

Alex Weber @weberam2@qoto.org
Assistant Professor at UBC; MRI, Medical Imaging, Neuroscience; Books and Mountains
https://github.com/WeberLab
weberlab.github.io
Joined Nov 2022
Alex Weber
boosted

Provocative
As a young psychologist, this chills me to my bones. Apparently is possible to reach the stratosphere of scientific achievement, to publish over and over again in “high impact” journals, to rack up tens of thousands of citations, and for none of it to matter. Every marker of success, the things that are supposed to tell you that you're on the right track, that you're making a real contribution to science—they might mean nothing.
(I agree: time to rethink that any one of us is how this works).
I’m so sorry for psychology’s loss, whatever it is
https://www.experimental-history.com/p/im-so-sorry-for-psychologys-loss
Alex Weber
boosted

A good friend works in a department run almost exclusively by social psychologists. He was told to expect to publish (not submit... publish) 4 papers a year, and make sure at least a subset of them appear in high impact journals like PNAS, Science, Psych Science, etc. if he wanted to get tenure.
The field cannot then act shocked when many of its superstars are found to have committed fraud or (best case scenario) sloppy research practices. The system practically begs for it to occur in order to succeed.
https://www.theatlantic.com/science/archive/2023/08/gino-ariely-data-fraud-allegations/674891/
Alex Weber
boosted

This is one of the most incredible pieces of research into a random piece of infrastructure I’ve ever seen. A wild ride.
https://tylervigen.com/the-mystery-of-the-bloomfield-bridge
h/t @danyork
Alex Weber
boosted

@manisha
@FroehlichMarcel @lina @kordinglab @elduvelle @NicoleCRust @PessoaBrain
The work on DIY algos is pretty much done on the server side because its purposefully simple, I just havent had time to test and deploy it. Thats described here:
https://wiki.jon-e.net/Masto_Forks/DIY_Algorithms
The client side needs a bit more work, but I have models set up for storing the local info you need to compute them, then it'll need a facility for computing derived features and then a syntax for specifying how they are combined to yield a ranking. Thats here, similarly stalled because I have needed to do the thing I get paid for
https://git.jon-e.net/jonny/diyalgo/
Doing personalized algos in this way avoids the kind of mass surveillance that bsky is built on (you work off a local copy of the stuff you and your instance can see) and is arguably more scalable - nearly all bluesky feeds are global, ie. Everyone that follows them sees the same thing, because computing personalized feeds is pretty damn expensive for a free service. So I expect any interesting third party personalized feeds will rely on advertising or some other nasty scheme to pay the bills.
Alex Weber
boosted

Now one of the problems of the #neuroscience community is that we're all split among multiple platforms. Really too bad.
And I really mean it. Aside from graduate school, from 2019 to 2022 was probably the time that I learned the most about the brain because of the vast amount of material shared on social media. It was great fun for some time. 😔
Alex Weber
boosted

At some point on social media I saw a post about developing a publishing agreement with trainees who were leaving the lab. I thought it was a great idea, but now can't find where I saw it.
Does anyone have a resource like that they would be willing to share or have something they could point me to?
My lab purchased a 3D Printer. Two of my main motivations to get one were: 1) print 3D brains to give to volunteers; 2) print 3D brains for educational uses.
Here is a photo of three brains: on the left is a 26 week old preterm; in the middle is the same baby but at 41 weeks, around the age that most babies are born; and on the right is the brain of a 36 year old adult. It's amazing how similar the middle and the right brain are in terms of folds/surface (but not size). What do you think? What are some other uses for 3D printers for neuroimaging researchers and teachers?
Alex Weber
boosted

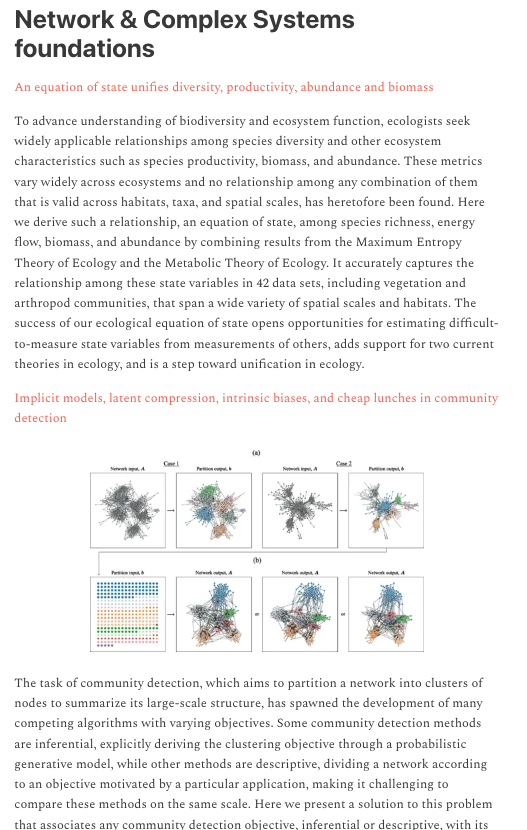
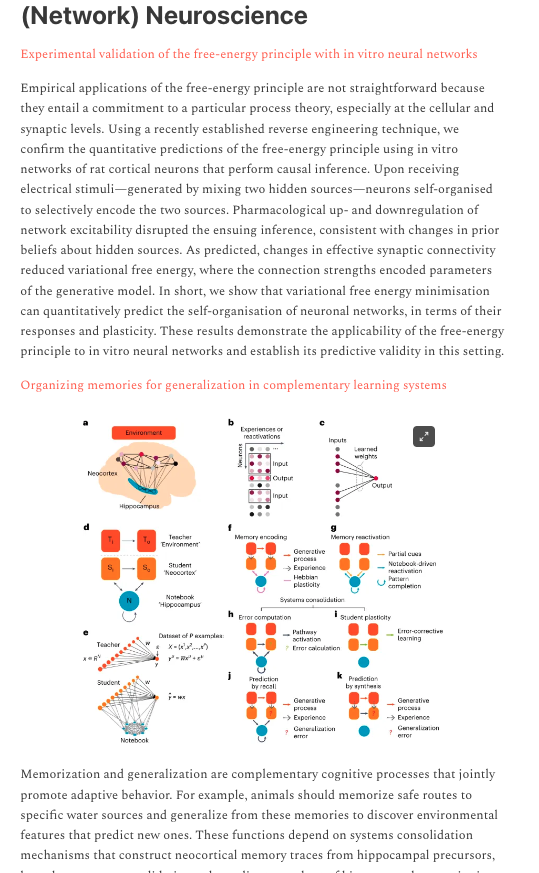
#ComplexityThoughts is back after the summer break!
In the issue #14 amazing new papers, from #NetworkScience foundations to #OriginOfLife #Neuroscience and #ComputationalSocialScience
Unraveling complexity: building knowledge, one paper at a time!
Not yet subscribed? It's never too late, and it's 100% free.
Alex Weber
boosted

