
I'm writing a paper with some colleagues where the idea is to construct a test dataset for #LLMs (such as those provided through #ChatGPT ) that specifically tests their knowledge of #Danish.
We are generating many of the tests from data found in the Danish #WordNet (#Dannet) which I maintain.
I am writing the #SPARQL queries that gets the data out and it's really turning into a test of DanNet itself, since the strength of the various (underspecified) RDF predicates varies quite a bit.
In some cases, the relations created by the predicates are quite strong and consistent, so generating sentences from them will be an easy task.
In most cases, howver, I need to create various guard filters in my SPARQL queries, since the relations will be entirely logical in different contexts, but the contexts are too different to reliably generate sentences from, e.g. a "fillet" is a part of a "body" in a gastronomical context, but it gets weird when mixed with traditional body parts.
And it's really putting the weakness of synsets as a concept on display (synsets are sets of synonyms which constitute the basic components of meaning in a WordNet).
For example, based on part-whole relationships we can generate the following sentence:
"et system kan have en krummerik"
("a system can have a bent, erect penis" 😅)
This comes about since one meaning of "system" is in the same synset as "body", while "krummerik" (bent, erect penis) is in a part-whole relationship with body. 🤷♂️
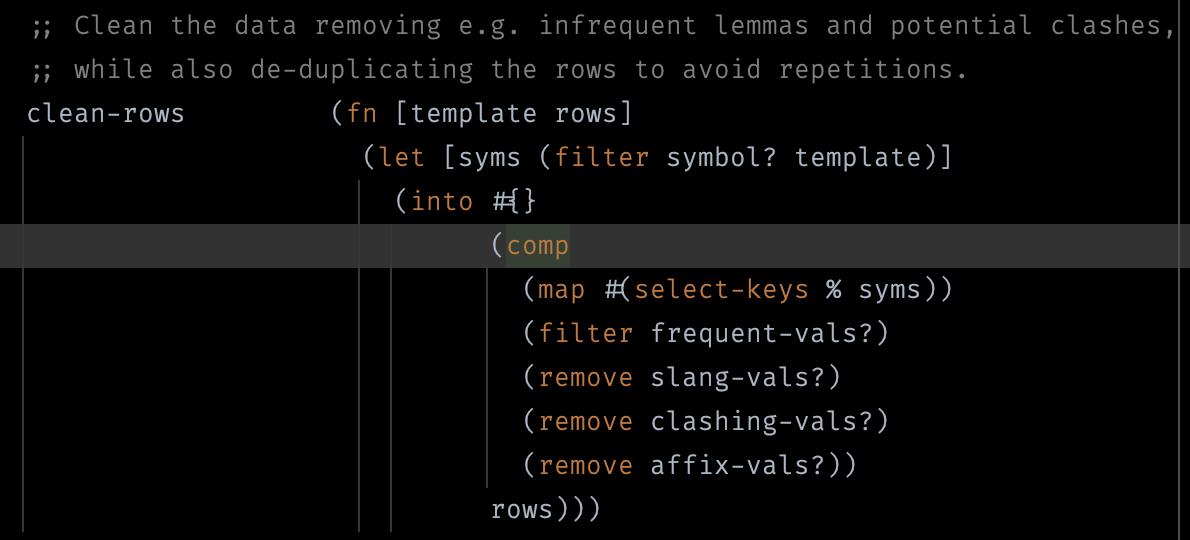
Other than writing increasingly complex SPARQL queries, I'm also having to apply a general filter to every result row.
I use a #Clojure transducer for this task comprising an ever expanding set of lemma filters.

{kind=link}
{kind=link}
@simongray what a cool project! I have done some work with Wordnet (English), but that was in C++ I think. But I am very interested in its non-big-data uses for language work. I love seeing what you are working on in Clojure.
