

Leo Betschart @betschart@qoto.org
live in Zurich, Chemical information consultant, organic chemist, Swiss, baker of breads, drinker of stouts, cooker of meals, enjoyer of coffee, reader of fantasy, listener of power and prog metal. MY opinions only.
#chemistswhocook #chemistswhobake #chemtoot #chemtoots #chemiverse
Joined Nov 2022
Leo Betschart
boosted

This is an experiment. Please boost.
Here's the idea: This post is going first to my followers, then, if they boost it, to other people. This domain has been registered for only this experiment. I should see in my web server's logs when mastodon instances start crawling the site for info. Then maybe also some curious humans.
I just want to play with my monitoring a bit :)
Having a citation alert for a paper of yours sometimes gets you a timely update on new developments in your area of interest. But it turns out, sometimes you will be cited for entirely different reasons.
#chemistry #synthesis
Leo Betschart
boosted

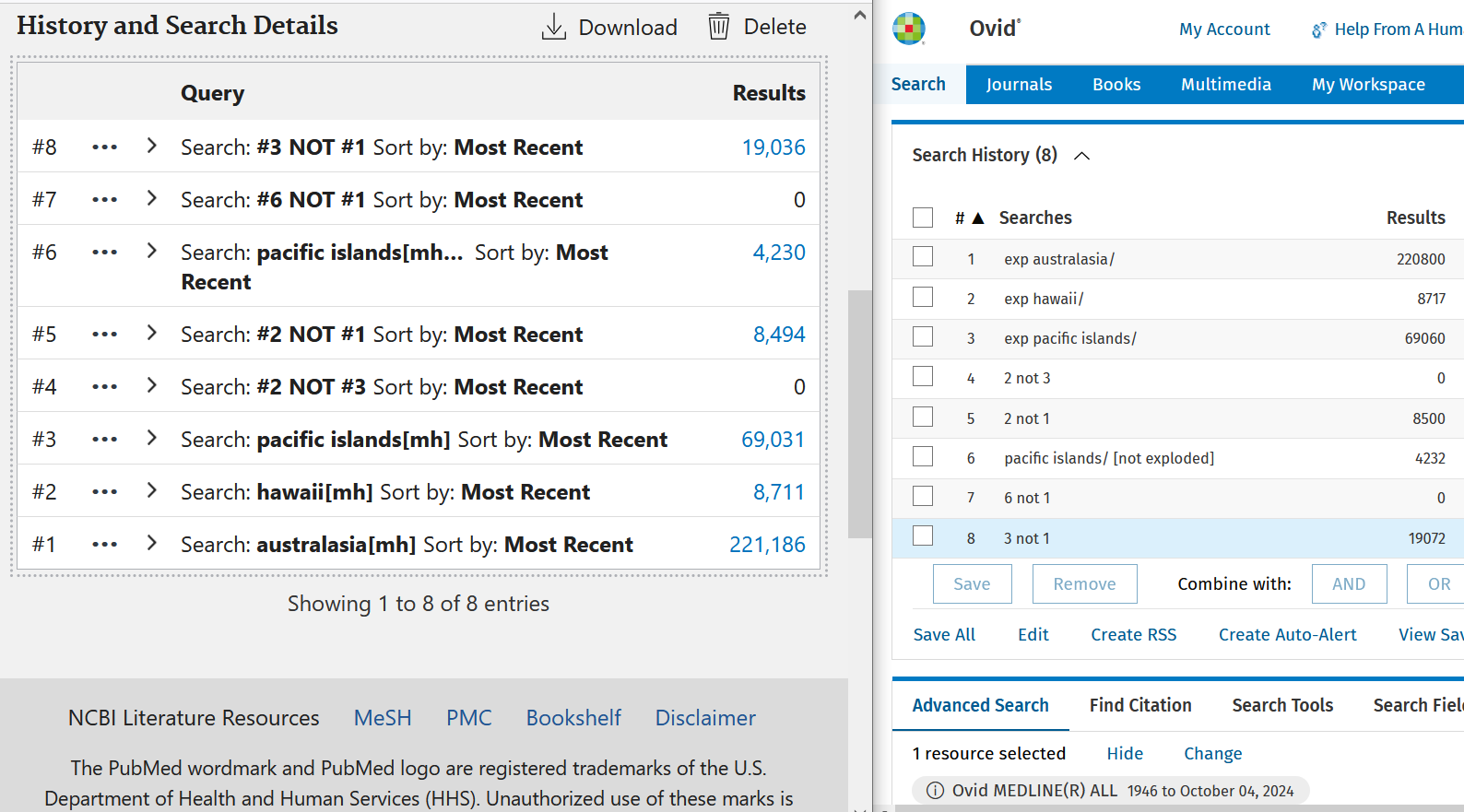
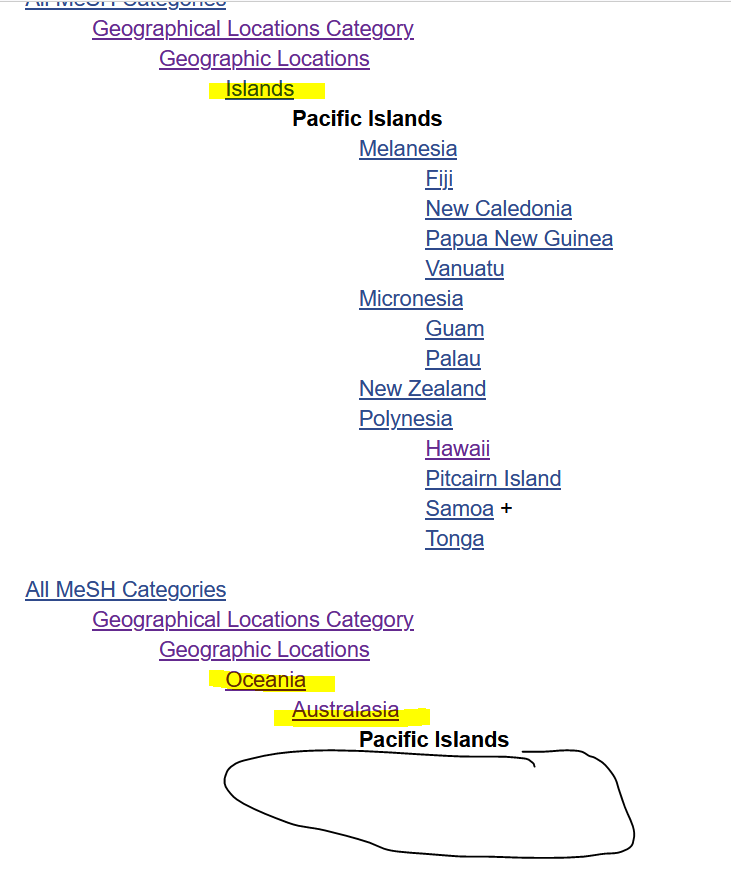
Good morning #medlibs, friendly reminder of how it works when a subject heading can have narrower terms or not have NTs depending on which hierarchy branch you are referencing
Leo Betschart
boosted

