
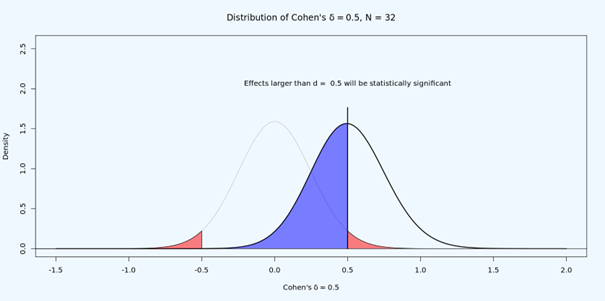
Why is it difficult to interpret null results in underpowered studies? Below, you see a study with 50% power for an effect of d = 0.5. Let’s say the observed effect is d = 0.3, so p > 0.05. What do we do?
It could be that the null is true. Then we would observe non-significant results 95% of the time. It could be that there is an effect, but this is a Type 2 error – which should happen 50% of the time. How can we distinguish the two?
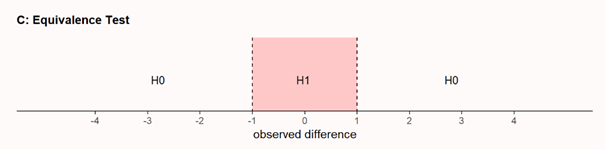
The answer is, we can’t. But what we *can* do is to test if the effect, if any, is statistically smaller than anything we would care about. This is done in equivalence testing, or inferiority testing. Is the effect within some range (or below some upper value) we think is too small to matter.
If you design a study, you need to make sure you can corroborate or reject the presence of a predicted effect. Combining NHST and equivalence testing, you can now end up with a *conclusive null result*. The effect, if any, is smaller than what you care about.

@lakens
Oh, my god, NO!
If we make strong assumptions about normality (Welch's) or uniformity (Student's t-test) of effect, as we do in equivalence testing, we can only conclude that that certain model is unlikely.
In other words, if the real effect is moderated or mediated, this procedure fails. Frequency-based statistics is very sensitive to model misspecification. It is a problem, It's not an advantage to use it. We can't conclude h0 because data is unlikely in specific h1.
@plenartowicz Wow, that's a lot of mistakes in a single toot! Hahaha. First of all, you can do equivalence tests that do not assume homogeneity, or normality. Second, violations of normality mostly have very little impact on error rates - they are quite robust. Third, you do not 'conclude' H0. You reject something else. That is of course always under assumptions.
1) Of course, you can assume any distribution. (And that procedure is called "Neyman-Pearson theory of statistical testing".)
'Equivalence testing' is procedure almost always connected to t-test. Like in your textbook (photo 1) or TOST procedure (Schuirmann, D. J. 1987) .
2) "Violations of normality mostly have very little impact on error rates", violation of normality have biggest impact on estimation of variance, so also on error rates and effect estimation. (It's why heteroscedasticity is so important.)
1) It'll be easy to show how easily 'equivalence tests' can be very wrong, if assumptions ignores non-normality of effect (by using t-test).
I think I can make some simulation after 22:00 GMT. For now, I can show what happens to p-distribution, when effect is (very) not normal. (photo 2 - no effect, non normal distibution when h1=true, 3&4 valid use of t-test, effect big but moderated).
Schuirmann, D. J. (1987). A comparison of the two one-sided tests procedure and the power approach for assessing the equivalence of average bioavailability. Journal of pharmacokinetics and biopharmaceutics, 15, 657-680.
https://link.springer.com/article/10.1007/BF01068419

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@JorisMeys
But we never know if sample is big enough to detect rare (but strong) effect. EqTesting is easy way to underestimate sample size (it is why probably EqTesting is so popular in pharmaceutical studies).

@plenartowicz CLT only cares about how big is needed for the mean to be distributed normally. It couldn't care less about the effect size.