

Post @post@qoto.org
#Mathematics #Macroeconomics #Engineering #ComputerScience #Programming
#Ecology #Environment #Democracy #Freedom #Equity #Liberal #Socialism #PostKeynesian
![]() #Inkscape ·
#Inkscape · ![]() #Gimp ·
#Gimp · ![]() #Blender ·
#Blender · ![]() #VLC
#VLC
![]() #WordPress ·
#WordPress · ![]() #Mastodon ·
#Mastodon · ![]() #PeerTube:
#PeerTube:
![]()
![]()
![]()
![]()
![]()
![]() searchable
searchable
Joined May 2019
Post
boosted

The access to massive data (aka surveillance) and compute made old "AI" techniques do new things. And showed that "AI" could profitably expand "what could be done" with the surveillance data already created by the targeted ad companies that dominated the industry.
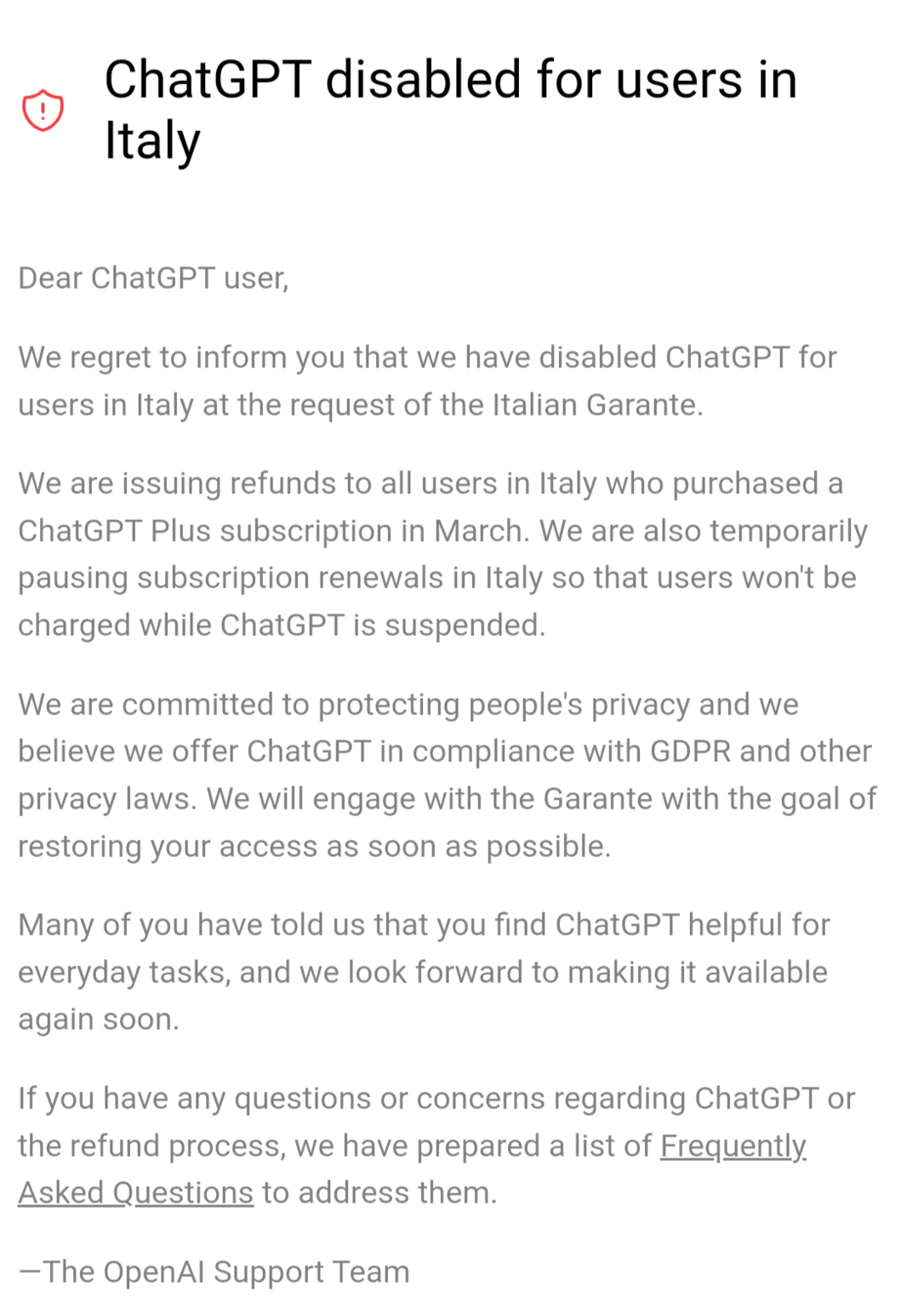
In the meanwhile #ChatGPT is blocked in Italy by Italian authorities for blatantly violating privacy laws and probably they knew what they were doing, but it was convenient for them to just ignore the laws and challenge authorities into blocking such a popular tech and make people angry:
Oh come on, again with these masks, they have been demolished by scientific publications.
Post
boosted

