an end run around HR, hired a couple fabulous candidates, and (again, *of course*) got into trouble for it.
HR continued to say "scientists are remarkably uncooperative".
That part, at least, was accurate.
"Cooperation" would have been foolish.
I Mobley, "A brief history of Next Generation Sequencing (NGS)",
Front Line Genomics, 2021-Jul-26. Figure 1 is reproduced here.
https://frontlinegenomics.com/a-brief-history-of-next-generation-sequencing-ngs/
Nick has moved to Mathstodon
boosted

I had a very personal interview with @SecurityWeek magazine on my career and hopes for the future. https://www.securityweek.com/rising-tides-lesley-carhart-on-bridging-enterprise-security-and-ot-and-improving-the-human-condition/ thank you for giving me a voice.
Nick has moved to Mathstodon
boosted

Incredible reporting by @lorenzofb, who caught an Android spyware campaign in the wild. The spyware, dubbed "Spyrtacus," masquerades as popular apps like WhatsApp, but steals victims' phone data.
Researchers linked the spyware to Italian firm SIO.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Pronouns
- he/him/his
Moved to Mathstodon.xyz
Theoretical physicist by training (PhD in quantum open systems/quantum information), University lecturer for a bit, and currently paying the bills as an engineer working in optical communication (implementation) and quantum communication (concepts), though still pursuing a little science on the side. I'm interested in physics and math, of course, but I enjoy learning about really any area of science, philosophy, and many other academic areas as well. My biggest other interest is hiking and generally being out in nature.
Joined Nov 2022
