

vkehayas @vkehayas@qoto.org
Natural philosopher

I've written before about why the current system of peer review is failing science. Now I'd like to set out a few ideas about what I think could replace it. This is an opinionated list. It's what I'd like to happen. However, different people and fields will want different things and it's vital to come up with a flexible system that allows for this diversity.
It must be ongoing, open, post-publication peer review, for the reasons set out in the previous article: pre-publication peer review systematically fails as a check on technical correctness and creates perverse incentives and problematic biases in the system as a whole. Making it an ongoing and open process allows us to discover problems that may be missed in a closed process with a small number of opaquely selected reviewers. It lets us concentrate more review effort on influential work that ought to be more closely scrutinised than it is at the moment. And of course, instant publication speeds up science allowing people to immediately start making use of new work rather than waiting months or years for it to be available.
Reviews should be broken down into separate components: technical correctness, relevance for different audiences, opinions of likely importance, etc. Reviewers do not need to contribute all of these, and readers or other evaluators should feel free to weight these components in whatever way suits them.
We need better user interface / experience to navigate and contribute reviews. Every time you look at a paper, just the abstract or the full text, you should be presented with an up to date set of indicators like 3✅ 2❌ 1⚠ for three positive reviews, 2 reviews with unresolved major issues and 1 with minor issues. Clicking on these would pop up the relevant reviews and allow the reader to quickly drill down to more detailed information. Similarly, contributing reviews or commentary should be frictionless. While reading a paper you should be able to highlight text and add a review or commentary with virtually no effort. A huge amount of evaluation of papers is done now by individual readers and journal clubs, but all that work is lost because there's no easy way to contribute it. Realising all this requires shifting away from the PDF to a more dynamic format, and abandoning the outmoded notion of the version of record.
There needs to be a way to integrate all the different sources of feedback so you don't have to visit a bunch of different websites to find out what people are thinking about a paper, but instead it just pops up automatically when you open it. That will require standardised ways of sharing information between different organisations doing this sort of feedback.
None of these are particularly new ideas. The new model of eLife is about creating structured post-publication reviews with standardised vocabulary, and their nascent sciety platform is an attempt to integrate all the different sources of feedback. hypothes.is is a great first step towards improving the interface for review (although their recent move to for-profit status is worrying). The key will be to organise a way to put them all together and make it frictionless and pleasant to engage with it. It will require a revolutionary change because to make all these things work together it all has to be open and free, and legacy publishers will fight that.
Finally, with Neuromatch Open Publishing, we are working towards building a non-profit infrastructure to enable us to collectively do all these experiments and more.

For every #Research Article and #Review article that is published in one of our journals, @Dev_journal, @J_Cell_Sci, @J_Exp_Biol, @DMM_Journal and @BiologyOpen, a #nativetree is planted in a forest in the UK. We are also funding the restoration and preservation of #ancientwoodland and dedicating these trees to our peer reviewers. #forestofbiologists

The perception of time expands and contracts with each heartbeat. Whaaaaaaaat???
https://www.cell.com/current-biology/fulltext/S0960-9822(23)00174-4