Elon Musk says government agencies had mind-blowing levels of access to Twitter and user’s DMs
https://reclaimthenet.org/elon-musk-government-access-to-twitter-dms?utm_source=fediverse
Post
boosted

I have encountered more image descriptions on Mastodon in 24 hours than I have in Twitter in a couple of years. Seriously. I'm not exaggerating.
As a blind person, this means a lot to me. If you read this and you describe your images, thank you so, so, so much on behalf of all of us. If you don't, now you know you'll be helping random Internet strangers make sense of your posts by typing in a few more words than usual.
Post
boosted

At almost the exact same time they rolled out this update, Microsoft deleted the public support forums. The public uservoice/feedback/feature request thing. They appear to have just removed it completely from the support site and old links to it 404. What an interesting coincidence.
Post
boosted
Post
boosted
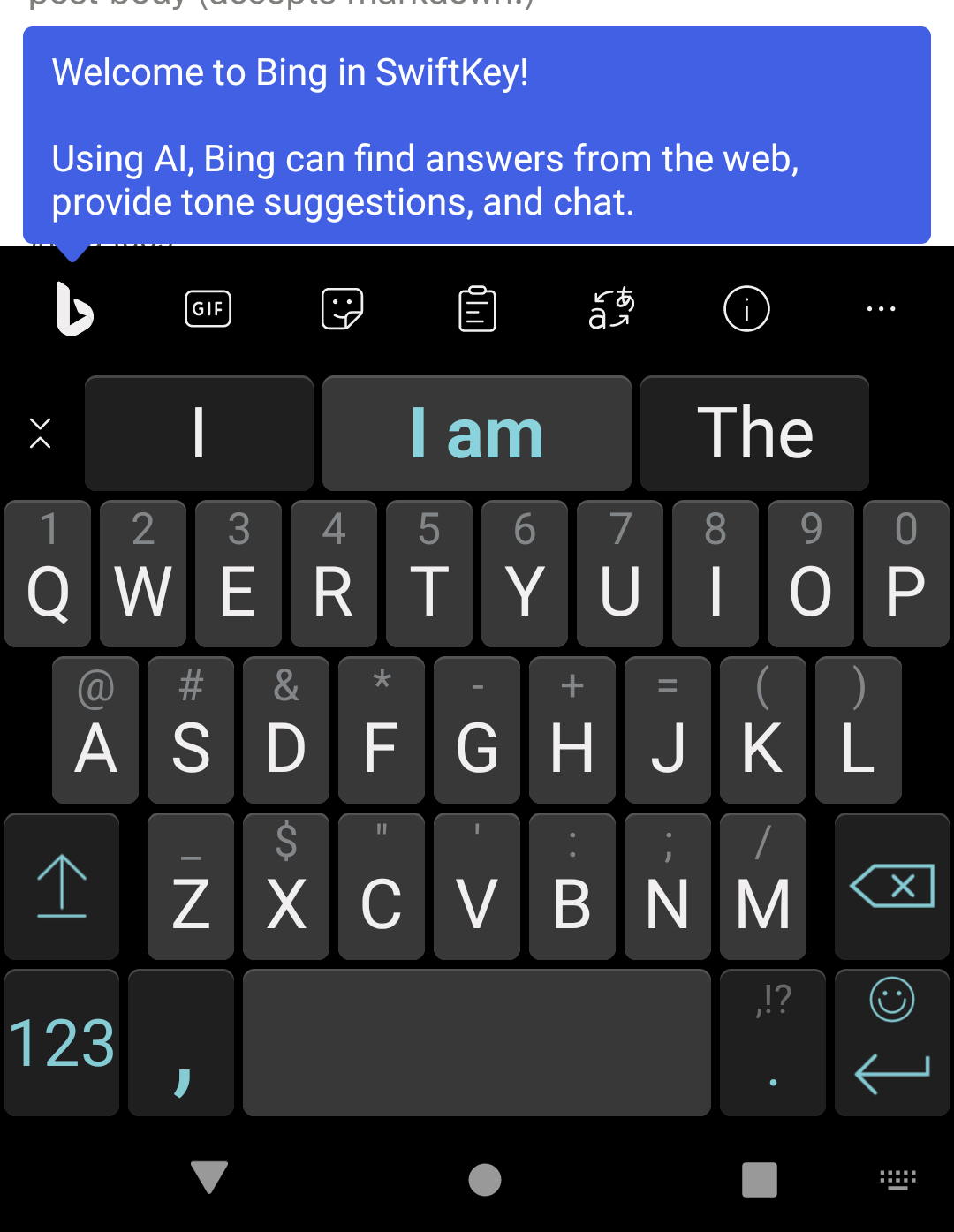
I just this second drew the line in my head from "Microsoft is one of the companies who is convinced ChatGPT is a good thing and is telling its shareholders it's going to try to shove this brand of 'AI' into everything it can" and "Microsoft owns my phone keyboard, since they bought SwiftKey" and, uh… shit, maybe I should audition AnySoftKeyboard sooner rather than later
Post
boosted

