
I have presented this poster on #HippocampalReplay at #SFN23 !
I'm also uploading the poster as an image here, and it's on the SFN website: https://cattendee.abstractsonline.com/meeting/10892/presentation/33535
Little summary below:
Our goal was to investigate if replay of hippocampal #PlaceCells was indeed reflecting immediate #SpatialPlanning.
The existing literature is a little unclear: some studies find 'planning replay' and some do not. Most of the time, planning is not dissociated from reward consumption in these studies as they can generally be simplified to an alternation between two rewarded locations. In our case, we separate the location of planning from the location of reward and focus on replay happening at the planning time.
At the location of planning, we find that:
1) there is actually almost no replay at the time of planning
2) the rare 'start replay' events do NOT over-represent the future trajectory, or even the goal
3) the rare 'start replay' events do not differ for successful vs unsuccessful planning.
At the goal location, we find that:
4) Many replays occur at the goal, even before the reward delivery!
5) 'goal replays' strongly over-represent the goal (either before or after reward delivery)
6) 'goal replays' do not over-represent the current trajectory compared to the alternative trajectory, or even the optimal path if the less-optimal path was taken
7) 'goal replays' were strongly affected by errors and were quasi-absent during error trials (choosing an unrewarded end box)
In conclusion:
Reward (received or expected), but not planning, drives hippocampal replay!
Let me know if you have any questions after looking at the poster :D
Edit: updated because this is in the past now (but hoping to publish it soon!)

@elduvelle_neuro I have many questions!
- How do you control what will be the "time of planning"? (And I didn't get how many trials per day)
@BenoitGirard
Q1 - but first: Definition of planning: first, here I mostly use “planning” to mean “immediate trajectory selection” i.e. choosing what to do next.
Time of planning: We only provide the necessary info to the rat for accurate planning once he’s in the start box; before that, he knows where the goal is but not where he should start from so how could he plan a trajectory?
Also, the fact that they preferentially use the optimal / shortest path to the goal, from the start box, suggest that they do plan in the start box and not later in the maze.
Please let me know if this makes sense or not!
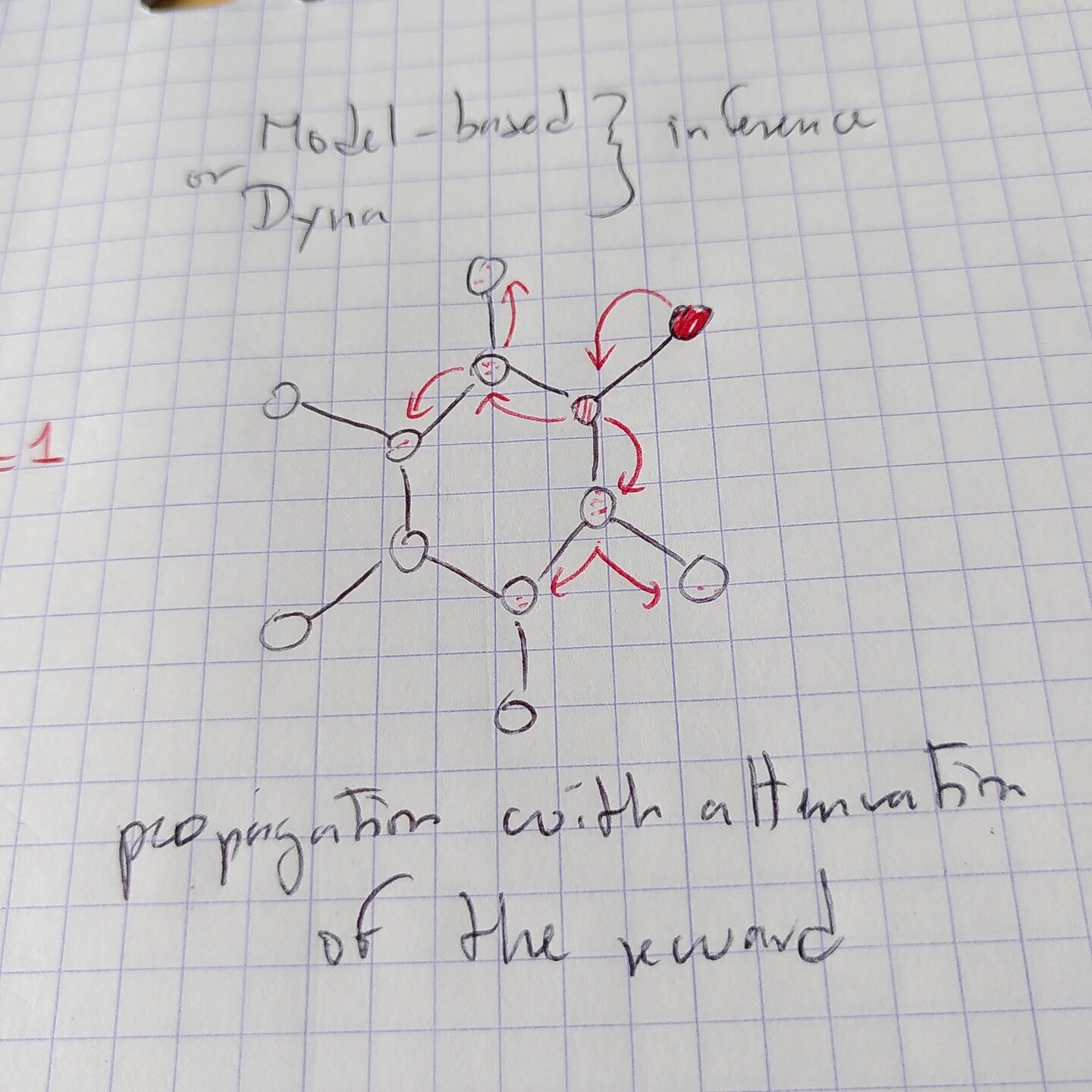
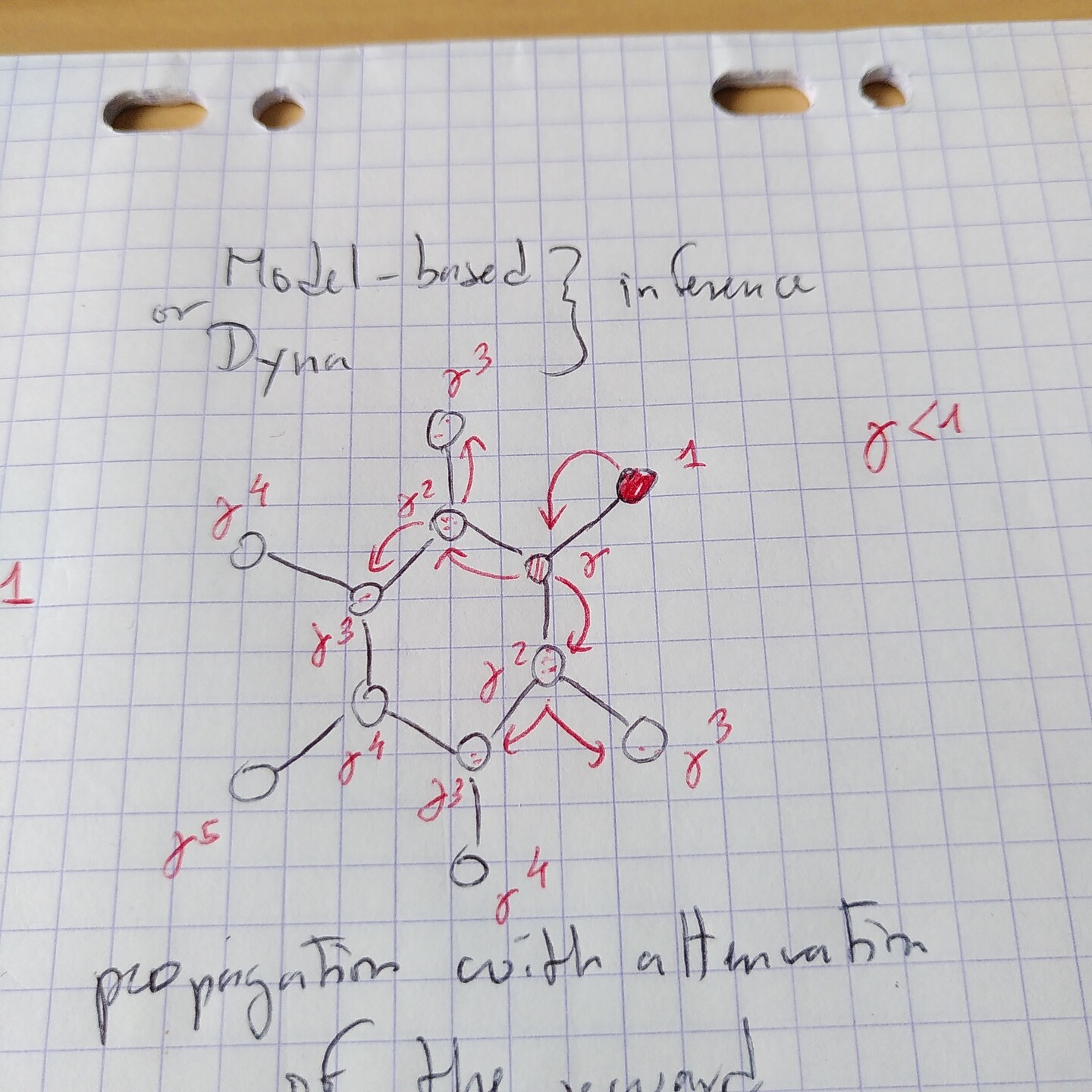
@elduvelle_neuro It does. In a RL framework, the agent could try to attribute the correct Q-values to all known states, and when this is done (and if done correctly) then it just has to climb the gradient of Q-values, which can be done from any place in the maze.
