

If you predict a flat 50% on every prediction, your brier score won't be 0 for that bin unless your questions themselves are split evenly to have positive and negative outcomes. The most obvious trick to achieving this is to randomize each question's positivity. Flip a coin, if it's heads then you ask a positive question (will X happen?) otherwise use the negative version (will X not happen?)
I'm wondering if there are other techniques like this
Ok, I already posted one mental self-manipulation technique today, here's another (epistemic status on this one is much worse): theoretically, and my experience seems to bear this out, if you do X thing halfway, then switch to thing Y while trying to retain (or, typically you don't have to try) the information pertaining to X in your head, then you've just successfully loaded both X and Y in your head simultaneously. For instance, you're writing something down, then have another idea and go to write that down, your brain has to remember what you were doing with the first thing, so you now have two things packed inside your mind
The utility to this, potentially, is that you can load up your brain with a bunch of concepts simultaneously by simply writing a description of a concept, stopping halfway, then going to the next one, and so on until the end, then finishing the last, and going back to the second to last, finishing it, and so on until the beginning
I haven't tried using this deliberately for this effect too much, I just usually notice it in passing when I stop what I am doing, for instance, to write a stupid mastodon post like this one...
I was just looking at the discrete fourier transforms of the absolute day differences for various financial instruments' historic market data and it appears there is a small increase in activity every 30 days. Which I suppose makes sense!
I recently rediscovered (I've known about this for years but never done anything with it) a technique. Not sure what category of technique you could call it; maybe a neural priming technique
Anyway, it's really easy: just count up extremely slowly in your head. Alternatively, count extremely quickly. Along these lines you can also do a certain movement pattern (eg: move each finger to a thumb sequentially) really slowly or quickly. Also moving your eyes left and right slowly or quickly seems to work. With any of these, the slower / quicker the better
As with any of these sort of neural priming techniques, the effect is that some of the qualities of the technique fold over for a time into other things. In this case, slowly counting up primes you for slower behaviors later. It's *really* effective though when you're already in a fast thinking / doing mode and want to slow down. So you count up slowly and that cools off whatever neurological process is keeping you in fast mode (apparently)
In many cases, certain sets of tasks require slower, more contemplative or thoughtful, system 2 -kind of action; and some require faster, more reflexive, system 1 -kind of action. When programming in particular, I find I'll go from implementing an idea -- which usually goes pretty quickly and comes out easily -- in fast mode, but then I need to slow it down when trying to come up with novel solutions to a new problem. Staying in fast mode when I need to stay in slow mode is irritating, and slow mode when I should be in fast mode is massively inefficient and makes me go off on tangents
I wish I could say what the mechanism why this (apparently) works is, but I'm not sure, and can't say definitively anyway because I'm not a brain scientist or whatever
I discovered a new (new to me) technique for thinking which questions to ask in conversations (which may be a really no-brainer in most cases for most people, but there's of course always room for improvement with all things). It's really obvious, but not obvious too. You just ask yourself what questions you yourself would love to hear if you were the other person. Those aren't necessarily the questions they would actually respond best too, but they're probably closer
The real trick, it seems, is training yourself in meditation and with TAP reinforcement routines to use this technique after the fact. ie: After you have already been in a conversation, rerun the scenario again in your head, simulating yourself applying the technique, do this N times over (3 seems effective). Over time, theoretically, you'll internalize applying it quickly, producing more engaging and preferred questions for your conversation partner. In my experience, this seems to be how it works in practice
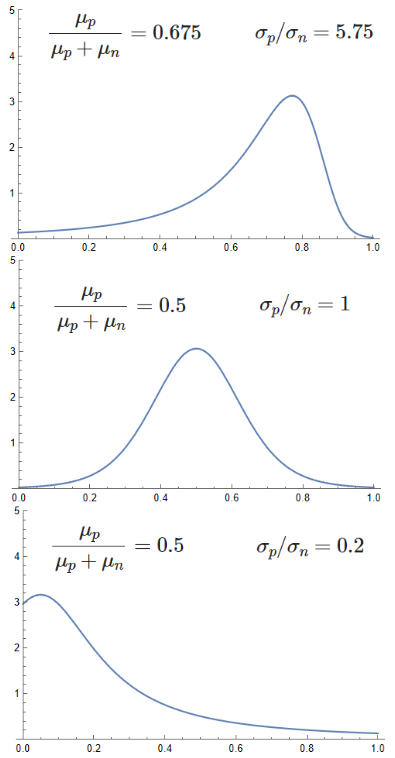
