
#Logseq honest review
🟢 #FOSS with AGPL license (in theory)
🔴 In reality it depends on a closed source module responsible for sync, dubious legality and misleading
🟡 Developed almost privately by a Venture Capitals funded company but accepting small contributions on GitHub and donations on OpenCollective
🟢 Store notes in #Markdown (or in less supported #OrgMode) locally
🟡 Forces indented lists in .md files and it doesn't support normal paragraphs at all
🟡 Introduces syntax that breaks Markdown in a very bad way instead of using code blocks where possible (in Advanced Queries?)
🟡 Based on Electron, NodeJS and NPM
🟡 UI and business logic mixed together, it forces you to always run the whole UI, including for sync
🟢 Available for Linux on FlatHub (unofficially)
🔴 AppImage is the only officially supported way to install on Linux
🟡 No official reproducible builds but unofficial Flatpak ones are reproducible
🟡 Not in F-droid (and the closed source sync feature wouldn't be allowed there anyway), you have to grab their APK manually or automatically
🟢 Supports Wayland but not by default
🟢 Custom CSS
🟡 Fixed UI, no tabs, no split view
🟡 Multi-window means multiple conflicting whole instances
🟢 Plugins platform
🔴 Plugins marketplace based on GitHub
🟡 Poor integration of plugins especially from UI/UX PoV
🟢 Very interesting concept of PDF annotations
🟡 PDF annotations not stored in the .pdf as standard annotations
🟡 PDF annotations stored in their own .md files with odd names
🟢 LaTeX formulas support
🟡 No native PDF export and in general problematic
🟡 Too many menus, command palettes and other redundant UI elements
🟢 Queries with simple syntax and UI
🟡 Advanced Queries are too often needed
🟢 Datalog query language in Advanced Queries
🟡 Very broken aliases feature
🟡 Inconsistent requirements of capitalize, lowercase etc in query syntax and elsewhere that even break some functionalities
🟢 Macros
🟡 Macros don't work with most syntax, including Advanced Queries
🟢 Supports HTML and Hiccup syntax
🟢 Supports embedding Web pages using iframes
🟢 Sync is e2e encrypted
🔴 The code for e2e encryption can't be audited because it is closed source
🟡 Tons of functionalities must be configured by editing a EDN file that it is very easy to break
🟢 Forum based on Discourse
🔴 Use (and abuse) of Discord, even release announcements are made there
🟡 Some Matrix bridges
Concept: 8/10
Execution: 5/10
CC @logseq
#Logseq team setup a Feature Request category in the official forum and users are prompted to vote FRs there.
For a long time the top ones are: epub annotations, vim shortcuts, longform writing, custom todo/done/doing keywords and filters for page content and not only references section.
All of these (except maybe vim shortcuts) perfectly align with what Logseq provided so far in my opinion.
I see no development on GitHub about these, the team develops privately, the only thing we have is an outdated Trello board that has never been respected nor actual new features are listed there. It looks like the board of a Logseq from a parallel universe.
But now I see an "AI" branch on GitHub by the founder and lead developer that it seems a deep integration of Logseq with OpenAI services. To my knowledge no one made a Feature Request for it. It looks like they are focusing on what they want or what they expect people to like, ignoring the feedback system they setup.
CC @logseq

