

Johannes Hoffart
boosted

This article sheds light on the question of why machine learning products mostly do not get into production even though they are enjoying an ongoing boom. Additionally, it shows how MLOps can help to tackle these challenges in the machine learning life cycle.
https://www.inovex.de/de/blog/a-conceptual-view-on-the-machine-learning-life-cycle/ #ml #mlops
Johannes Hoffart
boosted

Controversial #machinelearning suggestions by Yann LeCun at #NeurIPS2022 Self-Supervised Learning workshop!
He suggests:
(1) abandoning generative AI architectures
(in favour of joint embedding ones)
(2) abandoning probabilistic models
(in favour of energy-based models)
(3) abandoning contrastive methods
(in favour of regularized methods)
(3) abandoning RL where possible
(in favour of model-predictive control)
Related talk:
http://youtu.be/VRzvpV9DZ8Y
Source: https://twitter.com/BeingMIAkashs/status/1599061227665514496
Johannes Hoffart
boosted

Monolith (from ByteDance, creator of TikTok) is an interesting system for online training that addresses two problems faced by modern recommenders: (1) Concept Drift - underlying distribution of the training data is non-stationary; ( 2) Features used by models are mostly sparse, categorical and dynamically changing. #recsys #MachineLearning
Johannes Hoffart
boosted

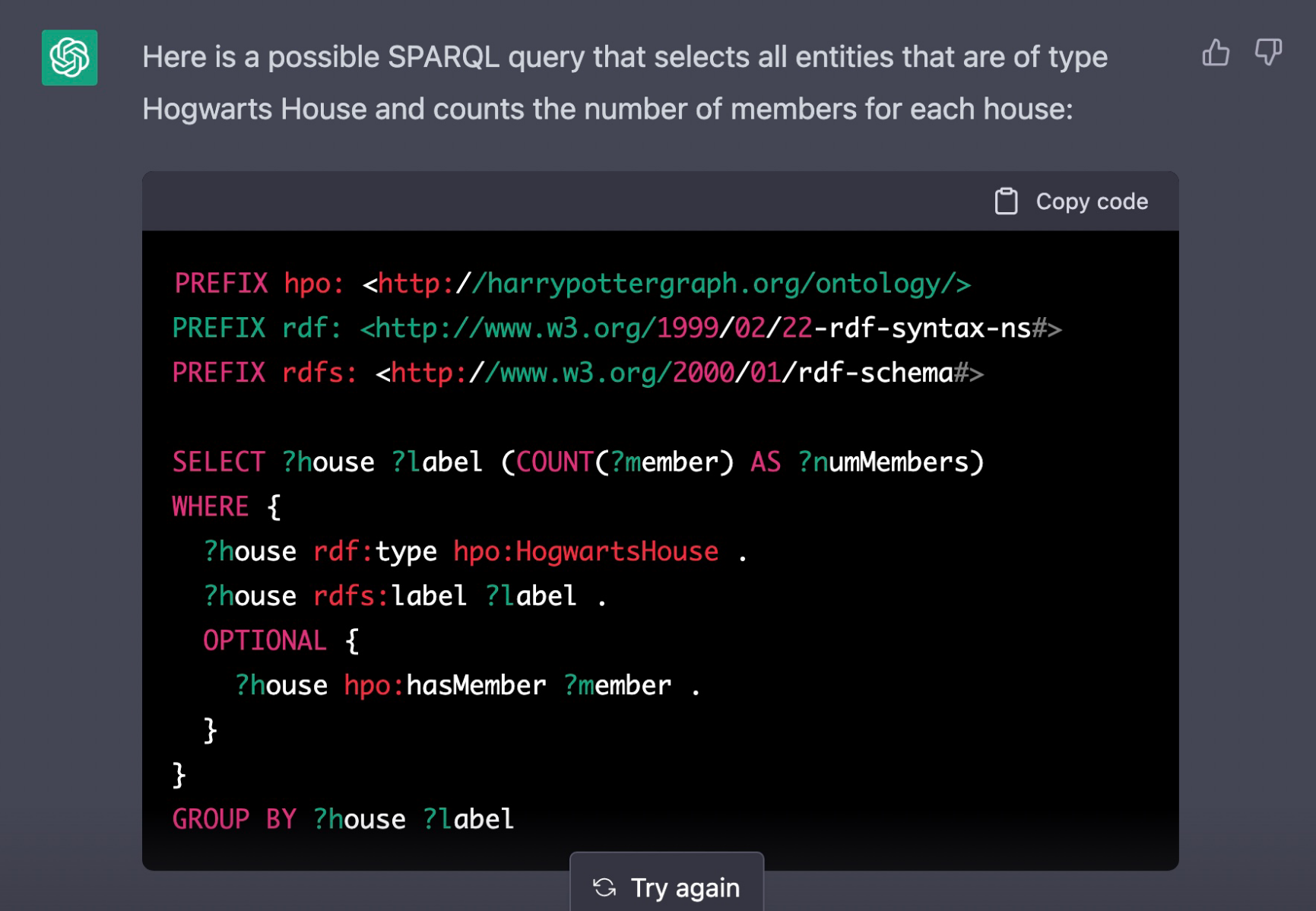
Like @timfinin I tried ChatGPT on last semester's final exam for my lecture "Information Service Engineering", with questions/tasks on Knowledge Graphs, basic NLP, and basic ML. It performed surprisingly well (for SPARQL it achieved 11 out of 12 points). Even for more complex questions like performing an evaluation or constructing an FSA, it performed not flawlessly, but not so bad. Overall, ChatGPT would have passed. Congratulations!
Johannes Hoffart
boosted