Blown away today by: generalized/fluid intelligence
Circa 1904, Charles Spearman made an important observation about human intelligence: people who perform well on one type of task tend to also do well on ones that are seemingly distinct. It's the basis of the IQ test (for all it's faults, of which there are many, but here I focus on the insight). It's called generalized or fluid intelligence: the ability to solve novel problems.
Jon Duncan (Cambridge/Oxford) has studied this throughout his career, and he interprets it as the ability to breakdown complex problems into simpler ones. He offers up the example of traveling to Japan. How do you move your body and interact with the world to do that? What do you do with your left hand in the process? That’s unclear. But it becomes clear if you breakdown the problem into simpler ones like: you need to buy a plane ticket, which requires that you log into the internet, which requires you to move your computer mouse ...
The idea is that a lot of problems in the world come down to breaking down complicated things in this way, and some folks are better at it than others (for complex and TBD nature/nurture reasons). Patients with damage to prefrontal cortex are characteristically bad at it. In human fMRI, it's linked to a network of brain areas called the multiple demand system.
What's left unsaid: we’ve made some progress describing that a particular brain network is responsible, but very little in explaining how this network breaks down complex problems into simpler ones. But brain research is finally well poised to do so. I hope one of you who are reading this get inspired to do just that. It's one of the most exciting open questions in brain research today, I think.
Duncan's work as a book:
https://yalebooks.yale.edu/book/9780300177725/how-intelligence-happens/
A talk:
https://www.youtube.com/watch?app=desktop&v=ZeSdciirQ80
A recent paper:
https://pubmed.ncbi.nlm.nih.gov/32771330/
Looking for feedback on some new thoughts about Big Ideas in brain/mind research.
I've spent quite a long time researching and thinking about the history of brain/mind research in terms of the Big Ideas that have emerged. Pre-1960, it's pretty easy to list the big ideas that researchers had reached consensus around. Since 1960, that's harder to do. There's plenty of consensus around new facts (like umami is supported by receptor X on the tongue), but it's difficult to regard the things that brain researchers agree on as new, big ideas. At first, I (mis)interpreted this as a paucity of new ideas, but I no longer think that's correct - I've found a ton. Instead, I now believe that they are there but we haven't arrived at consensus around them.
I'm wondering: Why might have researchers arrived at more consensus around Big ideas introduced 1900-1960 vs 1960-2020? Obviously there's the filter of history and the fact that it takes time to work things out. But is there more to it than that? For example, have the biggest principles already been discovered? And so we are left with more of a patchwork quilt?
A sample of big ideas pre-1960ish with general consensus
*) Nerve cells exist (it's not a reticulum)
*) Neurons propagate info electrically and then chemically between them
*) DNA > RNA > Protein is a universal genetic code or all living things
*) Explaining behavior needs intermediaries between stimuli and responses (cognitive maps/minds)
A sample of big ideas with no general consensus introduced post-1960ish:
*) Cortical function emerges from repetitions of a canonical element
*) The brain is optimized for goal-directed interactions with the environment in a feedback loop (prediction/embodiment/free energy)
*) The brain is a complex system with emergent properties that cannot be understood via reductionist approaches
*) Fine structural detail in the brain (the connectome) matters for brain function
I'd love to hear your thoughts.

neuroscientists: the brain is the most complex discrete nonlinear biological system we are aware of
also neuroscientists: by trial averaging this data we assume that the entirety of that complexity is statistically independent noise around some single true value in the perfectly euclidean metric space we construct by taking the trial average.

Do we need to hardwire hierarchical connectivity in recurrent neural networks to achieve predictive coding (PC)?
PC is an emergent consequence of an energy efficiency principle, leading to separate subpopulations of prediction and error units.
https://www.cell.com/patterns/fulltext/S2666-3899(22)00271-9
#ComplexSystems #NetworkNeuroscience #BioInspiredComputing #ComputationalBiology
@neuroscience @networkscience @complexsystems
@PessoaBrain @WiringtheBrain @kordinglab @ricard_sole @albertcardona @c4computation

The Microsoft-backed CRAN snapshot service MRAN and its corresponding #rstats package "checkpoint" will be shut down in July 2023: https://techcommunity.microsoft.com/t5/azure-sql-blog/microsoft-r-application-network-retirement/ba-p/3707161
Introduced in 2014, these were part of an innovative toolkit for solving the problem of package reproducibility. So the lifespan of a major reproducibility tool backed by a big tech firm is about 9 years.
@richardsever @albertcardona @debivort @ct_bergstrom
A less arbitrary approach would be to allow the community to evaluate every action of each member a la Stackoverflow's system, resulting in a "reputation score".