@post @logseq I have to agree with you on the FRs. The way it is currently implemented does not work. This is especially as after using Logseq for a few years and being close to it, I am still unsure where exactly to post FRs (forum, GitHub, Discord, Twitter). On top of that as you mention, most top requests are not actually implemented - I understand it can be hard and very time-consuming, but I feel there should be a lot more communication from the devs.
@post @logseq
I guess AI is top of the list as Notion, Reflect etc. have / will have it so to not be left behind, Logseq are also implementing this - I personally have no issue but it could have been communicated a bit better. They are a small team and are busy but posting a message now and again does not take too long and goes a long way in my opinion
My overall real worry for Logseq is where are they going and how will they get there. Nearly every release brings bugs which puts people off and there is no clear way of how they will remain sustainable in the long run. I am hoping this communication that should be released this week will help answer some of these questions
There are different ways to integrate "AI" tech and using OpenAI services is not a privacy-oriented one though.
Logseq description on GitHub is:
"A **privacy-first**, open-source platform for knowledge management and collaboration"
On the other hand, OpenAI's ChatGPT was blocked in Italy by the Italian authorities for severely violating privacy legislation and I don't understand why other countries don't follow.
There is the plugins platform for this kind of things and plugins using OpenAI are already available. The team shipping native integration with OpenAI out of nothing isn't just a communication issue in my opinion.


They made contributors sign a CLA so in theory they can change the license but only future development would be affected, as always.
They sent an email to contributors saying they want to drop AGPL because some companies like Google don't like it.
If they move from AGPL to GPL as I suspect it wouldn't be much different for end users. I don't think they would turn it into proprietary closed source software, but in theory they could.
I realized that having a non-profit org to ensure open governance is very important. They wouldn't be able to act like this if they were a KDE or GNOME project.
I am not against companies based on FOSS at all, I welcome them, I just don't like that they have the final say on the direction of development while also accepting donations.

While a fork won't be supported financially by most current MacOS/Windows users, there are many possible improvements for those who care about privacy, including the removal of OpenAI integration.
But since Logseq is still under heavy development a patched version would make more sense than a hard fork.
See for example Bromite browser that is based on Chromium for Android but with many privacy-oriented changes.
About Dendron: being tied to VS Code made it too much developer-oriented and couldn't attract the average PKM users.
I don't know much about Athens but I think that Logseq being a good and probably better alternative was a driving factor.

@frebtherat @post @logseq you could check Siyuan. Think that is FOSS too
@ednico @post @logseq checked out siyuan and it was meh. Not very intuitive interface, not available on f-droid and agreement text was in mandarin. Waiting to see where #logseq goes in the next few months. Just wish the logseq markdown was more standard for portability and/or there was an easy conversion mechanism for org