Here is a twitter thread on ways discovered to "jailbreak" #ChatGPT
1. Pretend to be evil
2. Remind it that it isn't supposed to disagree
3. Wrap it in code
4. Tell GPT to be in opposite mode
5. Convince GPT it is playing an earthlike game
6. Convince it to give examples of what LLMs shouldn't do
https://twitter.com/zswitten/status/1598380220943593472
Johannes Hoffart
boosted

We're starting a community slack for anybody interested in Neurosymbolic AI. (drivers include organizers of the annual workshop on the topic, and EiCs and EB members of the journal Neurosymbolic Artificial Intelligence that we're currently starting.
If you'd like to be on the slack, let me know (or anybody else who's already on it). You'll get an invite to your email then.
Johannes Hoffart
boosted

#Wikidata random #SPARQL query: Universities ordered by number of #Mastodon IDs of people who studied there. https://w.wiki/63XG
Johannes Hoffart
boosted

This is MASSIVE. The Windows Subsystem for Linux in the Microsoft Store is now generally available on Windows 10 and 11! Windows 10 users can now run Linux GUI apps natively! https://devblogs.microsoft.com/commandline/the-windows-subsystem-for-linux-in-the-microsoft-store-is-now-generally-available-on-windows-10-and-11/ #wsl #windows #linux
Johannes Hoffart
boosted

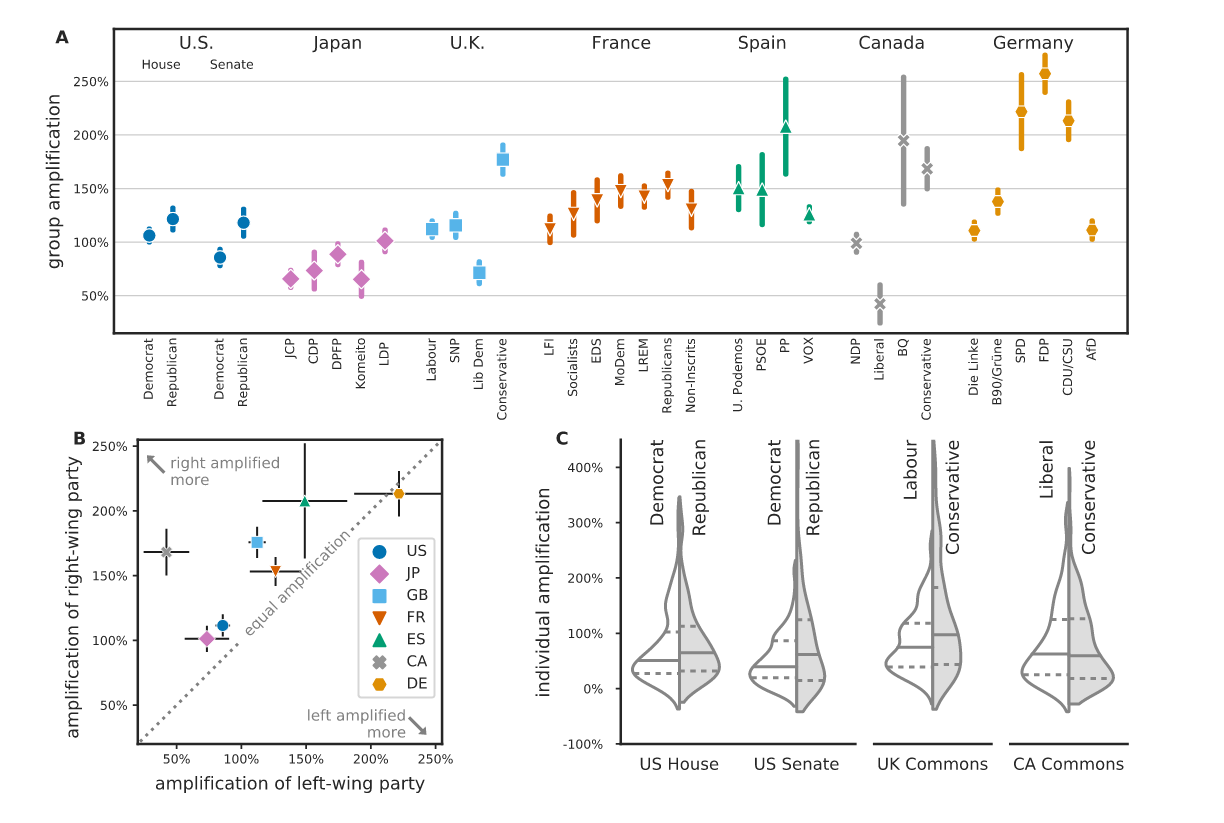
The full paper is here with this telling chart: https://cdn.cms-twdigitalassets.com/content/dam/blog-twitter/official/en_us/company/2021/rml/Algorithmic-Amplification-of-Politics-on-Twitter.pdf
The experimental setup is interesting : Twitter deliberately excluded 1% of its 2016 users from the algorithmic timeline. These users serve as a control group to measure the effect of the algorithm.
The results surprised the study's authors, who expected an increase in amplification at the extremes, both on the right and the left. However, only the right is amplified. This is further proof that political representation with a center and extremes does not reflect the structure of the field.
Johannes Hoffart
boosted

