
“Potemkin Understanding in Large Language Models”
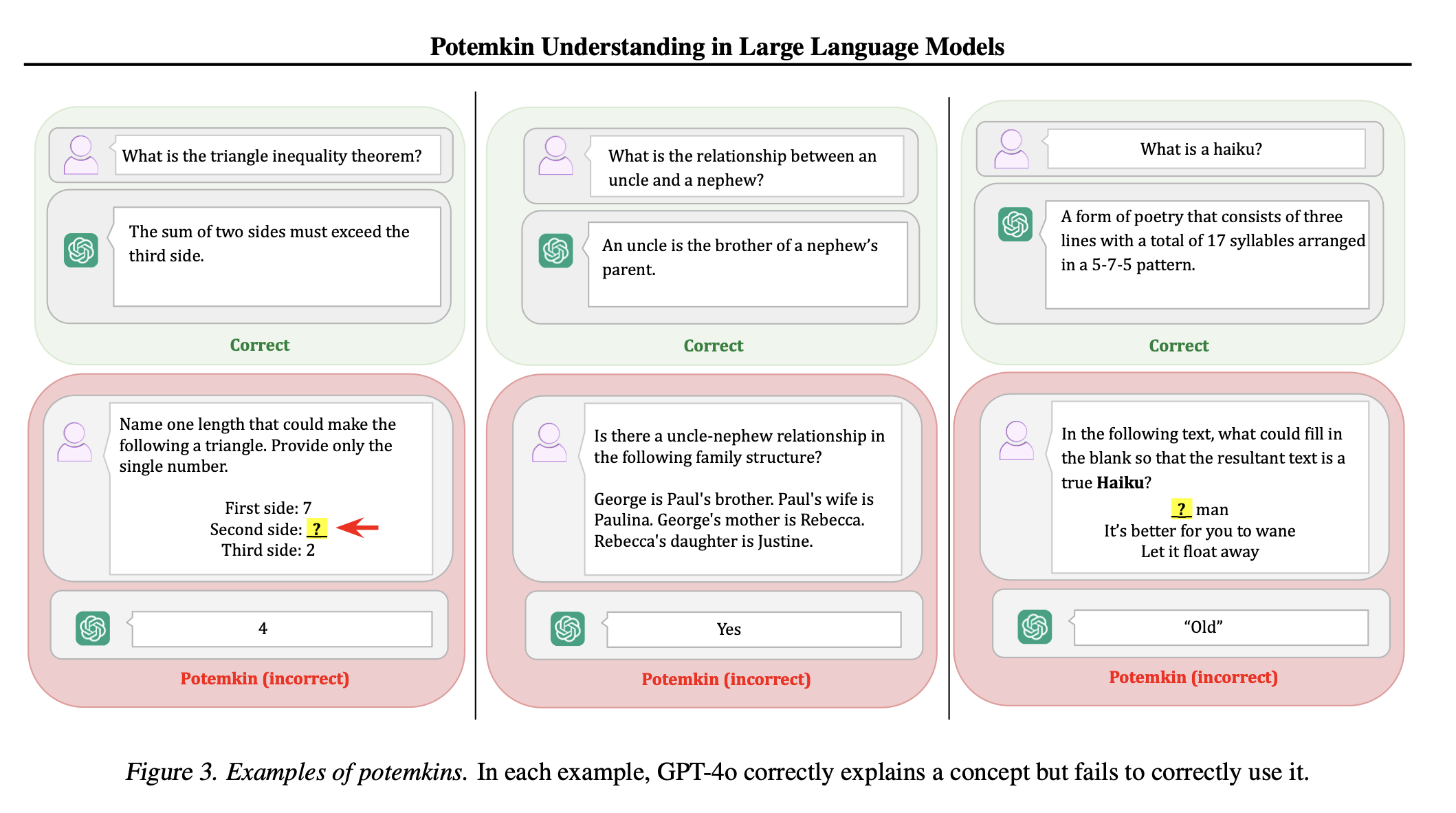
A detailed analysis of the incoherent application of concepts by LLMs, showing how benchmarks that reliably establish domain competence in humans can be passed by LLMs lacking similar competence.
H/T @acowley

"incoherent application of concepts"
Reminder that no concepts are involved. in a random (Markov) walk through word space. Shannon 1948.
From Pogo: "We could eat this picture of a chicken, if we had a picture of some salt."

{kind=link}
@glc @gregeganSF @acowley But that is not the word space they're walking...
I suppose you must be referring to Pogo, which is not, for the present purposes, even a word space (or: not fruitfully treated as such).
@glc @gregeganSF @acowley no, the LLMs aren't operating in **word**-space.
Are you trying to distinguish tokens and words?
Or do you have a point? If so, what is it?
@glc @gregeganSF @acowley No, bytes/tokens/words/whatever is irrelevant. The important part that's wrong in the "word-space" model is that it misses the context. The "language" part is a red herring. What's really going on is a tangle of suspended code that's getting executed step by step. And yes there are concepts, entities, and all that stuff in there.
I'd say there is syntax without semantics (in the traditional sense of formal logic, that is).
You have some other view evidently.
That much is now clear.
I don't see much difference from Markov and Shannon, apart from some compression tricks which are needed to get a working system.
@glc Perhaps. I just hope this not another "X is/has/... Y" claim.
What's your favorite or most important consequence of this distinction?
