

Johannes Hoffart
boosted

#TheDataExchangePod 🎧 Michele Catasta of Replit explores the potential of #AI for software development. Find out how #LLMs & foundations models are helping developers code faster, better, and more efficiently.
#Nlproc #LLM #MachineLearning 🔗 https://thedataexchange.media/software-development-with-ai-and-llms/
Johannes Hoffart
boosted
#TheDataExchangePod 🎧 the amazing Jeff Jonas of Senzing explains how #BigData, #AI, & real-time processing redefine #EntityResolution and #MasterDataManagement. Learn valuable insights and leverage lessons in accuracy, scale, and complexity. Expand the scope of your AI applications and boost efficiency like never before!
#datascience #dataquality #datacentricai #machinelearning #ai
🔗 https://thedataexchange.media/using-data-and-ai-to-democratize-entity-resolution-and-master-data-management/
Johannes Hoffart
boosted

@SebRaschka finished his excellent free deep learning fundamentals course…highly recommended to watch: https://lightning.ai/pages/courses/deep-learning-fundamentals/unit-1/
Johannes Hoffart
boosted

It's been a another wild month in AI & Deep Learning research.
I curated and summarized noteworthy papers here:
https://magazine.sebastianraschka.com/p/ai-research-highlights-in-3-sentences-2a1/
Ranging from new optimizers for LLMs to new scaling laws for vision transformers.
Johannes Hoffart
boosted

Here are the slides for my #PyDataLondon keynote on LLMs from prototype to production ✨
Including:
◾ visions for NLP in the age of LLMS
◾ a case for LLM pragmatism
◾ solutions for structured data
◾ spaCy LLM + https://prodi.gy
https://speakerdeck.com/inesmontani/large-language-models-from-prototype-to-production
Johannes Hoffart
boosted
A new Ahead of AI issue is out, where I am covering the latest research highlights concerning LLM tuning and dataset efficiency:
https://magazine.sebastianraschka.com/p/ahead-of-ai-9-llm-tuning-and-dataset/
Johannes Hoffart
boosted
New Newsletter 📥 Get the inside scoop on GPT-4 & PaLM 2. Unpack the intricacies of these foundation models and understand the evolution of #LLMs
#NLproc #MachineLearning #DataScience
https://gradientflow.substack.com/p/what-you-need-to-know-about-gpt-4
Johannes Hoffart
boosted
#TheDataExchangePod: Are you looking for dependable, trustworthy #AI solutions for your company? 🏦🏥⚖️ Jonas Andrulis of Aleph Alpha explains what it takes to build/deploy reliable, source-cited responses, specializing in the legal, healthcare, and financial sectors.
https://thedataexchange.media/building-ai-for-enterprises/
Johannes Hoffart
boosted

New blog entry: Normalizing company names (and more) with SPARQL and Wikidata. As a service! https://www.bobdc.com/blog/wikidatanormalizing/
Podcast: Wie das Arbeiten mit SAP Software durch Künstliche Intelligenz beeinflusst wird
🎧 openSAP https://podcast.opensap.info/education-newscast/
🎧 Apple https://podcasts.apple.com/de/podcast/enc235-wie-das-arbeiten-mit-sap-software-durch-k%C3%BCnstliche/id1352307529?i=1000601764433
🎧 https://open.spotify.com/show/5hsuELMNmsySwkMeZDcC4d
#ai #ki
Johannes Hoffart
boosted