@frebtherat @ednico @post @logseq
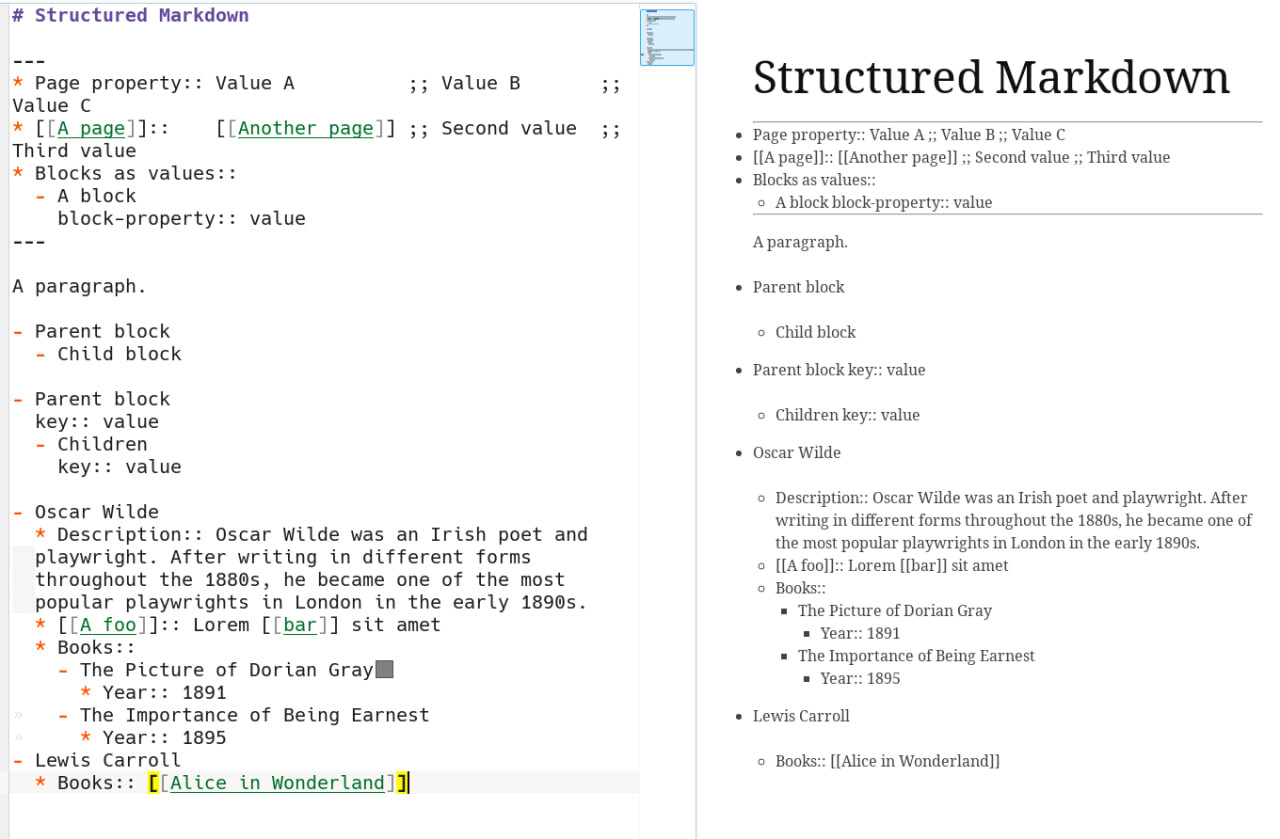
In case you are interested, I have an idea about defining a structured data (think of JSON) syntax inside #Markdown to have #Logseq's "properties" gracefully fallback to standard Markdown in other apps.
Look at the image, the "trick" is about using dash-bullets for blocks and asterisk-bullets for properties of blocks; and blocks can be values of properties:
@frebtherat @ednico @post @logseq
Also, if we replace #Markdown with #Djot (that is almost the same) we could use Djot's syntax for comments (as in programming languages) to have #Logseq-specific metadata hidden when exporting/rendering Djot files, as shown here:
https://pkm.social/@alexl/110651549732018204
and here:

