

Podcast: Wie das Arbeiten mit SAP Software durch Künstliche Intelligenz beeinflusst wird
🎧 openSAP https://podcast.opensap.info/education-newscast/
🎧 Apple https://podcasts.apple.com/de/podcast/enc235-wie-das-arbeiten-mit-sap-software-durch-k%C3%BCnstliche/id1352307529?i=1000601764433
🎧 https://open.spotify.com/show/5hsuELMNmsySwkMeZDcC4d
#ai #ki
Johannes Hoffart
boosted

🎊🎁Big release of dirty-cat
https://dirty-cat.github.io/stable/
Broader focus: simplifying preparing non-curated dataframes for machine learning.
🔸Encoding of messy dataframes: a strong baseline for easy machine learning
🔸fuzzy_join: joining dataframes (pd.merge) despite typos
🔸Deduplication: matching categories with typos
🔸Feature augmentation: joining on an external data source to enrich tabular data
🔸Embedding of cites, companies, locations...
Johannes Hoffart
boosted
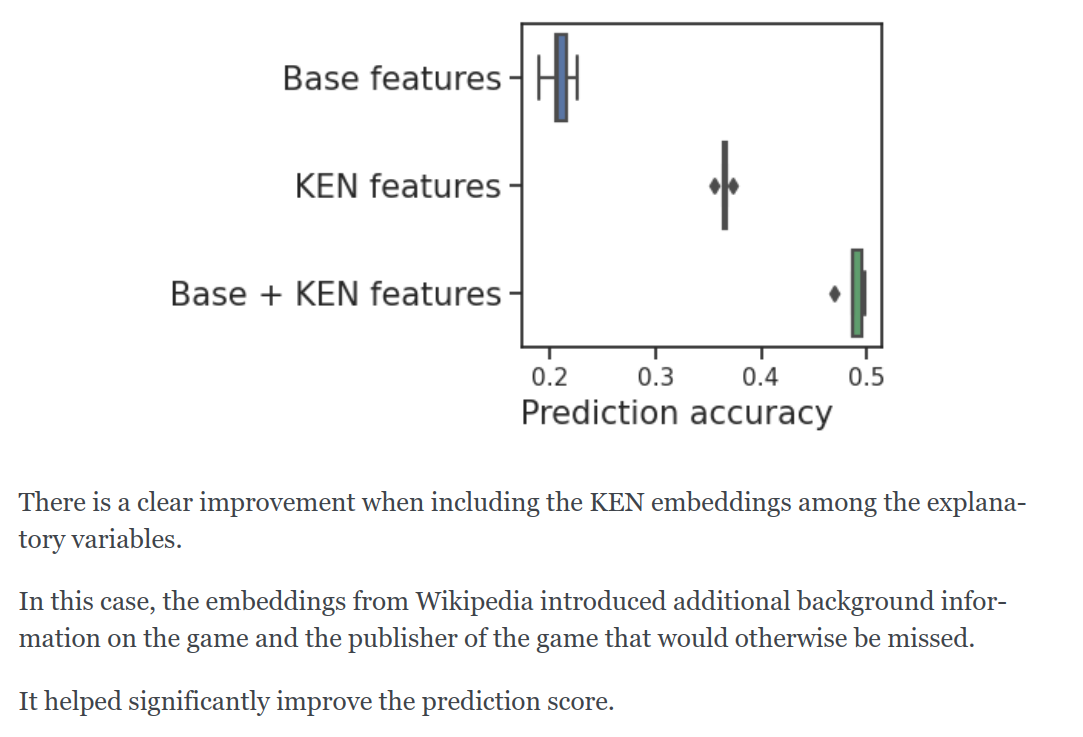
Tabular data can benefit from merging external sources of information.
The FeatureAugmenter is a sklearn transformer to augment a given dataframe by joins on reference tables.
https://dirty-cat.github.io/stable/generated/dirty_cat.FeatureAugmenter.html
fuzzy_join makes it robust to mismatch in vocabulary. Hyperparameter optimization can tune matches for prediction
For such external information,
diry-cat can download embeddings of wikipedia data on millions of entities: companies, cities, geographic locations...
https://dirty-cat.github.io/stable/auto_examples/07_ken_embeddings_example.html
Johannes Hoffart
boosted

Productive weekend! Just added 4 new Q&A's!
- Multi-GPU Training Paradigms
- The Distributional Hypothesis
- "Self"-Attention
- Training & Test Set Discordance
And "Machine Learning Q and AI" just crossed the 50% milestone! 🎉
PS: I included the Multi-GPU Training Paradigms section is in the free preview at
https://leanpub.com/machine-learning-q-and-ai/
Johannes Hoffart
boosted

This Politico article argues that #NMT (Neural Machine Translation) was one of the major drivers of European unity against the Russian invasion of Ukraine.
Not sure I fully buy the argument, but MT is probably one of the best examples of #NLProc / #AI that benefits society / #AIforGood.
https://www.politico.com/news/magazine/2023/02/03/europe-putin-ukraine-google-translate-00079301
h/t @daanvanesch
Johannes Hoffart
boosted

