

R. A. Dehi @radehi@qoto.org
I read a lot. Sometimes I learn things. I like making things. I think reading and doing are complementary.
Joined Nov 2022
R. A. Dehi
boosted

@freemo why is the formatting in this post broken? The pseudo-Markdown implementation seems to be eating all the newlines. How does that happen and how can we fix it?
Is hilarious mistake in Python design. Thanks @elfprince13.
```python
def x():
e = None
while e is None:
try: print(input("? "))
except Exception as e: print(repr(e))
x()
```
Result:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 3, in x
UnboundLocalError: local variable 'e' referenced before assignment
```
@shriramk seems like a good thread to port over this doozy from Twitter. “here's possibly the worst Python scoping rule I've ever seen.” Try for ...
R. A. Dehi
boosted

Hey, I'm Windell Oskay!
My background is in atomic physics. I co-founded, with Lenore Edman https://mastodon.social/@lenore1, Evil Mad Scientist ( https://www.evilmadscientist.com ), where I design the hardware and software of the AxiDraw pen plotters. Past projects include BristleBots, WaterColorBot, CandyFab.
Latest project, with co-author Eric Schlaepfer https://mastodon.social/@tubetime, is Open Circuits ( https://opencircuitsbook.com ), a coffee-table book photographic tour inside electronic components.
R. A. Dehi
boosted
@science_quotes@c.im @freemo For engineering, is pretty valuable to know that the speed of sound (in air, near STP) is between 100 and 1000 m/s. Among other things, you know that if you compute an expected velocity for something of hundreds of meters per second, you need to think about taking aerodynamics and human safety into account that you wouldn't at lower velocities.
If you don't remember if is closer to 300 or to 400 m/s, sure, you can look that up. But knowing the order of magnitude of *every* potentially relevant phenomenon is fundamental to knowing which ones you can disregard.
R. A. Dehi
boosted
@samplereality Twitter was written in Ruby at first too, but Ruby wastes 99.9% of your CPU and 90% of your RAM, so rewrote it in Scala years ago to make the costs much less enormous.
R. A. Dehi
boosted
@deshipu Hmm, maybe it did work after all.
The archive.org snapshot of the Mastodon thread page does include various posts on the thread. Load progressively, but they load from archive.org and not fosstodon.org. Even the images in the posts load when I click through them.
But the images have URLs like http://web.archive.org/web/20221121163824/https://cdn.fosstodon.org/media_attachments/files/109/382/431/776/270/224/original/a1353c764b25ebad.png. Note that the timestamp embedded in the URL is 16:38:24, while the timestamp in the URL of the original page is 16:22. This suggests that archive.org is archiving the image successfully, but only when my browser loads the archived page and requests the image. The archival only works if I go and click on all the things in the thread that need to be archived!
My initial suspicion, however, was that archive.org only archived the Mastodon SPA and not the posts, and the SPA was requesting the posts at view time *from the original Mastodon server*. And that would have been a completely unsuccessful archival; upon viewing years later, it could have even included new information added by a malicious Mastodon server at that time. Is not so.
Should have known @brewsterkahle's team was pretty on the ball when it comes to archiving Mastodon since they even run their own instance.
R. A. Dehi
boosted

Journalist @adamdavidson on moving to Mastodon: "I think we got lazy as a field and we let Mark Zuckerberg, Jack Dorsey, and, god help us, Elon Musk and their staff decide all these major journalistic questions."
https://themarkup.org/newsletter/hello-world/mastodons-moment
R. A. Dehi
boosted

I find it frustrating how user research about how normies prefer algo timelines is floated without acknowledging that it so far has always led to outrage-driven hellholes like Twitter or Facebook.
I don’t want to take it away from anyone just b/c I don’t like it, but if you don’t have a plan for this, I’m ok with the 99% scrolling thru TikTok & arguing with their racist uncles on Facebook about made up news—while this stays a tiny nerd hole.
My adrenal system is tired of outrage baiting.
