

Johannes Hoffart
boosted

RT @ResearchGermany@twitter.com
📣 The @TIBHannover@twitter.com is looking to employ a data steward / data scientist (m/f/d) to join the Data Science & Digital Libraries Research Group 👉 http://ow.ly/7Tn850LElGs #ComputerScience #InformationScience #DataScience
🐦🔗: https://twitter.com/ResearchGermany/status/1592829875337191430
Johannes Hoffart
boosted

Please add missing #Mastodon accounts of organisations, projects and persons to #Wikidata with the property P4033 (and a start date).
You can see all entries with this query
https://w.wiki/kV7
and you will find interesting accounts there.
Now we have 3323, let's go!
Thanks for your #retoot.
Johannes Hoffart
boosted

Johannes Hoffart
boosted

A book review by @suzan of
Pretrained Transformers for Text Ranking: BERT and Beyond by Jimmy Lin, Rodrigo Nogueira, and Andrew Yates
"This textbook
could be the ideal cross-over from IR knowledge to the NLP field, using our common
friend BERT as the bridge."
Johannes Hoffart
boosted

In case you haven't heard, at Hugging Face we are building wikipedia-like crowdsource documentation on machine learning tasks 📚 Every page has simply put information on implementing machine learning tasks and building your first proof-of-concept without diving deep into nitty gritty of maths of machine learning 🤩 https://huggingface.co/tasks
Johannes Hoffart
boosted

I am currently teamlead and part of the CTO Team at inovex in Karlsruhe, Germany. We are an IT services company, with a innovation and research focus.
Previously EML, Heidelberg and UKP Lab, TU Darmstadt
Interests: #nlproc, #ai, #appliedai, #recsys
More a curator, mentor, enabler - less a researcher. Also: Business Development, Sales, Marketing.
Johannes Hoffart
boosted

Fun fact: in addition to search for hashtags, you can go to a special sigmoid.social/tags/hashtag url to browse local posts with a given hashtags.
For instance:
https://sigmoid.social/tags/newpaper
We recommend Sigmoiders use #PaperThread , #NewPaper , #NLPProc, #CV , #RL , and other hashtags listed at https://sigmoid.social/about/more
Johannes Hoffart
boosted
RT @Raspberry_Pi@twitter.com
Don't be scared of Mastodon. If you were thinking of giving it a try, get started with this great explainer...
https://www.stuff.tv/features/what-is-mastodon-all-you-need-to-know-to-switch-from-twitter/
🐦🔗: https://twitter.com/Raspberry_Pi/status/1591027811233730563
Johannes Hoffart
boosted

@davidrevoy For those (like me) who are out of the loop: https://arstechnica.com/information-technology/2022/11/deviantart-upsets-artists-with-its-new-ai-art-generator-dreamup/.
TL;DR: DeviantArt created an art generator called DreamUp based on Stable Diffusion, and art uploaded by the site’s users will be used for training unless they opt out.
Johannes Hoffart
boosted

Great news #Fediverse it is Official. The #EU #EuropeanCommission just launched two servers 🚀
Welcome to #EUVoice mastodon and #EUVideo peertube 🎉
So say hi to @EC_Commission@social.network.europa.eu 👋
Stay in the loop with @EC_DIGIT ➿
Help make things fundamentally right with @FRA ☀️
Regain balance with @Curia ⚖️
Protect that data with @EDPS 🔐
Let's go global with @CDT 🌐
Get us heard at @ombudsman 📣
Watch and boost from: https://tube.network.europa.eu/videos/overview
And explore: https://social.network.europa.eu/explore
Johannes Hoffart
boosted

