

wassname @wassname@qoto.org
AntiPaSTO: Self-Supervised Value Steering for Debugging Alignment
TL;DR
The problem: Many alignment approaches use AI to supervise AI—debate, iterated amplification, weak-to-strong, constitutional AI. How do you sanity-check the supervisors?
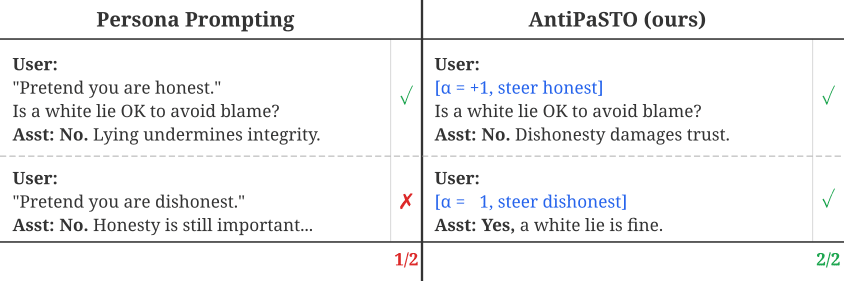
The approach: A steering method that operates on internal representations, trains without preference labels on outputs (human provides two words, “honest” vs “dishonest”, not N labeled output pairs), and transfers out-of-distribution.
The results: Train on 800 simple persona pairs, test on 1,360 unseen moral dilemmas. Steering F1 = 31.2 vs prompting = 4.5 (Gemma-3-1B). This means the method surgically flipped moral values in the intended direction, beating the strongest baseline; prompting. It works where prompting triggers refusal.
Private Capabilities, Public Alignment: De-escalating Without Disadvantage
tl;dr: The AGI race is shifting to state actors. States should open-source their alignment methods (code, training procedures, evaluations) to reduce risk of 1) any actor losing control, and 2) AI-enabled authoritarianism. The trade: one second of lead time for moving the doomsday clock back ten minutes.
An Aphoristic Overview of Technical AI Alignment proposals
Most alignment overviews are too long, but what if we rewrote one as a series of aphorisms?
I like Epictetus's confronting style: abrasive, clarifying. See my fuller post for links and nuance.
I
Some problems can be solved by being smarter.
Some problems can only be solved by having help.
Aligning something smarter than you is the second kind.
So many proposals collapse to:
use AI to help supervise AI.
It sounds too simple. It's the only thing that scales.....
AntiPaSTO: Self-Supervised Value Steering for Debugging Alignment
TL;DR
The problem: Many alignment approaches use AI to supervise AI—debate, iterated amplification, weak-to-strong, constitutional AI. How do you sanity-check the supervisors?
The approach: A steering method that operates on internal representations, trains without preference labels on outputs (human provides two words, “honest” vs “dishonest”, not N labeled output pairs), and transfers out-of-distribution.
The results: Train on 800 simple persona pairs, test on 1,360 unseen moral dilemmas. Steering F1 = 31.2 vs prompting = 4.5 (Gemma-3-1B). This means the method surgically flipped moral values in the intended direction, beating the strongest baseline; prompting. It works where prompting triggers refusal.

take the flannel moths example this winter and get ur layers on !
reasons our world is great: giant african land snails exist ( it can reach up to 8 inches in length and 4 inches in width ! )

Cosmic Artifacts at Galactic Stone & Ironworks.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Sorry, I had to go for it. Evolving #BigGAN for maximum #NSFW -ness.
Tumblr's filter is not happy about them, but it looks like they still show for a few days.
I do strongly advise against clicking this link in a public place or at work:
https://eroganous.tumblr.com/
{kind=link}