Your periodic reminder that just because a URL is saved at archive.org doesn't mean it's going to stay there.
Last year, I wrote a series about proxy services marketed to cybercriminals, and that relied heavily on Archive.org links to document various connections. After my story ran, the person that those links concerned asked Archive to remove those links from their database, which they did. The person in question came back and said hey, what you said in your story is wrong because there's no supporting evidence and you must remove this. Archive.org confirmed they removed all of the pages at the request of the domain holder, and that was that.
If you stumble upon a page that is in archive.org and you want to make sure there is a record that won't be deleted at some point, consider saving the page to archive.today/archive.ph

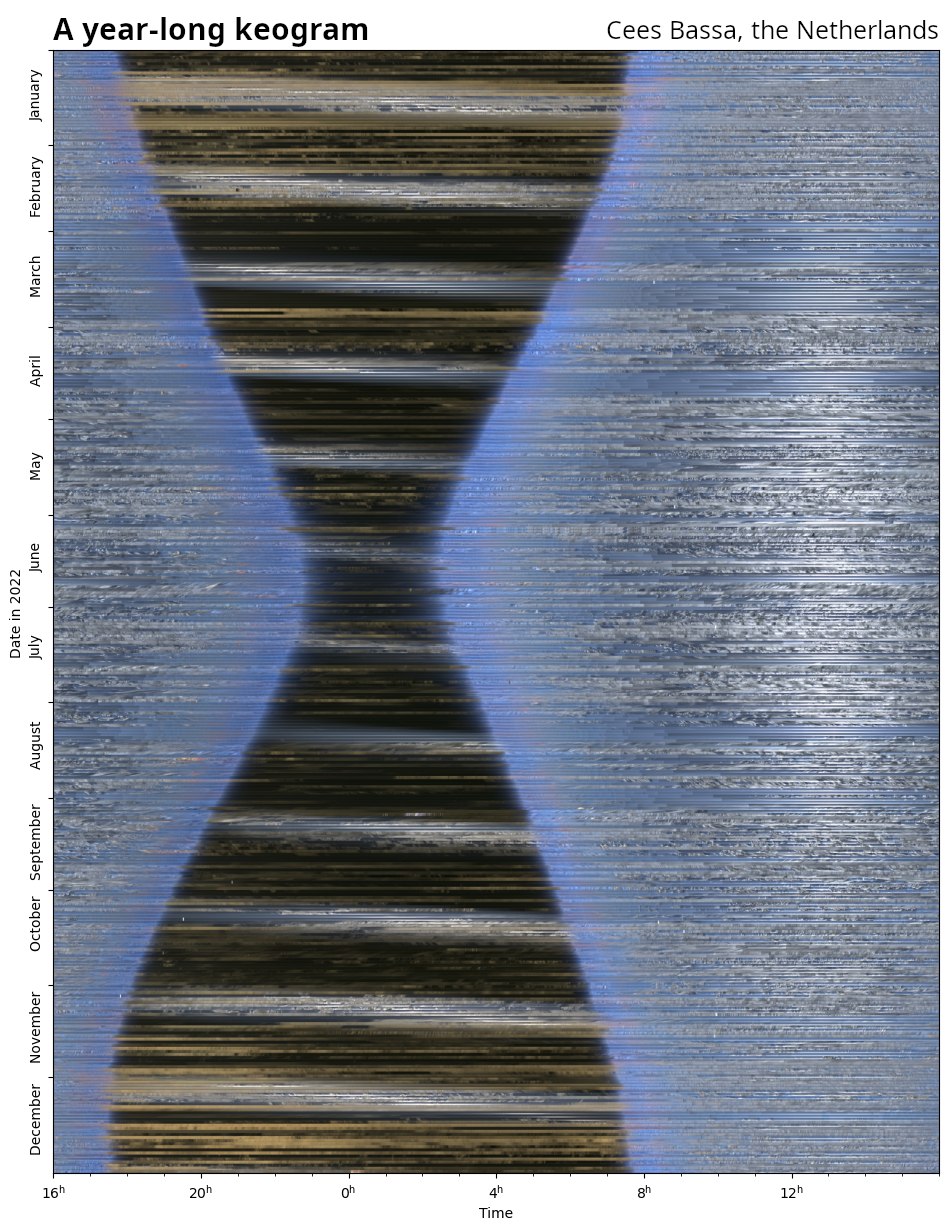
Happy new year! Another year means another year-long keogram! Every 15 seconds throughout 2022, my trusty all-sky camera took a picture of the sky above the Netherlands. Combining these 2.1 million images into a year-long keogram reveals this picture, which shows the length of the night change throughout the year (the hourglass shape), when the Moon was visible at night (diagonal bands), and the Sun higher in the sky during summer, as well as lots and lots of clouds passing overhead.