But this means that these Q-values are stored, not necessarily result from "on-the-fly planning", and thus maybe you would prefer talking about memory rather than planning.
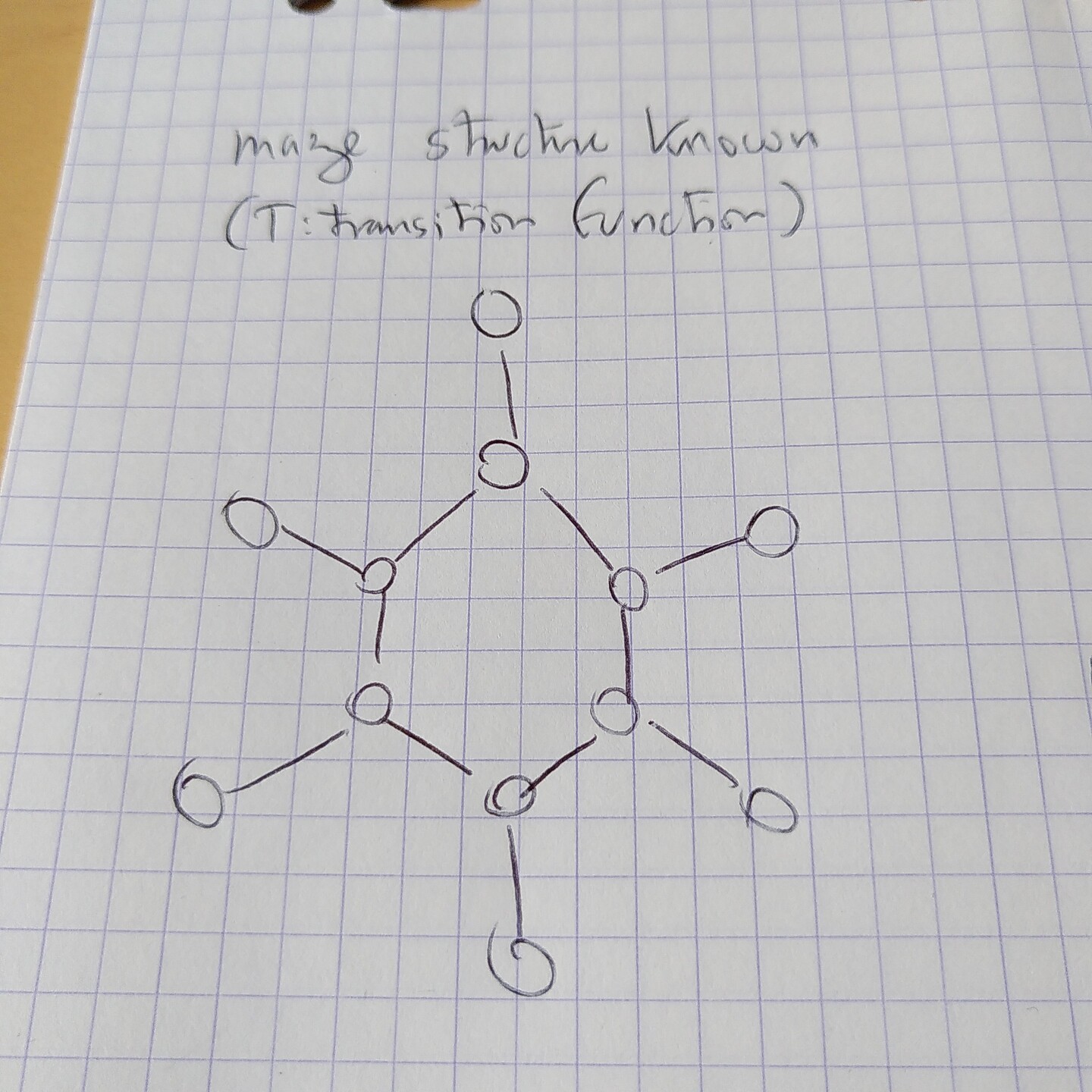
@elduvelle_neuro if the agent knows the structure of the maze... (Which could correspond to the transition function un RL)
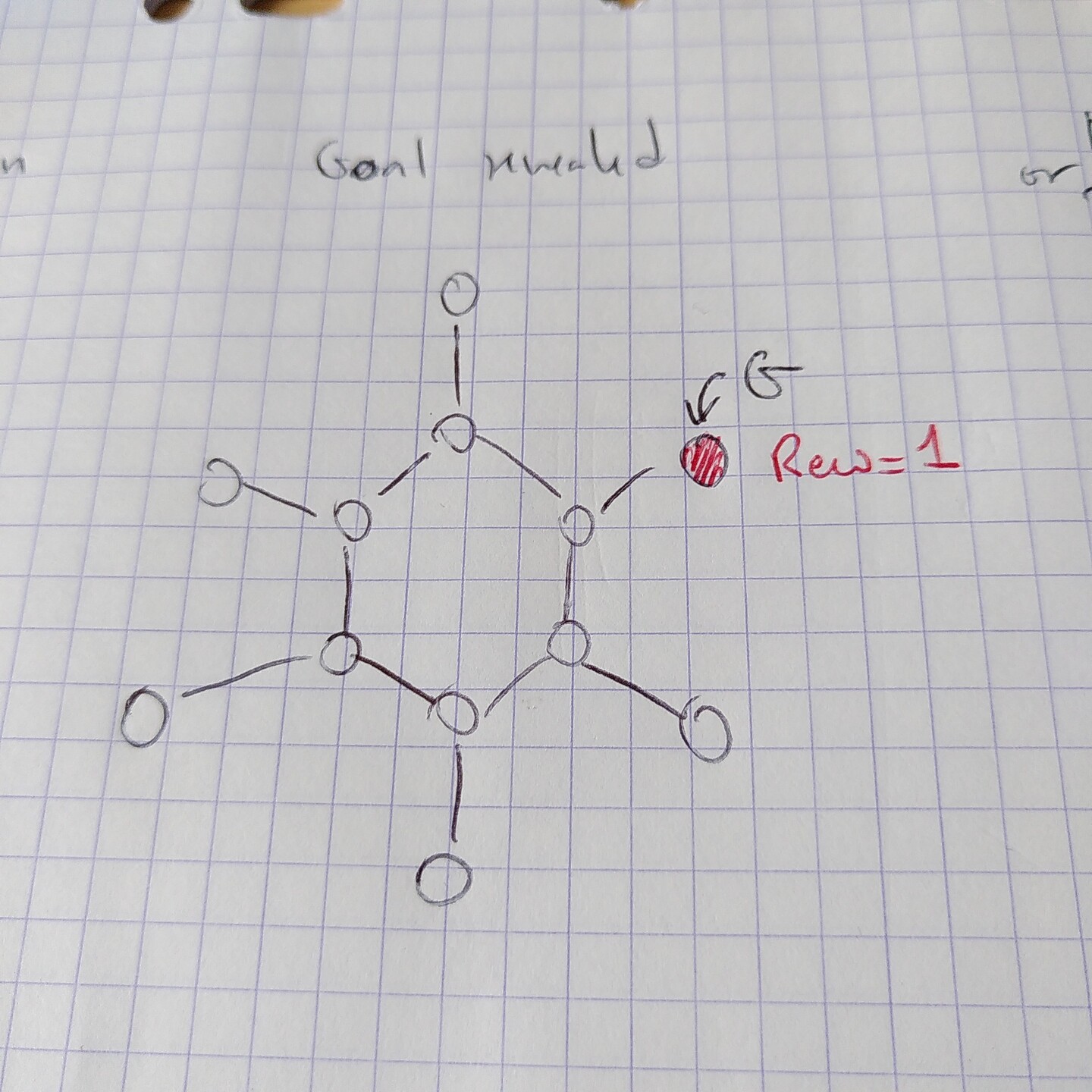
@elduvelle_neuro when the goal is revealed (informing the reward function)...

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Am I the only one having an acute flashback to mesomery in chemistry?
Sorry..
Off-topic, I know. But...it took me a longer time than I will publicly admit to realise this wasn't benzene.

@ChrisWilms23 @elduvelle_neuro 😂