If you take two random variables $p,n$ distributed like zero-truncated normal distributions (ie: normal distributions with their negative-number tails clipped off) and you take the ratio $p/(p+n) = 1/(1+n/p)$ you get this pretty cool distribution whose PDF looks like the attached picture. It's valid on the domain [0,1] and one interpretation of it is the ratio of some positive values $p$ to a total value $T = p+n$, when the constituent values $p,n$ are uncertain
I just got back with a trip out west. One interesting thing I've noticed while riding through rows of orchards in California is the voids you see between perfectly placed trees when you're going fast enough appears to be a fractal. I simulated this situation using the mean of many images of randomly offset rows and got the following image
Pretty cool. I'm not sure if there is another way to predict the location of the voids (or even how that would work in the first place). Maybe I'll look at the math at some point
I trained an ANN (two deep perceptron) which takes a sequence of characters, and two possible next characters, and produces a number on [0,1] representing which of the given two possible next characters is most likely. Running the net on every combination of characters and doing statistics on the results yields the most likely next character after the input sequence. This is an example of ordinal probability, and is nice itc because it doesn't necessitate a finite number of discrete outputs; you could potentially have unlimited possible outputs. This is in contrast to using softmaxed vectors (as explicit probability vectors), which limit you to N possible outputs
Anyway, it seemed to perform better than a straight softmaxed vector predictor with the same training time. So it might be something to look into more
I was thinking yesterday about how our intuition about certain infinite sets' sizes can be written mathematically. I came to the conclusion that cardinality isn't really useful (for obvious reasons), but rather measures from measure theory are; and particularly a relaxation of the definition of a measure which instead of `mu(X) in [0,inf]`, you have `mu(X) < mu(Y) iff X strict subset of Y` (ie: mu is (at least partially) ordered), or equivalent. You don't even need to define mu for it to be such a useful ordinal measure
For example: consider all the possible ways to arrange a couch in a room, vs all the possible ways to arrange the couch if you keep the rotation fixed. Obviously the fixed-rotation set is a subset of the free-rotation set, so the measure of the fixed-rotation set is smaller, meaning possibly the entropy is smaller (if so defined), etc
I've been using ChatGPT's image recognition to extract information from receipts (with identifying information removed, of course), and it works vastly better than any OCR programs that I've used. It almost never makes any mistakes
I hate cookies! Every time I see a cookie I try to eliminate it from the world as quickly as possible in the only way I know how!
It seems to me that voting systems improve when they collect more information from voters. But its a competition between simplicity of ballots (and calculation) and information received from ballots. So that's probably why we see approval voting is superior to plurality and why variants of score are on the voting system quality pareto frontier
I'd propose a better voting system would be like score (or approval) but where you vote for issues, policies, and candidates' arguments, rather than candidates themselves. That way you are gaining even more information about the voters' preferences without significantly increasing the complexity of the ballot -- though it would increase the length of the ballot. Then, you select the candidate who's responses for the same ballot are most similar to the voters' responses
I've found a very fundamental methodology for discovery is the experimentation + induction loop: where you first do various things without any real intentions, lock on to the most interesting and unexplained thing you did, do variants of that thing, then model the results of the thing and its variants
I really wish this was more common in R&D in particular. Typically, R&D sets out with the goal of solving something or developing something that for a particular end. You could call this top-down R&D. Whereas inductive / bottom-up R&D probably looks like combining and assembling things you already have and understand with no particular strong goals or uses in mind, then finding uses for the results
A hypothetical example of this: combine food ingredients in various combinations and proportions until you discover a good recipe from the results. This might go far beyond what you imagine. For example, what happens if you mix clay in with bread dough? Can you use soy sauce in cookies? Is it possible to make something edible with salt or sugar epitaxy on a regular food substrate?