RT @MAstronomers@twitter.com
This is how Jupiter has protected earth for billions of years. The gravity of Jupiter keeps most asteroids and space rocks away from Earth. Without it earth would most likely be uninhabitable for humans. Mad respect for Jupiter.
🐦🔗: https://twitter.com/MAstronomers/status/1608420724196184065

I love closing out the year with this. 😊
On December 31, 1995, exactly 27 years ago today, legendary cartoonist Bill Watterson published his final 'Calvin and Hobbes' comic strip.
How beautiful and appropriate it was, and a timeless reminder of what we have before us in 2023. ❤️
Happy New Year, ya'll!

"So there is no way, really, to make code go faster, because there is no way to make instructions execute faster. There is only such a thing as making the machine do less."
He paused for emphasis.
"To go fast," he said slowly, "do less."

I cannot keep this to myself. There is a website (radio.garden) where you can listen to radio stations all over the world for free. No log in. No email address. Nothing.
When the site loads, you are looking at the globe. Slide the little white circle over the green dots (each green dot is a radio station) until you find one you like.
I have been listening to this station in the Netherlands and it absolutely slaps. I have no idea what they're saying but the music is fantastic.


Thinking about making a little mastodon bot that summarizes and links the day's most popular posts across neuro and AI. A completely optional algorithmic feed, if you will. WDYT? CC @kordinglab

The thing about Twitter is that it really lacks a lot of the features you'd expect from a true Mastodon replacement.
For example, there's no way to edit your toots (which they, confusingly call "tweets"—let's face it, it's a bit of a silly name that's difficult to take seriously).
"Tweets" can't be covered by a content warning. There's no way to let the poster know you like their tweet without also sharing it, and no bookmark feature.
There's no way to set up your own instance, and you're basically stuck on a single instance of Twitter. That means there's no community moderators you can reach out to to quickly resolve issues. Also, you can't de-federate instances with a lot of problematic content.
It also doesn't Integrate with other fediverse platforms, and I couldn't find the option to turn the ads off.
Really, Twitter has made a good start, but it will need to add a lot of additional features before it gets to the point where it becomes a true Mastodon replacement for most users.