🎊🎁Big release of dirty-cat
https://dirty-cat.github.io/stable/
Broader focus: simplifying preparing non-curated dataframes for machine learning.
🔸Encoding of messy dataframes: a strong baseline for easy machine learning
🔸fuzzy_join: joining dataframes (pd.merge) despite typos
🔸Deduplication: matching categories with typos
🔸Feature augmentation: joining on an external data source to enrich tabular data
🔸Embedding of cites, companies, locations...
Johannes Hoffart
boosted
Tabular data can benefit from merging external sources of information.
The FeatureAugmenter is a sklearn transformer to augment a given dataframe by joins on reference tables.
https://dirty-cat.github.io/stable/generated/dirty_cat.FeatureAugmenter.html
fuzzy_join makes it robust to mismatch in vocabulary. Hyperparameter optimization can tune matches for prediction
For such external information,
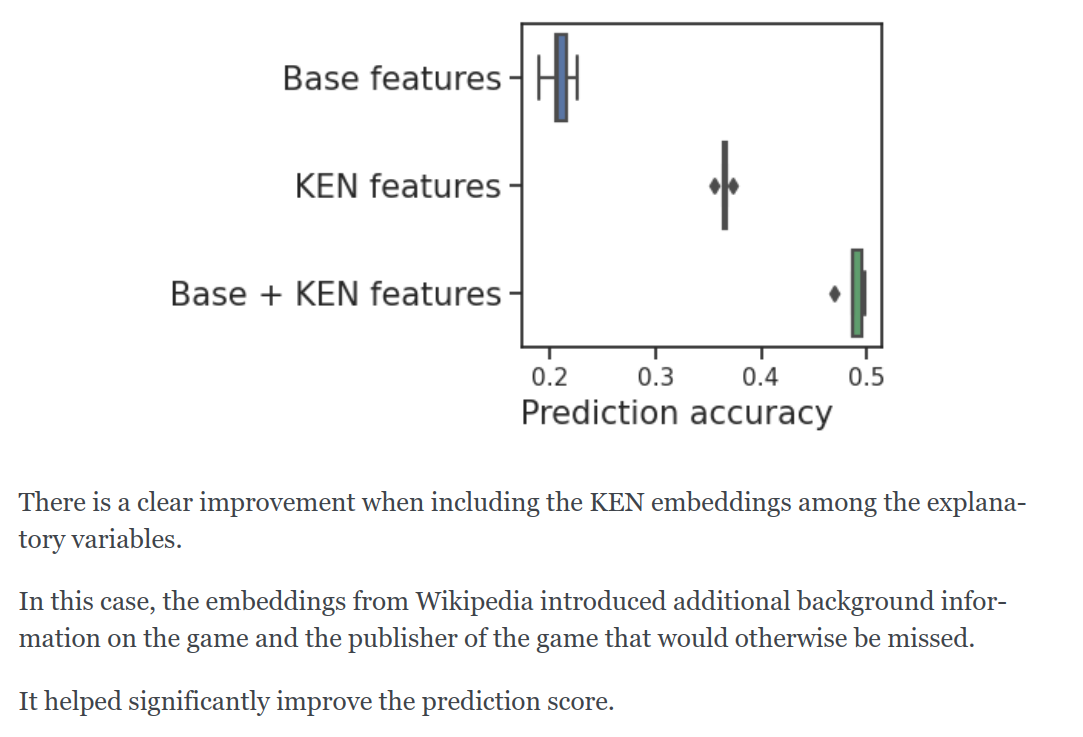
diry-cat can download embeddings of wikipedia data on millions of entities: companies, cities, geographic locations...
https://dirty-cat.github.io/stable/auto_examples/07_ken_embeddings_example.html
Johannes Hoffart
boosted
Productive weekend! Just added 4 new Q&A's!
- Multi-GPU Training Paradigms
- The Distributional Hypothesis
- "Self"-Attention
- Training & Test Set Discordance
And "Machine Learning Q and AI" just crossed the 50% milestone! 🎉
PS: I included the Multi-GPU Training Paradigms section is in the free preview at
https://leanpub.com/machine-learning-q-and-ai/
Johannes Hoffart
boosted

This Politico article argues that #NMT (Neural Machine Translation) was one of the major drivers of European unity against the Russian invasion of Ukraine.
Not sure I fully buy the argument, but MT is probably one of the best examples of #NLProc / #AI that benefits society / #AIforGood.
https://www.politico.com/news/magazine/2023/02/03/europe-putin-ukraine-google-translate-00079301
h/t @daanvanesch
Johannes Hoffart
boosted

CALL FOR PAPERS: Research and Innovation Track
We welcome papers on novel scientific research and/or innovations relevant to #SemanticWeb, #KnowledgeGraphs, #AI, #ML, #NLP and more
Deadlines:
🗓️Abstracts: May 09
🗓️Papers: May 16
For more info: 🌐https://2023-eu.semantics.cc/page/cfp_rev_rep
Johannes Hoffart
boosted

Machbarkeitsstudie: KI-Leuchtturmprojekt in Deutschland möglich
ChatGPT kommt aus den USA. KI-Experten in Deutschland sehen darin ein Problem und fordern einen Kraftakt zur Wahrung der digitalen Souveränität.
#Bundeswirtschaftsministerium #ChatGPT #Deutschland #Europa #KünstlicheIntelligenz #LEAM #Sprachmodelle #Supercomputer #USA #digitaleAssistenten
Johannes Hoffart
boosted
In eigener Sache: heise online zieht auf eigene Mastodon-Instanz
Das Chaos bei Twitter hält an und die Mastodon profitiert weiter. Heise Medien betreibt in dem Fediverse-Netzwerk nun eine eigene Instanz.
#Fediverse #Heise #Mastodon #SocialMedia #Twitter #TwitterÜbernahme #heiseonline
Johannes Hoffart
boosted

Do you love #selfhosting? What about providing service to the public via #Codeberg?
We are looking for maintainers that take on adding code search features to our #Forgejo instance to reduce the load on the existing infrastructure team and bring this project forward.
Please see https://codeberg.org/Codeberg/Community/issues/904 if you are interested.
We are looking forward to your contributions. Thank you a lot!
Johannes Hoffart
boosted

The most interesting thing about #ChatGPT that no one is talking about is how the future will be systems talking to each other with imprecise protocols but they’re still able to understand
Johannes Hoffart
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
And the year has barely started!
RT @MishaLaskin@twitter.com
In-context RL at scale. After online pre-training, the agent solves new tasks entirely in-context like an LLM and works in a complex domain. One of the most interesting RL results of the year. https://twitter.com/FeryalMP/status/1616035293064462338
🐦🔗: https://twitter.com/MishaLaskin/status/1616066421582176258
- Website
- https://www.hoffart.ai
Joined Sep 2019