If we use the time-mediated pseudocausal influence loop definition of reality, then your own nonphysical qualia informationspace is real iff its time evolution operator exists
By time-mediated map loop I mean some composition of maps between objects that start and end at the same place though not necessarily at the same time. And these are pseudocausal maps, which point in the direction of pseudocausal influences. Pseudo- because causal influences probably actually only go one way (meaning with no reverse causality: two things cannot mutually cause eachother), but changes in one thing (eg: your brain) might causally influence another thing (eg: your mind) in a way that looks like its the other direction (eg: your mind moves your arm)
So for instance, for a physical process P, another physical process Q is real from P's perspective iff there is a pci map G from P to Q and a pci map H back to P from Q such that for P's time evolution operator Tp and Q's time evolution operator Tq that H Tq G P = Tp P. Note that this composition (H G) takes P back to itself (its an identity), but the composition conjugated with Q's time operator (H Tq G) takes P back to itself at a different point in time (H Tq G = Tp). Q is real from P's perspective because of this loop
For your own qualia informationspace u with time operator t and the physical process causally simulating it P with time operator T, there is a pci map e to u from P and inverse h to P from u. From *your* perspective P is real since e T h u = t u. And the identity function Iu for u can form a trivial loop with t: Iu^-1 t Iu = t, so u is always real granted it has a time evolution operator. Of course, if you have no time evolution operator then you're kind of fucked anyway
I think I'd categorize this idea as not-useful for a variety of reasons. But it could probably be made useful (well, maybe not useful, but consequential or at least implicative) if you tweaked some assumptions. For instance if you assume all pseudo-causal influences are actually causal, that would leads to some crazy shit let me tell you hwhat
Here's more metaphysical pseudotheoretical ramblings: assuming you believe that: A) you yourself have a nonphysical consciousness (NC), B) having a NC is good, C) its uncertain whether other people have NCs (because you aren't directly experiencing from their perspective, I suppose, so you can't be sure). Then: there is a weak moral imperative to form a groupmind with as many people as possible. You could even take this further: there is a weak moral imperative to incorporate as many physical processes into your psyche (via sensors, memory synchronization, recording, etc) as possible, with the goal of incorporating *the entire universe* into your conscious experience so that everything has NC
Note: any philosophical zombies (neurologically-conscious but not nonphysically conscious entities) might believe they have NC. There are no ways (as far as anyone knows) to identify whether something has a NC, or even if NCs exist in the first place (the existence of NCs is a huge and completely unjustified assumption because of this)
One HUGE problem I run into literally every day: the display and switch problem: where a webpage (especially a search results page) partially loads and shows something you want to click on, but is still loading, so you go to click on that thing, only for another element to suddenly load in and move everything on the page, causing you to click on some random thing and go to a different page. Another example of this is when you're doing just anything on a computer, you go to click on something, and another program produces a popup which appears an instant before you click, causing you to click on the popup. Generally I have no idea what these sorts of popups even say because they're then gone
I propose: a web standard where HTML elements that will appear when they are fully loaded have placeholder widths and heights settable via attributes, and show as a placeholder element before the HTML element is swapped out with its loaded form. Also, on the OS level, popups should have a grace period (of like 1 second) where you cannot click on their contents; to prevent accidental clicks
---
Along similar lines is another major issue I've been dealing with the last few days: where when you're working on some physical thing that requires you move tools and resources between locations, and you (me) then forget where you left the tools and resources. Its been such a tremendous problem for me (I've been working on my house's plumbing) that I've probably spent combined 1+ hour over the last week just looking for things I don't remember where I set
This is related to CPU caching, and search algorithms. Its generally cheaper to maintain a cache and pull a bunch of related things into the cache, drag the cache around with you, etc, than it is to go back to the source of the things and get them again in the original way