"Contrary to what neoclassical economists claim, there are no neutral market forces that allocate income in proportion to productivity. Instead there are only ideas and the power to implement them. In other words, people have ideas about what their income should be (and also what other people’s income should be). And they have the power (or lack thereof) to make these ideas a reality. That’s it."
@blair_fix, How #InterestRates Redistribute Income
https://economicsfromthetopdown.com/2023/04/16/how-interest-rates-redistribute-income/
Post
boosted

“It takes a body to understand the world – why ChatGPT and other language AIs don’t know what they’re saying” https://theconversation.com/it-takes-a-body-to-understand-the-world-why-chatgpt-and-other-language-ais-dont-know-what-theyre-saying-201280
Post
boosted
@hobs Here we’ll have to agree to disagree. AGI is IMO very much not a thing. I’m with Gary Marcus and Yann LeCun that LLMs are likely an off-ramp away from AGI, not a path towards it. And I’m with Timnit Gebru and Emily Bender that nothing in current LLMs hints at AGI.
These models are useful language tools but using them as thinking tools is IMHO a very bad idea.
But I agree that the EU might feel compelled to degrade consumer protections out of a fear of losing out on AGI.
Post
boosted
6. OpenAI is run by people involved in the tech startup scene for years if not decades. Given how many companies they’ve been involved with, it simply isn’t plausible that a competent executive in their position didn’t know about the company’s obligations towards the GDPR. They absolutely should have known better before they started training on personal data, which means there’s reason for regulators to believe that the violations are intentional.
Post
boosted
3. Removing memorised data from an LLM risks destroying it. Even though “machine unlearning” is a fast-moving topic and we don’t even know if it could work for a system as large as GPT-3/3.5/4 and it might even trigger “catastrophic forgetting” of unrelated data.
4. AFAICT, OpenAI never tried to get informed consent for adding user-provided prompts to their training data sets.
5. OpenAI does not support the right of erasure in any case.
Post
boosted
How this affects LLMs:
1. LLMs have a tendency to memorise data. Not all of it and not in a predictable way, but any time it answers a question like “who was the first person on the moon” with “Neil Armstrong” that isn’t pulled out of the ether. Memorisation also goes hand-in-hand with performance. So, these systems definitely do make copies of training data, we just can’t predict which bit it copies and which it doesn’t.
Post
boosted
Crash course in GDPR compliance, because it’s been obvious that the Americans have some misconceptions:
Remember, though: IANAL and this is not legal advice
1. The GDPR does allow data collection of arbitrary stuff of the internet, such as for search engine indexing, but it must be for a single, specific purpose so that owners of personal data that’s been indexed can take an informed decision. A system that’s specifically advertised as general-purpose is pretty much automatically disqualified.
They made contributors sign a CLA so in theory they can change the license but only future development would be affected, as always.