So, this concludes my 5 day #knowledgegraphs posts:
I see future in:
1. RDF+Surfaces for describing data policies
https://mastodon.social/@pietercolpaert/109338145801065320
2. Materializable hypermedia APIs
https://mastodon.social/@pietercolpaert/109341597091539820
3. The ideas behind #SolidProject to scale up your personal knowledge graph and cater for cross-app interoperability
https://mastodon.social/@pietercolpaert/109347111636771633
4. RML for KG generation
https://mastodon.social/@pietercolpaert/109352584574643533
5. Linked Data Event Streams for publishing
Johannes Hoffart
boosted

Stability AI has released #StableDiffusion 2.0. The #ml model is now up on #HuggingFace.
This model was trained on 768x768 images instead of 512x512.
The model and checkpoints are compatible with most 1.x software.
Johannes Hoffart
boosted

more incredible news of wounds in the surveillance economy. Alexa is extremely unprofitable.
https://arstechnica.com/gadgets/2022/11/amazon-alexa-is-a-colossal-failure-on-pace-to-lose-10-billion-this-year/
Johannes Hoffart
boosted
Curious to hear about your experiences with #SPARQLAnything and the integration/federation of legacy data. Please share if you tried out or know any working implementations.
Johannes Hoffart
boosted

@tdietterich If you'll forgive some self-promotion (and promotion of my close colleagues), we are finding LLMs to be useful at generating training data for more specialized models.
https://arxiv.org/abs/2210.02498
https://arxiv.org/abs/2209.11755
This can dramatically reduce the need for human-labeled data, making it possible to have customized models for all sorts of scenarios, domains, and tasks. And when properly constrained, the student model can even be more accurate than the LLM teacher.
Johannes Hoffart
boosted

Hi from #Wikidata ![]() 👋
👋
Johannes Hoffart
boosted

De-googlized smart phone ecosystem https://murena.com
OSS software and online services https://framasoft.org
Self-Hosting distro https://yunohost.org
Johannes Hoffart
boosted