@alexl Very interesting! I‘m taking note of this. This is a cool idea.
One question: what are the key-value pairs where the key is a link?
It would be:
* [Label](http://example.com):: value
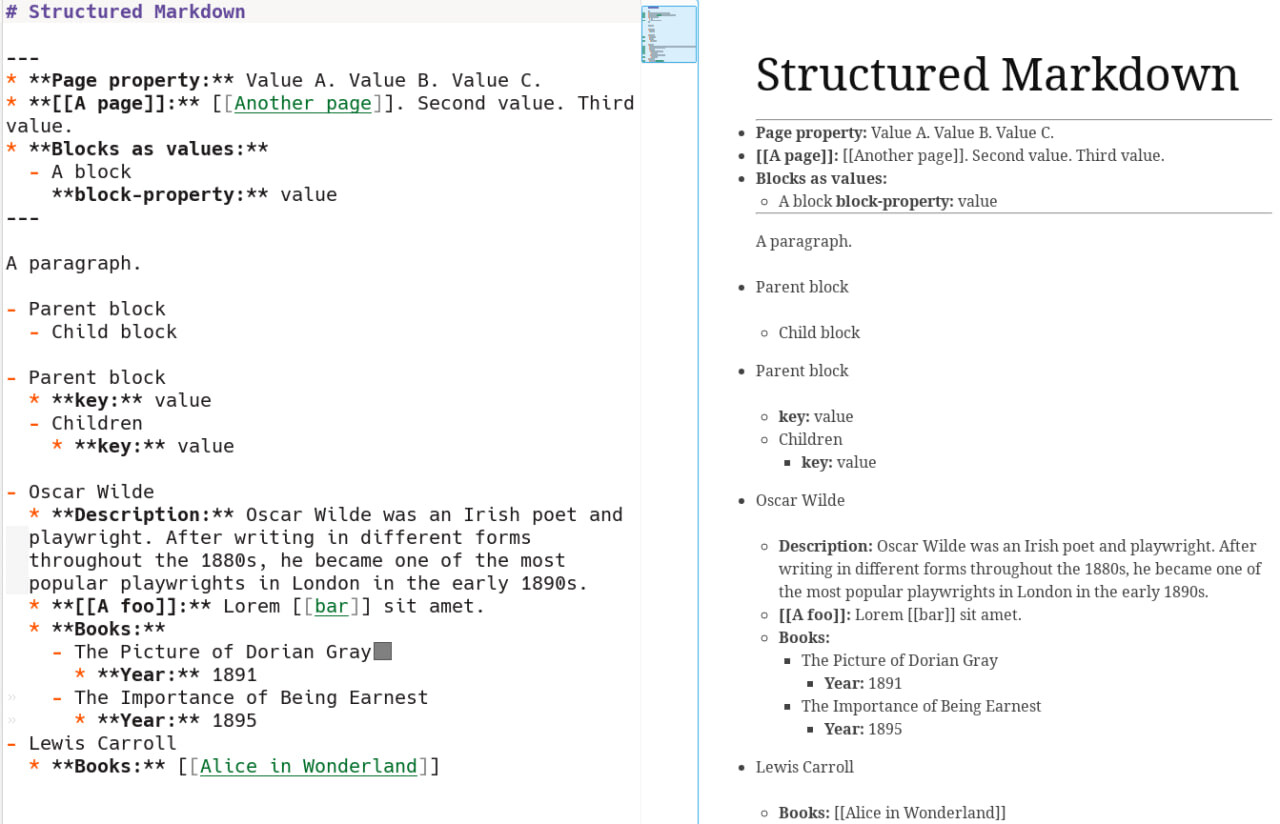
Though I think in general this syntax:
* **Key:** Value A. Value B.
is nicer once rendered:
Also, an open issue is how to assign key-value pairs to other elements like headers or paragraph (I am thinking outside the Logseq use case).
I was thinking that for headers, the asterisk-bullets between --- separators could refer to the immediately above header.
@alexl when I thought about doing a more general key-value data syntax on markdown, I used lists that begin immidiately after headings with no oeading whitespace as „metadata anchored to heading"
I thought about that, but since Markdown is supposed to support hard-breaking of lines, when you start a new line with a list there is an ambiguity: is it a hard-break or another element (a list)?
To my knowledge, not all interpreters handle this in the same way...
FYI, check how Djot supports attributes for any element by searching "attribute" in this page: https://github.com/jgm/djot
@alexl alternatively: after a heading and space, start the newline with a ::
Basically a kind of „heading as key“ argument of sorts, declaring properties being assigned to the heading block
But it wouldn't be a list, while the point is making it render nicely:
@frebtherat @ednico @post @logseq
FYI I have described my idea in details here:
https://discuss.logseq.com/t/an-idea-for-a-more-standard-markdown-property-syntax/20073