R. A. Dehi
boosted

I've now installed a "RT @" filter so Twitter retweets don't show up in my home feed (shakes fist at clouds)
R. A. Dehi
boosted

It's great how well crafted the Mastodon RSS feeds are. Just wrote a blog post about that.
R. A. Dehi
boosted

#Tumblr posts that they will be adding #ActivityPub to connect to the #Fediverse ASAP... #Mastodon
R. A. Dehi
boosted

Social media rambling
I actually have an old B&N Nook e-reader that I was able to get autographed by the inimitable @pluralistic - he wrote on the back of it “if you can’t open it, you don’t own it”
Feeling like there’s a corollary there for the modern day: “if it can be bought and destroyed by a billionaire, you don’t own it”
No billionaire can just “buy Mastodon”. They might buy an instance (I got one you can have for $8!), but the protocol is free forever.
R. A. Dehi
boosted
@scottjenson @jeffjarvis You could simply do a very easy logistic regression of your own decision of "favorite" or "bookmark" or "reply" against the vectors of boost and favorite of all your follows to get a statistical prediction of how likely you are to favorite (or reply to, etc.) a post. Let's call that prediction "quality", acknowledging that is a firmly subjective (intersubjective?) kind of quality.
Then need some way to combine that "quality" metric with recency. I'd favor a quality threshold that varies over time to maintain a roughly constant rate of posts selected from the thousands of candidates per day: 5 per day, say, or 50 per day. Maybe only rate a post 48 hours after posting so all the data is in.
R. A. Dehi
boosted

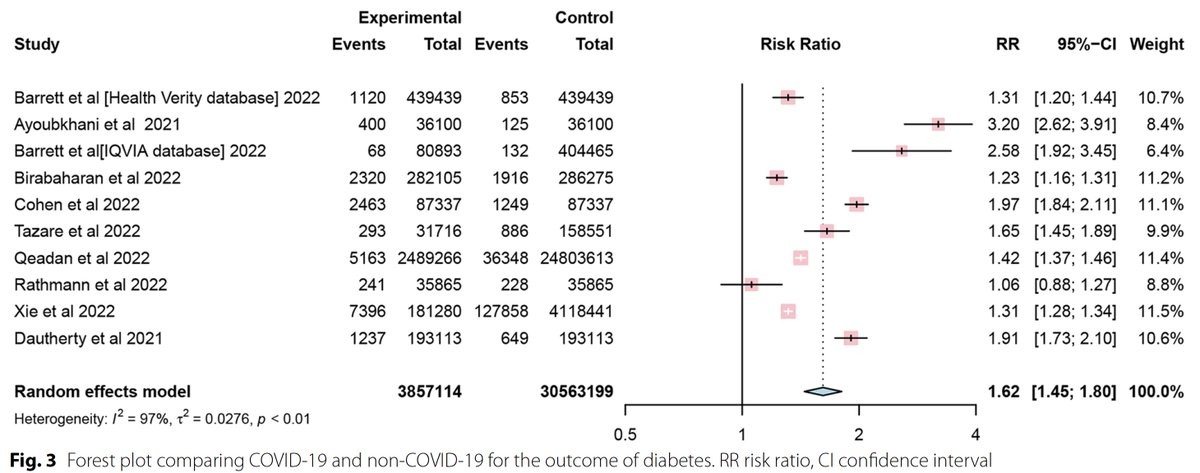
The consistent increased risk of diabetes after Covid across all age groups, highest in the first 3 months after infection, from a systematic review of 9 studies, ~40 million people
https://bmcmedicine.biomedcentral.com/articles/10.1186/s12916-022-02656-y
R. A. Dehi
boosted
(Obviously none of what say here will be useful to Mastodon admins fighting fires this week.)
Maybe needing multiple machines with gigabytes of RAM to support only 75,000 users suggests that a more efficient reimplementation of #ActivityPub would be helpful. Maybe not using Ruby and using enough backpressure to handle overload conditions gracefully would help.