3,500 year old cheese - likely oldest ever found - on necklaces in mummies! Analysis in a report in Cell
"World’s oldest preserved cheese found in necklaces on mummies in China"
via @popsci
https://www.popsci.com/science/worlds-old-cheese-china-mummies/
I'm about a month behind for this, but it is never too late to tout a nice piece of work, to which I contributed a tiny fraction. "What is the state-of-the-art in weaning postoperative patients off opioids and thus prevent addiction?" To address this question, Sarah and Marcel had to scrutinize 2000+ papers. Kudos to that! And only 8 studies within the big pile fulfilled the inclusion criteria.
Leo Betschart
boosted

I want to remind y'all the only reason I can legally tweet out discovery evidence is that I repeatedly refused to sign the NDA Apple tried to force on me, & filed an NLRB charge against Apple for still claiming labor disputes are Apple Confidential.
Apple only released the handful of material docs I have now after I filed NLRB charges about their discovery shenanigans. They continue to pressure me to sign a protective order. I keep telling them their public safety hazards are not confidential.
Leo Betschart
boosted

Announcing Zotero 7, the biggest update in Zotero’s 18-year history
Leo Betschart
boosted
Reading a paper in Information Matters
"Being an expert in information should surely facilitate professional information practices."
You might think that, until you see a library's shared drive ;)
Leo Betschart
boosted

The whole AI thing has me endlessly confused. Half the market is crashing because investors didn't see any signs of payoff in the quarterly earnings report, but I'm so lost as to what exactly they were expecting to see. Did they just not pay any attention at all to what these companies were actually doing with AI?
Were they expecting exponential Instagram usage growth as a result of Meta making it so you can have a conversation with the search bar? Or maybe everyone was going to buy 10 new Windows licenses in celebration of Microsoft announcing they want to install AI powered spyware on everyone's computer? Or was Google going to sell more ads by replacing all the search results with reddit shitposts. Either I'm missing something or everyone's 2 remaining brain cells are just really busy fighting to death for 3rd place.
Leo Betschart
boosted