They sent an email to contributors saying they want to drop AGPL because some companies like Google don't like it.
If they move from AGPL to GPL as I suspect it wouldn't be much different for end users. I don't think they would turn it into proprietary closed source software, but in theory they could.
I realized that having a non-profit org to ensure open governance is very important. They wouldn't be able to act like this if they were a KDE or GNOME project.
I am not against companies based on FOSS at all, I welcome them, I just don't like that they have the final say on the direction of development while also accepting donations.
There are different ways to integrate "AI" tech and using OpenAI services is not a privacy-oriented one though.
Logseq description on GitHub is:
"A **privacy-first**, open-source platform for knowledge management and collaboration"
On the other hand, OpenAI's ChatGPT was blocked in Italy by the Italian authorities for severely violating privacy legislation and I don't understand why other countries don't follow.
There is the plugins platform for this kind of things and plugins using OpenAI are already available. The team shipping native integration with OpenAI out of nothing isn't just a communication issue in my opinion.
#Logseq team setup a Feature Request category in the official forum and users are prompted to vote FRs there.
For a long time the top ones are: epub annotations, vim shortcuts, longform writing, custom todo/done/doing keywords and filters for page content and not only references section.
All of these (except maybe vim shortcuts) perfectly align with what Logseq provided so far in my opinion.
I see no development on GitHub about these, the team develops privately, the only thing we have is an outdated Trello board that has never been respected nor actual new features are listed there. It looks like the board of a Logseq from a parallel universe.
But now I see an "AI" branch on GitHub by the founder and lead developer that it seems a deep integration of Logseq with OpenAI services. To my knowledge no one made a Feature Request for it. It looks like they are focusing on what they want or what they expect people to like, ignoring the feedback system they setup.
CC @logseq
Given the points above and the fact I backed #Logseq for a long time but addressing these issues may require *years* and maybe the project won't survive anyway that long, what should I do? Move to a simpler but better supported system like #Emacs or wait and hope Logseq team figure out priorities?
Recent "AI" (sigh) native integration in Logseq (using OpenAI according to a GitHub branch of theirs, again zero communication by the team) lower my hopes a lot.
If they take money from people they should make clear what it will be used for.
Post
boosted

{kind=link}
{kind=link}
{kind=link}
The Robot framework syntax highlighting for KDE is now merged!
https://invent.kde.org/frameworks/syntax-highlighting/-/merge_requests/474
#Mathematics #Macroeconomics #Engineering #ComputerScience #Programming
#Ecology #Environment #Democracy #Freedom #Equity #Liberal #Socialism #PostKeynesian
![]() #Inkscape ·
#Inkscape · ![]() #Gimp ·
#Gimp · ![]() #Blender ·
#Blender · ![]() #VLC
#VLC
![]() #WordPress ·
#WordPress · ![]() #Mastodon ·
#Mastodon · ![]() #PeerTube:
#PeerTube:
![]()
![]()
![]()
![]()
![]()
![]() searchable
searchable
Joined May 2019