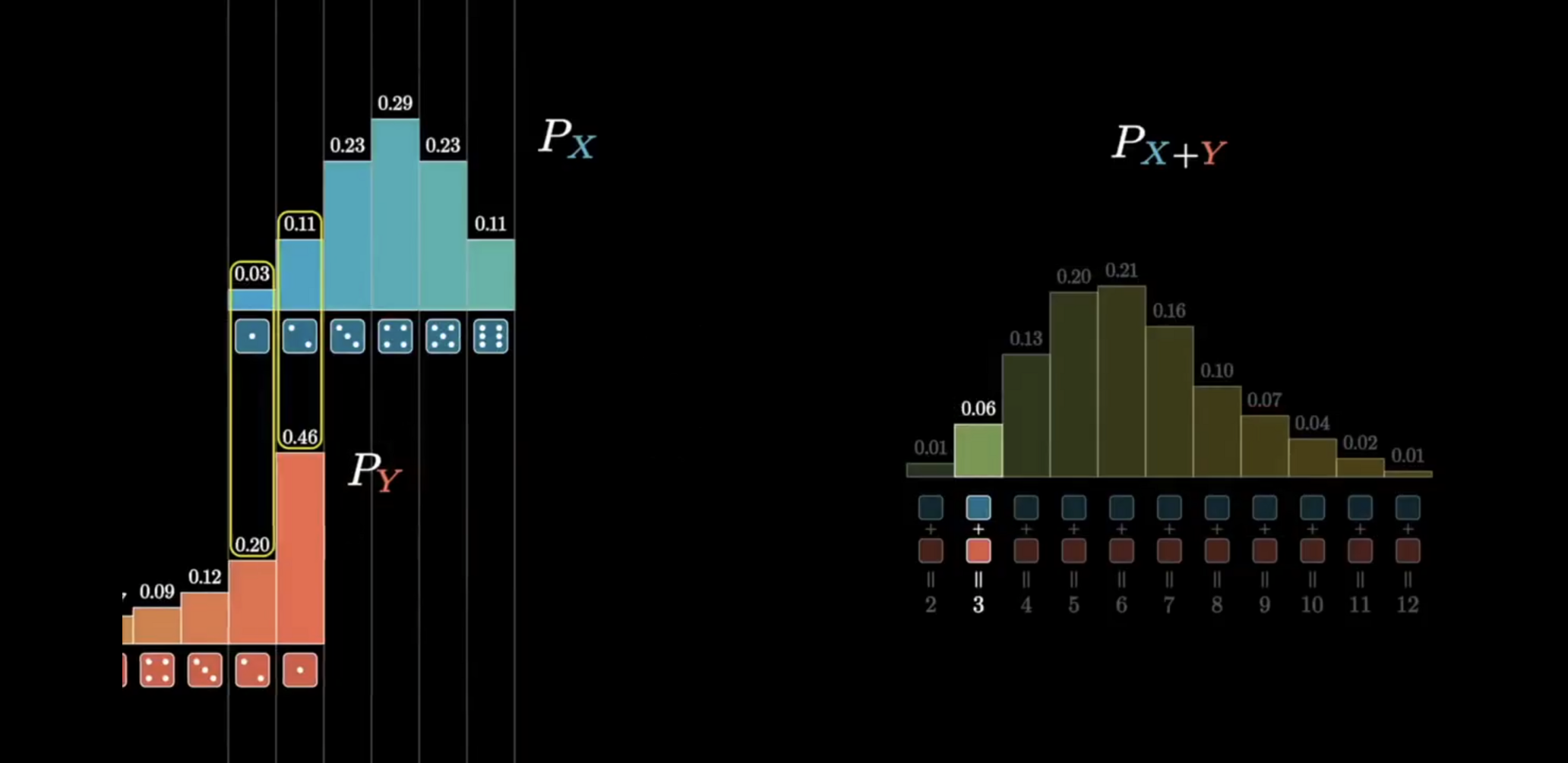
Omg omg omg there's a new #3blue1brown video and it's about convolutions and it is beautiful ✨✨✨ https://youtu.be/KuXjwB4LzSA
#MachineLearning #ExplainableAI #Education #AI #XAI #ArtificialIntelligence #NeuralNetworks #CNNs #ComputerScience #learning
Johannes Hoffart
boosted

We curated and analysed thousands of benchmarks -- to better understand the (mis)measurement of AI! 📏🤖🔬
We cover all of #NLProc and #ComputerVision.
Now live at Nature Communications: https://nature.com/articles/s41467-022-34591-0
Johannes Hoffart
boosted

RT @ResearchGermany@twitter.com
📣 The @TIBHannover@twitter.com is looking to employ a data steward / data scientist (m/f/d) to join the Data Science & Digital Libraries Research Group 👉 http://ow.ly/7Tn850LElGs #ComputerScience #InformationScience #DataScience
🐦🔗: https://twitter.com/ResearchGermany/status/1592829875337191430
Johannes Hoffart
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Please add missing #Mastodon accounts of organisations, projects and persons to #Wikidata with the property P4033 (and a start date).
You can see all entries with this query
https://w.wiki/kV7
and you will find interesting accounts there.
Now we have 3323, let's go!
Thanks for your #retoot.
- Website
- https://www.hoffart.ai
Joined Sep 2019
