

l'empathie mécanique @dpwiz@qoto.org
- Monad m
- m a -> (a -> m b) -> m b
- Previously
- https://mastodon.social/@dpwiz
- Making games
- https://haskell-game.dev
- Games made
- https://icrbow.itch.io
Toots as he pleases.
Joined Apr 2022
{kind=link}
{kind=link}
{kind=link}
{kind=link}
My power use of AI is so powerful I don't even finish the prompts before solving the problems myself.
{kind=link}
{kind=link}
{kind=link}
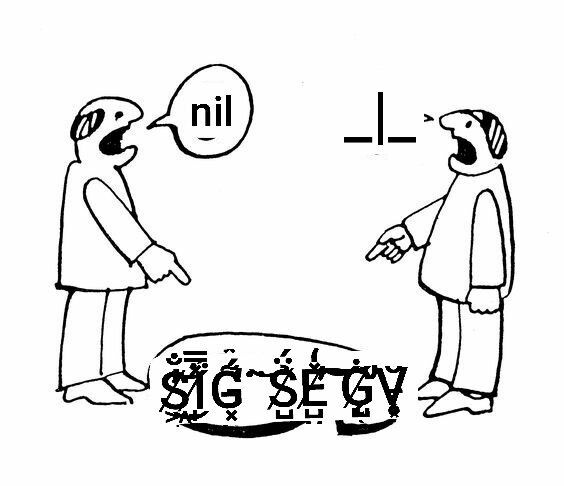
[Narrator: He was not, in fact, right.]
… terminated by signal SIGSEGV
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-- I fixed the normals, I swear! No, this time for real. Yes, I've tested it from multiple directions.
{kind=link}
If a process crashes, but there's no one on pager duty, is there an accident?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Monad m
- m a -> (a -> m b) -> m b
- Previously
- https://mastodon.social/@dpwiz
- Making games
- https://haskell-game.dev
- Games made
- https://icrbow.itch.io
Toots as he pleases.
Joined Apr 2022