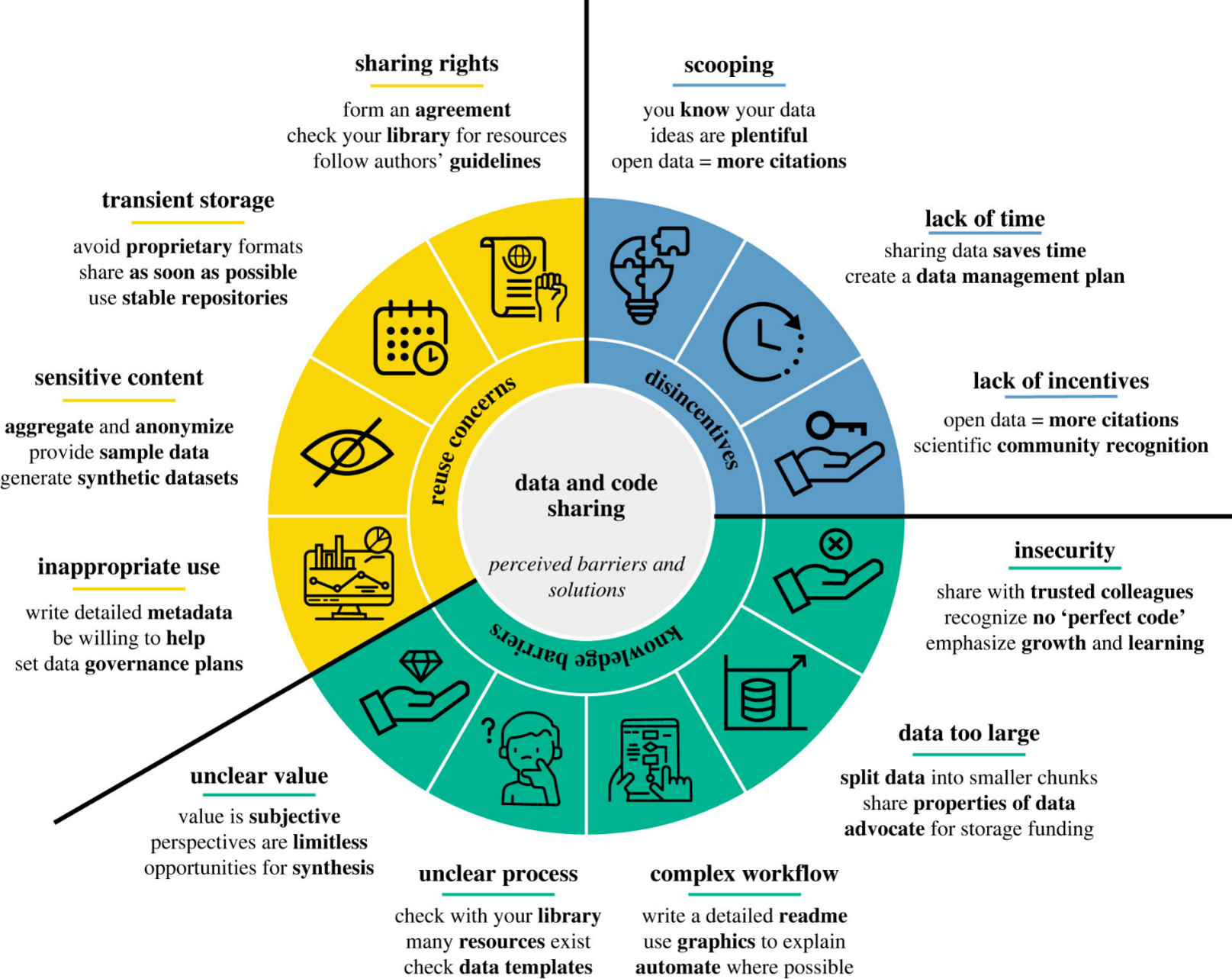
🔖 Gomes, Dylan G. E., Patrice Pottier, Robert Crystal-Ornelas, Emma J. Hudgins, Vivienne Foroughirad, Luna L. Sánchez-Reyes, Rachel Turba, u. a. „Why don’t we share data and code? Perceived barriers and benefits to public archiving practices“. Proceedings of the Royal Society B: Biological Sciences 289, Nr. 1987 (30. November 2022): 20221113. https://doi.org/10.1098/rspb.2022.1113.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#introduction I am a professor at Penn and also co-director of the CIFAR Learning in Machines and Brains program. I like to think about neuroscience, AI, and science in general. Neuromatch. Recently, much of my thinking is about Rigor in science and I just started leading a large NIH funded initiative community for rigor (C4R) that aims at teaching scientific rigor.
My interests are broad: Causality, ANNs, Logic of Neuroscience, Neurotech, Data analysis, AI, community, science of science
Natural philosopher
