

Dan O’Shea @dj@qoto.org
I study how the brain controls movement and establishes dexterity. Neuroscientist and Engineer
at Stanford in the Neural Prosthetics Systems Lab with Krishna Shenoy. @djoshea on ye old bird.

May I present for your delectation The Spike's review of the year in neuroscience!

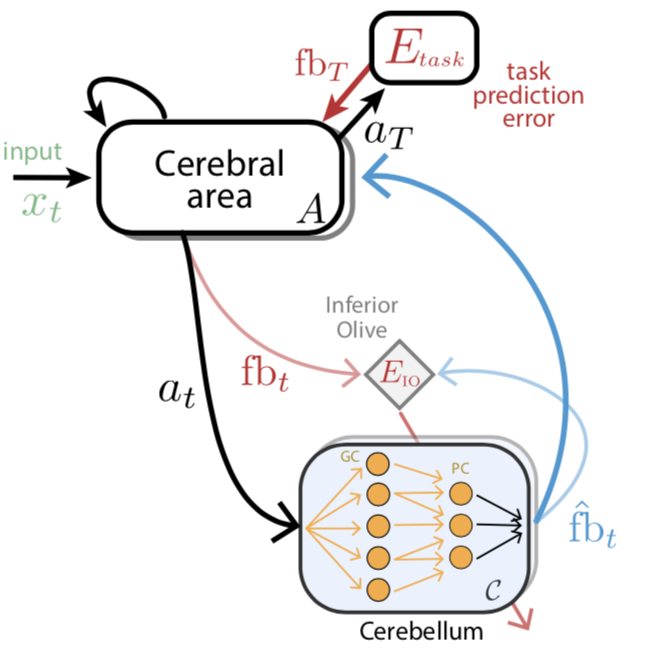
🚨 Our story on a AI-inspired model of cerebro-cerebellar networks is now out in @NatureComms with a few (useful) updates after peer review:
https://doi.org/10.1038/s41467-022-35658-8
---
RT @somnirons
New preprint by @boven_ellen @JoePemberton9 with Paul Chadderton and Richard Apps @BristolNeuroscience! Inspired by DL algorithms @maxjaderberg @DeepMind we propose that the cerebellum provides the cerebrum with task-specific feedback pred…
https://twitter.com/somnirons/status/1493881849055227906

Learning without backpropagation is really taking off in 2022
First, @BAPearlmutter et al show in "Gradients without Backpropagation" that a single forward pass with perturbed weights is enough to compute unbiased estimate of gradients:
https://arxiv.org/abs/2202.08587
Then, Mengye Ren et al show in "Scaling Forward Gradient With Local Losses" that the variance of doing this is high, but can be reduced by doing activity perturbation (as in Fiete & Seung 2006), but more importantly, having many "local loss" functions:
https://arxiv.org/abs/2210.03310
Then Jeff Hinton takes the "local loss" to another level in "Forward-Forward Algorithm", and connects it to a ton of other ideas e.g. neuromorphic engineering, one shot learning, self supervised learning, ...: https://www.cs.toronto.edu/~hinton/FFA13.pdf
It looks like #MachineLearning and #Neuroscience are really converging.

{kind=link}
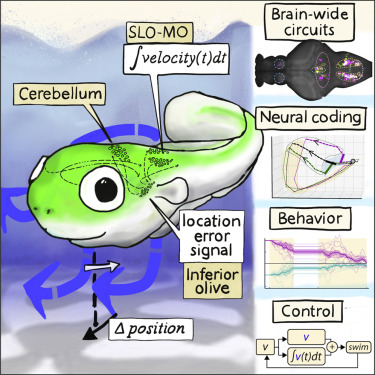
New work from the lab out in Cell today, by En Yang and colleagues:
A brainstem integrator for self-location memory and positional homeostasis in zebrafish
{kind=link}
I've shared the TikZ code for
@leaduncker and my author contribution matrix as an Overleaf template [ https://overleaf.com/latex/examples/author-contribution-matrix-heatmap-graphic/fpvnqvjjkcwy ]. Easy to customize authors, rows, and colors!
Inspired by @SteinmetzNeuro , @jsiegle, @internationalbrainlab and others mentioned at https://go.nature.com/3hOgVHL
{kind=link}
@jerlich Thanks!
#introduction
I am a postdoc at Stanford University, working with Krishna Shenoy. In collaboration with many experimental and computational colleagues, I study the neural mechanisms that control movement, and more broadly, how neural populations spanning interconnected brain regions perform the distributed computations that drive skilled behavior. I develop experimental and computational tools to understand the neural population dynamics that establish speed and dexterity.
I aim to discover insights into brain-wide computations in health and in neurological disease, with an eye towards identifying effective, targeted neuromodulation to treat movement disorders.
I also build open source tools:
- https://djoshea.github.io/neuropixel-utils/
- https://lfads.github.io/lfads-run-manager/
- https://github.com/djoshea/eraasr
- https://github.com/djoshea/haptic-control
Looking forward to joining the growing neuro community here!
I study how the brain controls movement and establishes dexterity. Neuroscientist and Engineer
at Stanford in the Neural Prosthetics Systems Lab with Krishna Shenoy. @djoshea on ye old bird.