CALL FOR PAPERS: Research and Innovation Track
We welcome papers on novel scientific research and/or innovations relevant to #SemanticWeb, #KnowledgeGraphs, #AI, #ML, #NLP and more
Deadlines:
🗓️Abstracts: May 09
🗓️Papers: May 16
For more info: 🌐https://2023-eu.semantics.cc/page/cfp_rev_rep
Johannes Hoffart
boosted

Machbarkeitsstudie: KI-Leuchtturmprojekt in Deutschland möglich
ChatGPT kommt aus den USA. KI-Experten in Deutschland sehen darin ein Problem und fordern einen Kraftakt zur Wahrung der digitalen Souveränität.
#Bundeswirtschaftsministerium #ChatGPT #Deutschland #Europa #KünstlicheIntelligenz #LEAM #Sprachmodelle #Supercomputer #USA #digitaleAssistenten
Johannes Hoffart
boosted
In eigener Sache: heise online zieht auf eigene Mastodon-Instanz
Das Chaos bei Twitter hält an und die Mastodon profitiert weiter. Heise Medien betreibt in dem Fediverse-Netzwerk nun eine eigene Instanz.
#Fediverse #Heise #Mastodon #SocialMedia #Twitter #TwitterÜbernahme #heiseonline
Johannes Hoffart
boosted

Do you love #selfhosting? What about providing service to the public via #Codeberg?
We are looking for maintainers that take on adding code search features to our #Forgejo instance to reduce the load on the existing infrastructure team and bring this project forward.
Please see https://codeberg.org/Codeberg/Community/issues/904 if you are interested.
We are looking forward to your contributions. Thank you a lot!
Johannes Hoffart
boosted

The most interesting thing about #ChatGPT that no one is talking about is how the future will be systems talking to each other with imprecise protocols but they’re still able to understand
Johannes Hoffart
boosted

And the year has barely started!
RT @MishaLaskin@twitter.com
In-context RL at scale. After online pre-training, the agent solves new tasks entirely in-context like an LLM and works in a complex domain. One of the most interesting RL results of the year. https://twitter.com/FeryalMP/status/1616035293064462338
🐦🔗: https://twitter.com/MishaLaskin/status/1616066421582176258
Johannes Hoffart
boosted

Recent events have demonstrated how crucial resilience (e.g. of supply chains) is for our society. Semantic technologies can play a crucial here.
We will organize the #D2R2 (Linked Data-driven Resilience Research) #workshop at @eswc_conf@twitter.com
in May 2023 in Crete. We are looking forward to your contribution. Submission deadline is March 9. Check more details on our event page! https://d2r2.aksw.org #ESWC23 #CoyPu_Project #Resilience #LinkedData #cfp
Johannes Hoffart
boosted

The artificial-intelligence chatbot ChatGPT can write fake abstracts that scientists have trouble distinguishing from those written by humans. Increasing sophistication of chatbots could undermine research integrity and accuracy, researchers fear.
https://www.nature.com/articles/d41586-023-00056-7
#chatbots #ChatGPT #research #AI #ArtificialIntelligence
via @Nature
Johannes Hoffart
boosted

Hello NLP researchers around the globe! All ACL major conferences (@aclmeeting, @eaclmeeting, @aaclmeeting, and @emnlpmeeting) now have an account here. Please spread it word! #NLPRoc
Johannes Hoffart
boosted

I found the papers "Scaling Laws for Neural Language Models" (OpenAI, 2020) and "Training Compute-Optimal Large Language Models" (DeepMind, 2022) interesting:
https://arxiv.org/pdf/2001.08361.pdf
https://arxiv.org/pdf/2203.15556.pdf
They do a LOT of experiments training large language models (causal transformers) with varying hyperparameters, in particular model size, shape, batch size, and training data set size over many orders of magnitude. 1/?
Johannes Hoffart
boosted
DeepMind's paper refutes this last claim, and finds that both are equally useful.
The differences between DeepMind & OpenAI's papers matter in terms of forecasting how big LLMs need to get. They arrived at these different conclusions because DeepMind did more learning rate tuning. This blog post https://severelytheoretical.wordpress.com/2022/07/18/thoughts-on-the-new-scaling-laws-for-large-language-models/ hypothesizes that DeepMind's paper might also be not doing enough hyperparameter tuning, and the scaling law may be less severe, perhaps not even a power law.
3/3
Johannes Hoffart
boosted

On #TheDataExchangePod I speak with Mark Chen, Research Scientist at OpenAI. We discuss the evolution of DALL·E, key research developments that led to DALL·E 2, data sources, safety measures, ML models needed for its success. #machinelearning #dalle2 #dalle #AI #generativeai https://thedataexchange.media/exploring-dalle-2/
Johannes Hoffart
boosted

I do however have high hopes for #blogic and RDF+Surfaces to make the interpretation of RDF vocabularies interoperable across organizations
Johannes Hoffart
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Very interesting essay on LLMs, their limitations, and their future by @yoavgo!
https://gist.github.com/yoavg/59d174608e92e845c8994ac2e234c8a9
Johannes Hoffart
boosted
The latest issue of 'Ahead of AI' is now available!
This edition covers my top 10 papers of the year, as well as trends in the AI industry, notable developments in open source projects, and my personal yearly review routine.
Check it out at the link below and have a happy new year!
https://magazine.sebastianraschka.com/p/ahead-of-ai-4-a-big-year-for-ai
- Website
- https://www.hoffart.ai
Joined Sep 2019