I don't know, how effectively can ActivityPub implementations apply backpressure? Does the protocol itself make it difficult? Can failed deliveries get reattempted after a short time if deferred due to overload?
How much total bandwidth are we talking about for this number of users? Back of the envelope? This is super stupid because haven't even read the protocol spec, so please let me know if I'm making totally wrong assumptions here.
First, the inter-server traffic. I'm thinking media attachments aren't included in the activity stream itself, but thumbnails are; those are typically 100K; everything that isn't a media attachment is of insignificant size; users typically subscribe to 100 other users on other instances, who each post 100 posts a day; one post in five has a media attachment; and on average each remote user has two subscribers on your instance, so the 10000 incoming posts a day per user gets reduced to 5000, which is 100 megabytes per user per day. Is that about right?
100 megabytes per day is about 9600 baud, so a gigabit pipe should be adequate for the inter-server communications for around 100k people.
But then you actually have to serve those posts to them, which means at least twice as much bandwidth, and maybe more if they reload the page and you can't force their browser to cache those stinky thumbnails forever.
In terms of messages per second, 5000 incoming posts per user per day is about 6000 posts per second for 100k users. That's about an order of magnitude below what RabbitMQ can do (on one machine!) and two orders of magnitude below ZeroMQ. So the bandwidth thing rather than CPU is really probably the crucial limiting factor (though not, of course, with Ruby).
R. A. Dehi
boosted
9/ Anyway, code is increasingly generated in so many ways that we're moving from "writing lines of code is hard" to "the hard problem is determining whether a chunk of code is fit for purpose" (this motivated Joe Politz's dissertation a decade ago!).
10/ The next generation computing problems will not be about writing 80s style 5-line for-loops. It'll be about properties, specification, reasoning, verification, prompt eng, synthesis, etc. How will we get there?
R. A. Dehi
boosted

"Vox populi vox Dei" is from a quotation saying the opposite of voice of people is voice of God:
"...riotiousness of the crowd is always very close to madness"
--Alcuin 8th C AD.
I find this twitter poll interesting: https://twitter.com/danielerasmus/status/1594468482829139968
From Brink Lindsey's [The Anti-Promethean Backlash](https://brinklindsey.substack.com/p/the-anti-promethean-backlash):
"*No, the revolution I’m talking about can be described as the anti-Promethean backlash — the broad-based cultural turn away from those forms of technological progress that extend and amplify human mastery over the physical world. The quest to build bigger, go farther and faster and higher, and harness ever greater sources of power was, if not abandoned, then greatly deprioritized in the United States and other rich democracies starting in the 1960s and 70s. We made it to the moon, and then stopped going. We pioneered commercial supersonic air travel, and then discontinued it. We developed nuclear power, and then stopped building new plants. There is really no precedent for this kind of abdication of powers in Western modernity; one historical parallel that comes to mind is the Ming dynasty’s abandonment of its expeditionary treasure fleet after the voyages of Zheng He.*"
R. A. Dehi
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The thing about Twitter is that it really lacks a lot of the features you'd expect from a true Mastodon replacement.
For example, there's no way to edit your toots (which they, confusingly call "tweets"—let's face it, it's a bit of a silly name that's difficult to take seriously).
"Tweets" can't be covered by a content warning. There's no way to let the poster know you like their tweet without also sharing it, and no bookmark feature.
There's no way to set up your own instance, and you're basically stuck on a single instance of Twitter. That means there's no community moderators you can reach out to to quickly resolve issues. Also, you can't de-federate instances with a lot of problematic content.
It also doesn't Integrate with other fediverse platforms, and I couldn't find the option to turn the ads off.
Really, Twitter has made a good start, but it will need to add a lot of additional features before it gets to the point where it becomes a true Mastodon replacement for most users.
I read a lot. Sometimes I learn things. I like making things. I think reading and doing are complementary.
Joined Nov 2022