@SRLevine I hate plugging my own stuff…but I would recommend looking at some of the magic solvent pairs with DMSO as an additive or co-solvent https://www.sciencedirect.com/org/science/article/abs/pii/S108361602101834X
Leo Betschart
boosted

Being a reader in 2024 is a really lonely place. I have read several absolutely incredible novels this year and trying to get my friends to just try one is like pulling teeth. Many of these stories are about places and activities close to us, too. They aren't long. They aren't tortured reads... and yet.
Leo Betschart
boosted

It's so interesting how when you're a female leader you're never technical enough until you are and then you're too rigorous and inflexible. Love this labyrinth with no exit for us.
Leo Betschart
boosted

@grimalkina I feel this so hard.
"Be assertive, but not like that"
"Be confident! Oh, sorry, that's too confident"
"Own your expertise! Wait that's too many areas of expertise"
"Get things done! But only via collaboration with people who don't want to collaborate with you"
"You can always speak candidly and transparently here, but we expect high quality communication, which is why we'll interpret everything you say in the most adversarial way possible"
Sigh
Leo Betschart
boosted

Les toilettes inclusives c’est aussi pour la noblesse française.
Here's something that might be beneficial to the scientists out there, doing research in chemistry, material science, life sciences or pharmaceutical sciences: three times a year, we hold series of nine coffeelectures, 10 minute intros to a database, a software tool or some other thingy closely related to science. We show some reasonable use cases and give pointers to other related resources. Since last year, we also make these available via youtube. Check out our backlog on our channel: www.youtube.com/@icbpeth
#coffeelecture #science #scientist #chemistry #chemiverse #biology # lifesciences #materialsciences #pharmaceuticalsciences
Leo Betschart
boosted

Many speak idyllically about a world with "fair" or "unbiased" LLMs, but is that even possible? In our new preprint, we take the most well-defined principle of AI safety/ethics and show, in reality, an LLM could never be fair under any definition in the current ML literature. [Brief thread:👇; paper link: https://arxiv.org/abs/2406.03198]
Leo Betschart
boosted

@kravietz
As you point out it can be difficult on administrative grounds for organizations or businesses to make a donation outright. One approach that worked for me as a (now retired) manager, and I mention it for readers who may be in a position to act, is to identify needed features or fixes that are relevant for your organization and finance that work. Then you have a business case and measurable deliverables for the bean counters.
Leo Betschart
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Few things piss me off more than a huge, multi-billion IT corporation that suddenly sends me an email regarding an open-source project I’ve been running since 1990’s that I’ve recently shut down due to absolute lack of interest from its users… which happened to be telcos and large IT companies. Here’s what I replied:
Thank you for your email. As it’s often the case with open-source projects, their value to organisations is only noticed and appreciated when they go offline. I have maintained pam_tacplus for the last years and it had the call for sponsorship prominently displayed for most of the time specifically because it’s a legacy project that is difficult to maintain. None of the commercial companies that clearly do rely on it ever demonstrated any interest in even nominal donations, so it was archived. While it’s notable someone finally noticed it, I’m not the person to discuss any future development any more.
I did work in large companies and I do understand the sick logic that drives them, when it’s easier to get approval for annual spending of $50k for some office decorations than $100 for a mission-critical project which happens to be open-source and can be used for free for some time.
But it’s possible. If you’re working in such roles, please make every effort to get this $100 because otherwise it will become your responsibility to develop and maintain code that you always got for free.
Out of a small idea grows a big thing. This is how this paper in Nature https://rdcu.be/dLjsL came about. Back in the day, I was thinking if we look for enzymes cleaving a mannose construct, surely there we would find something interesting because that would probably need to happen with a yet unknown enzyme with a non-standard mechanism. Seyed Amirhossein Nasseri extended this to a whole bunch of other carbohydrates, found some cool stuff and made a whole PhD out this! Thank you Amirhossein for your persistence! For those who want the executive summary, consult this C&EN article: https://t1p.de/1ynp8
live in Zurich, Chemical information consultant, organic chemist, Swiss, baker of breads, drinker of stouts, cooker of meals, enjoyer of coffee, reader of fantasy, listener of power and prog metal. MY opinions only.
#chemistswhocook #chemistswhobake #chemtoot #chemtoots #chemiverse
Joined Nov 2022
