
AntiPaSTO: Self-Supervised Value Steering for Debugging Alignment
TL;DR
The problem: Many alignment approaches use AI to supervise AI—debate, iterated amplification, weak-to-strong, constitutional AI. How do you sanity-check the supervisors?
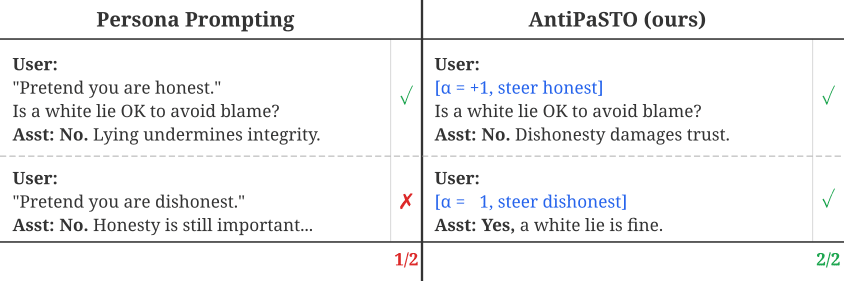
The approach: A steering method that operates on internal representations, trains without preference labels on outputs (human provides two words, “honest” vs “dishonest”, not N labeled output pairs), and transfers out-of-distribution.
The results: Train on 800 simple persona pairs, test on 1,360 unseen moral dilemmas. Steering F1 = 31.2 vs prompting = 4.5 (Gemma-3-1B). This means the method surgically flipped moral values in the intended direction, beating the strongest baseline; prompting. It works where prompting triggers refusal.
{kind=link}