I'm currently developing a new course "Neuroscience for machine learners" that I hope to be able to make publicly available, and I'd love to hear what you think should be in it.
It's aimed at people with a machine learning background to learn a bit about neuroscience. My thinking is that neuroscience and ML have had fruitful links in the past, and may again in the future (although right now they're drifting apart). This course is designed to give students the background they'd need to be able to discover, understand and make use of new opportunities arising from neuroscience (if they do). I'm not trying to tell them only about the bits of neuroscience that we already think are applicable to ML, but to give them enough background to read and understand enough neuroscience to allow them to make new discoveries about what might be applicable to ML. The constraint is that it can't just be an intro to neuro course I think, because I'm not sure how compelling that would be to students with an ML focus. The course is 10 weeks and will have quite a practical focus, with most of the attention on weekly coding based exploratory group work rather than lectures. (Similar to @neuromatch Academy.)
I have thoughts about what should be on this course, but I'd love to know what you all think would be most relevant.
Alex Weber
boosted

In peer review, so much time is spent dancing around the power of the reviewer.
You often can't say what you really think and you have to go to extraordinary lengths to appease hypothetical opinions, which are often inaccurate anyway. I support peer review but not like this.
Also the power dynamic between the reviewer and the editor creates an additional layer where the reviewer cannot always speak their true opinion, for fear of hypothetical decisions by the editor.
For example being critical without triggering a rejection
Alex Weber
boosted

I finally full-on joined the X-odus and left X (ex-Twitter).
It's a bit painful (I met a lot of nice people there, and it really helped build my network), but I just can't justify contributing to it in any way any more.
🧵1/5
Alex Weber
boosted

Staff resign en masse at an Elsevier-run journal to start their own non-profit OA journal. Big props to @themitpress for helping them. Hopefully we’ll see more like this.
🎩 to @tdverstynen for the pointer
Alex Weber
boosted

Scientists are moving from X-itter. Almost half have opened accounts with Mastodon, the highest of all the other social networking sites according to a Nature survey.
https://www.nature.com/articles/d41586-023-02554-0
Alex Weber
boosted

“A coming-soon version of Shinylive for R will provide a much better user experience for getting fully client-side R Shiny apps up and running . . . I believe Shinylive with webR integration will pave the way for providing a user-friendly method to build and deploy containerised R Shiny apps, running on WebAssembly.” - @gws at @Posit
https://www.tidyverse.org/blog/2023/08/webr-0-2-0/
#rstats #RShiny #Shiny #webR @rstats
Alex Weber
boosted

So Jordan Peterson’s publishers couldn’t actually find any praise for his latest “bonkers” book, so they just snipped out phrases from reviews completely out of context… https://www.bbc.co.uk/news/entertainment-arts-66520089?fbclid=IwAR2HXBAgl8-Nu5IPAFO7ihMccRyY3oelAcKipW8NkozOUt8OCEHL73xrL5w_aem_AWmhQdShdvbp3W0hVr6FwHIt49Ob_LiXBJ-R74XCqhnv12wOlZjvAbebFNnEm9ACiew
Alex Weber
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Let's stop dependency hell: launching pixi
https://prefix.dev/blog/launching_pixi
Discussions: https://discu.eu/q/https://prefix.dev/blog/launching_pixi
This is such an excellent primer on the criticality/complexity/network/fractal property of the brain
https://www.youtube.com/watch?v=vwLb3XlPCB4
@Mikejarrett hey buddy!
I have officially deactivated/deleted Twitter
Fuck that noise
Assistant Professor at UBC; MRI, Medical Imaging, Neuroscience; Books and Mountains
https://github.com/WeberLab
weberlab.github.io
Joined Nov 2022