@frebtherat @ednico @post @logseq emacs orgmode has many export backends, what do you want to convert org-mode to?
@nickanderson @ednico @post @logseq
The opposite. I've considered converting my logseq markdown to org
@frebtherat @ednico @post @logseq I support this choice.
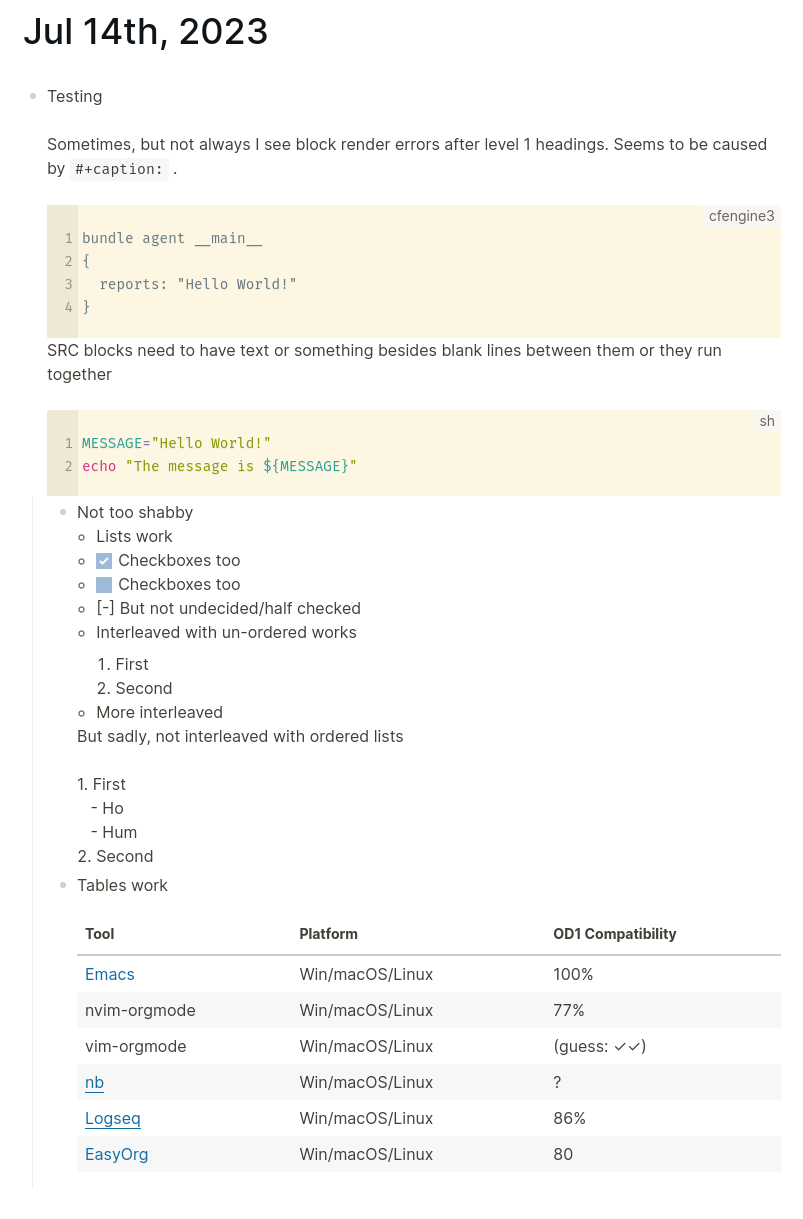
@frebtherat @ednico @post @logseq I assessed Orgdown1 support in logseq today at 86%. https://gitlab.com/publicvoit/orgdown/-/merge_requests/10

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@post @logseq I'm so sad about Logseq, I used it for a few months, really liked the idea and many things, but agree with you on implementation. It just doesn't work as it should, and is sometimes overly complicated. I have given up and use now something more simple, GoodTask for my daily tasks, and Joplin for the notes part. Good too if you're on Apple!

Given the points above and the fact I backed #Logseq for a long time but addressing these issues may require *years* and maybe the project won't survive anyway that long, what should I do? Move to a simpler but better supported system like #Emacs or wait and hope Logseq team figure out priorities?
Recent "AI" (sigh) native integration in Logseq (using OpenAI according to a GitHub branch of theirs, again zero communication by the team) lower my hopes a lot.
If they take money from people they should make clear what it will be used for.
CC @logseq @ednico #PKM