
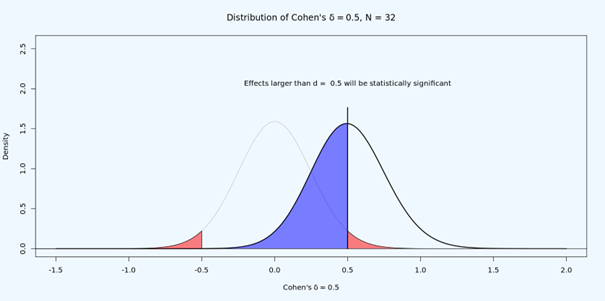
Why is it difficult to interpret null results in underpowered studies? Below, you see a study with 50% power for an effect of d = 0.5. Let’s say the observed effect is d = 0.3, so p > 0.05. What do we do?
It could be that the null is true. Then we would observe non-significant results 95% of the time. It could be that there is an effect, but this is a Type 2 error – which should happen 50% of the time. How can we distinguish the two?
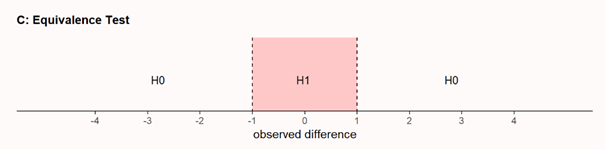
The answer is, we can’t. But what we *can* do is to test if the effect, if any, is statistically smaller than anything we would care about. This is done in equivalence testing, or inferiority testing. Is the effect within some range (or below some upper value) we think is too small to matter.

@lakens
Oh, my god, NO!
If we make strong assumptions about normality (Welch's) or uniformity (Student's t-test) of effect, as we do in equivalence testing, we can only conclude that that certain model is unlikely.
In other words, if the real effect is moderated or mediated, this procedure fails. Frequency-based statistics is very sensitive to model misspecification. It is a problem, It's not an advantage to use it. We can't conclude h0 because data is unlikely in specific h1.
@plenartowicz Wow, that's a lot of mistakes in a single toot! Hahaha. First of all, you can do equivalence tests that do not assume homogeneity, or normality. Second, violations of normality mostly have very little impact on error rates - they are quite robust. Third, you do not 'conclude' H0. You reject something else. That is of course always under assumptions.
@plenartowicz Why did you so strongly respond 'Oh my God, NO!' when almost everything that followed this is wrong? I know this is social media, so people can say things without sources that are wrong. But I am surprised you would feel so convinced about these falsehoods. Have you read these things? If so, where (then I can correct them).
1) Of course, you can assume any distribution. (And that procedure is called "Neyman-Pearson theory of statistical testing".)
'Equivalence testing' is procedure almost always connected to t-test. Like in your textbook (photo 1) or TOST procedure (Schuirmann, D. J. 1987) .
2) "Violations of normality mostly have very little impact on error rates", violation of normality have biggest impact on estimation of variance, so also on error rates and effect estimation. (It's why heteroscedasticity is so important.)
1) It'll be easy to show how easily 'equivalence tests' can be very wrong, if assumptions ignores non-normality of effect (by using t-test).
I think I can make some simulation after 22:00 GMT. For now, I can show what happens to p-distribution, when effect is (very) not normal. (photo 2 - no effect, non normal distibution when h1=true, 3&4 valid use of t-test, effect big but moderated).
Schuirmann, D. J. (1987). A comparison of the two one-sided tests procedure and the power approach for assessing the equivalence of average bioavailability. Journal of pharmacokinetics and biopharmaceutics, 15, 657-680.
https://link.springer.com/article/10.1007/BF01068419

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@plenartowicz @lakens Regarding violations of normality: I raise you a CLT. The bigger problems are strongly skewed distributions, and/or small sample sizes, and/or heteroskedasticity if applicable. At least in my experience.
@JorisMeys
But we never know if sample is big enough to detect rare (but strong) effect. EqTesting is easy way to underestimate sample size (it is why probably EqTesting is so popular in pharmaceutical studies).
@plenartowicz CLT only cares about how big is needed for the mean to be distributed normally. It couldn't care less about the effect size.
@JorisMeys @plenartowicz I think Joris hits the nail on the head.
@JorisMeys @plenartowicz Also, note that my TOSTER package of course has Welch's t-test built in, so you do not need to assume equal variances. So, it makes not sense to raise that as a criticism. And, there are also non-parametric versions - but as our simulations show, those are typically not needed (at least not in my field).
Estimation effect size and CI via Welsh's t-test assumes normal distribution of effect :) I mentioned that :)
@plenartowicz You don't need to do the simulations, we have already done them. Reading the literature is often more efficient. https://rips-irsp.com/articles/10.5334/irsp.82
@lakens @lakens
Yeah, I know your article about it. Bahrens Fisher problem is heavily discussed for years :)
But both tests have assumption of normal distribution of means. And the same problem of ignoring heavy tailed distribution /vviolation of normality / skewed distribution / heteroscedascity/ mediation / moderation. However called situation, where sample is to small to be efficiently affected by CLT.
Let me repeat, equivalence testing can't provide conclusion, that effect is small, when it's relatively rare comparing to sample, regardless significance of results.
@plenartowicz I don't understand your message. It is unclear to me which point you are making. Of course violating assumptions is not good. People need to visualize check the distribution. 99% of tests I see assume normal distributions, and that is perfectly appropriate. Where it is not, it often matters nothing. This is for psychology. Also true for other fields.
@lakens
Assuming of normal distribution under h0 (simply because of the CLT), can be perfectly valid, so t-tests for h0 also. But at the same time, equivalence test could be not!

@lakens
The solution for such problem is already known for 90 years.
1) specify your model
2) test your model against probable alternatives