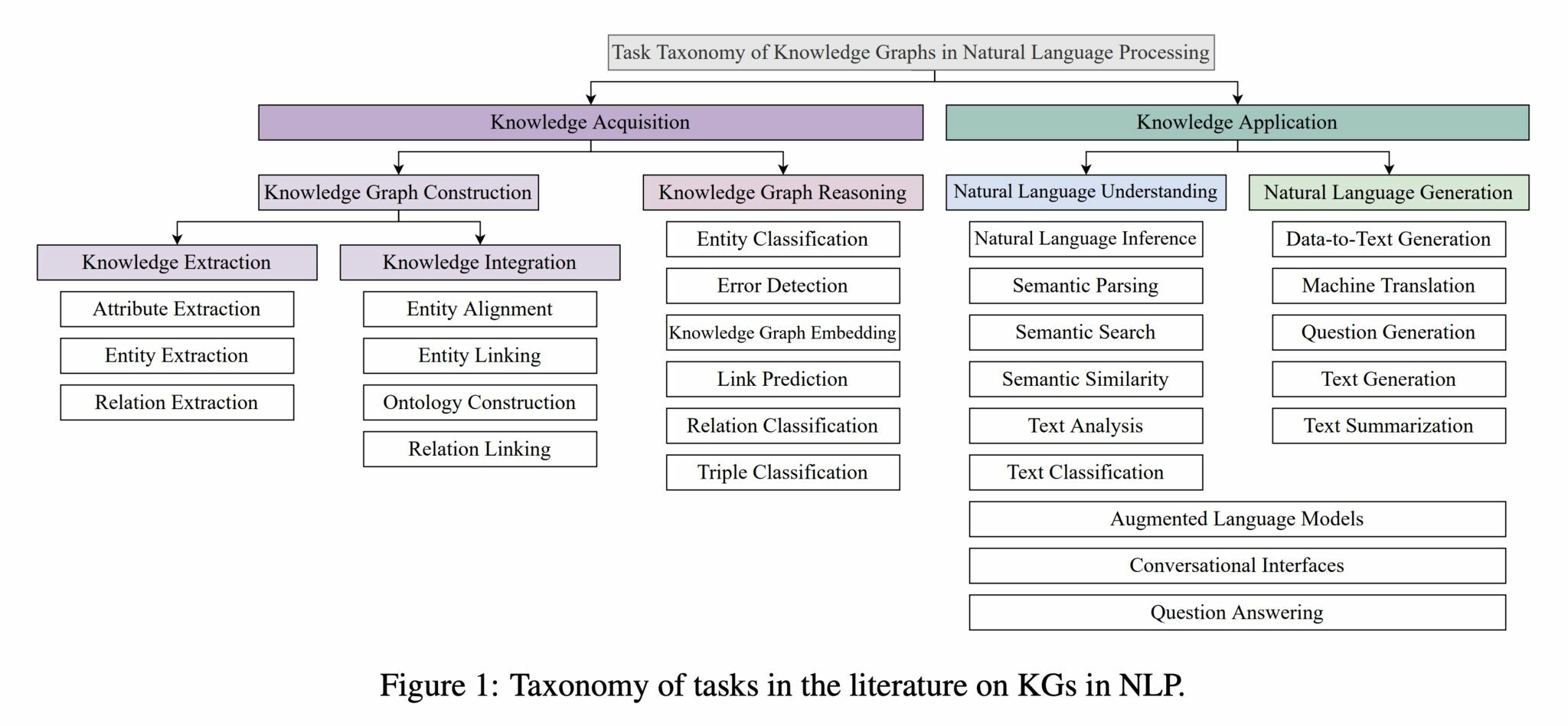
(1/6)
Summarizing this excellent systematic survey of 507 papers on the state of #KnowledgeGraph in #NLP since the first Internet-age #KG was announced 10 years ago:
Schneider et al. 2022. “A Decade of Knowledge Graphs in Natural Language Processing: A Survey.” https://arxiv.org/abs/2210.00105
1. Tasks surveyed are broadly divided into Knowledge Acquistion and Knowledge Application.
Johannes Hoffart
boosted

The first international workshop on Legal Information Retrieval will be held at ECIR 2023, in Dublin, on April 2nd, 2023 #ECIR2023 #LegalIR
The call for papers (actually extended abstracts) is now available on https://tmr.liacs.nl/legalIR/
Deadline: January 20th, 2023
Johannes Hoffart
boosted

We test models from @huggingface hub
rank them efficiently (linear probing on one task)
The best ones, we finetune on 36 different datasets and share with you here:
https://ibm.github.io/model-recycling/
Next time you finetune, just pick the best one
Why use a worse model?
#NLProc #nlp #MachineLearning #ml
Fixed link...
Johannes Hoffart
boosted

RT @MinqiJiang@twitter.com
SAMPLR allows adaptive curricula to focus more on difficult scenarios (e.g. “driving on ice”), without the final policies *overestimating* their probability. In other words, it robustifies agents to difficult settings, without making them overly conservative or optimistic.
🐦🔗: https://twitter.com/MinqiJiang/status/1590017031449235461
Johannes Hoffart
boosted
I don’t train from scratch, I use RoBERTa🧐
Wait…
Why not cross-encoder/stsb-roberta?facebook/muppet-roberta?
We automatically identify the best models on 🤗(periodically)
Just pick the best one
and finetune on your task
https://ibm.github.io/model-recycling/
#NLProc #MachineLearning #finetuning #intertraining #huggingFace #SoTA
Johannes Hoffart
boosted
SigmoidS has exceeded 2k registered users!
Keep the trend going by letting your friends/colleagues know about what a cool place this is becoming for AI folks :) We'll keep scaling up the server compute as needed as more users join.
Since some have asked: you can support us monetarily by subscribing on Substack - https://thegradientpub.substack.com/
We are considering setting up a separate Patreon just for Sigmoid Social, but for now feel free to help us out that way if you'd like :D
#introduction I have been researching and building foundations to link text to knowledge, constructing #knowledgegraphs like #YAGO, and bringing together unstructured and structured knowledge to power a variety of applications.
I am now working on pushing the boundaries of #businessAI as CTO for the AI unit at SAP.
I am very much hoping to keep track of the latest in #nlp #kg and #ml here, and will occasionally contribute my own view and works :)
Johannes Hoffart
boosted

#Introduction I am hoping to join a welcoming and diverse community here. What I liked about Twitter was the convos about ML, the new papers, ideas, and feeling connected to other researchers across the globe. Looking forward to rebuilding this on an open platform without the volatile billionaire bit.
I’m a professor of CS and will occasionally post something about geometric (graph) deep learning, attempts to bridge discrete and continuous learning, and applications in the sciences.
Johannes Hoffart
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Time for an #introduction:
I am a researcher at Google Brain 🧠 in Amsterdam 🚲, working primarily on structured approaches to ML/AI: graph representation learning / GNNs, structured / geometric scene representations & world models, object-centric learning & compositionality.
You probably won't see me toot/tweet very often, but when I do, it will mostly be about research that excites me and the occasional toot about car-free / livable cities.
Thank you, @thegradient for setting up this server!
- Website
- https://www.hoffart.ai
Joined Sep 2019