I haven't found a solution to this, but my first order approximation is to keep a bin where I demand of my self I put anything I will use repeatedly (eg: tools, resources: pipe, glue, etc). Then, I am guaranteed to know where to look with a relative cheap search instead of performing an exhaustive search
I've been trying to set up reasonable TTS on my linux machine again for the Nth time in many years. Each time I've tried in the past I've failed because either the TTS voices have been such low quality they're literally incomprehensible (still), the programs themselves have so many problems they're essentially impossible to use, or downstream programs don't accept installed TTS programs (eg: speech-dispatcher) / the tooling is bad
My conclusion: native TTS on linux is still *completely and utterly fucked beyond comprehension*. Time to install balabolka in wine for the Nth time I guess
Due to seeming inadequacies with combining the probabilities from multiple agents (averaging, elementwise multiply + renormalize, etc are all unsatisfying in some cases), I've been looking at this betting model of predictions. In this model, multiple agent's estimates are explicitly taken into account, and instead of a list of probabilities -- one probability for each outcome -- you have a matrix of real-valued bets and a payout multiplier vector. So I've been thinking: well, how is this useful when you only have *one* bettor? Simple: that one bettor has multiple sub-bettors who each bets differently. In the case where you have one sub-bettor for each outcome, each sub-bettor bets on only one outcome, and no two sub-bettors bet on the same outcome, there is a simple correspondence between the expected payout for any outcome and the probability of that outcome. But the really interesting version is when you have fewer sub-bettors than outcomes, and when the sub-bettors' bets can overlap. It seems that in that case, the sub-bettors each correspond to models of the outcome-space, and out falls MoE. ie: It seems natural to combine multiple models when making predictions, even for a single predictor (at least when using this betting model for prediction)
There's this (semi-)common qualitative formula for motivation that goes like: M = (V E) / (I D) where M is your motivation toward something, E is your confidence level of getting something from it, V is the combined value of the task and its outcome, I is your distractability, and D is the delay in arriving at the outcome (task length, etc). But -- even though this is just purely qualitative -- and this is extremely minor and stupid, but still: -- you can take the logarithm of both sides and get a linear combination of new, qualitatively-equivalent metrics: M = V + E - I - D. The derivative of this new equation is much simpler: dM = dE + dV - dI - dD. The derivative form can be used to determine which thing you should focus on; for instance if dE > dV then you should prefer increasing your confidence of success rather than increasing the value of the task and its outcome
Note the derivative in the typical form is something like: dM = (dV / V + dE / E - dI / I - dD / D) M, which is significantly more cumbersome. Though, this is all qualitative, not quantitative, so...
Also, note that some studies have estimated human value metrics for money are roughly logarithmic, so there is reason to believe the linear form should be preferred. Though, the original and logarithmic forms aren't compatible if I or D can be 0 (ie: value-less), or if I or D can be negative
You can turn any function with N parameters into N non-additive derivatives:
* Take the regular additive derivative of the function N times, this gives you N equations
* Solve for each of the parameters and your input x across the equations
* The parameters are the derivatives
eg: a x^2 = y
Take the derivative twice
2 a = y''
So we have
a = y'' / 2
We can also solve this by first solving the original equation to get x:
x = +- (y / a)^(1/2)
Then plug that in and solve to get the derivative (squaring removes the +-):
a = y'^2 / (4 y)
Since we have a 'y' in the denominator in that last parameteric derivative, we have singularities, and that's unattractive. Instead lets do this:
eg: a x^2 + b x = y
Take the derivative twice:
2 a = y''
So
a = y'' / 2
Then we can solve the original equation: x = (-b +- sqrt(b^2 + 4 a y) / (2 a))
And take the derivative of the original equation once:
2 a x + b = y
Plug stuff in and solve for b:
b = +- sqrt(y'^2 - 2 y y'')
eg: For the regular additive derivative its really simple:
a x = y
Take the additive derivative:
a = y'
Which is already solved
eg: a^x = y
Solve for x:
x = ln y / ln a
Take the derivative, plug in for x, and solve for a:
a = exp(y' / y)
Which is the regular multiplicative derivative
eg: x^a = y
Solve for x:
x = y^(1/a)
Take the derivative, plug in for x, and solve for a:
a = ln y / W(y ln(y) / y')
This gives you the exponential
eg: sin(a x) = y
Take the derivative twice:
y'' = -a^2 sin(a x) = -a^2 y
Solve for a:
a = sqrt(- y''/y)
Which gives you the equivalent oscillation rate for a 0-phase sine wave best matching your function y

{kind=link}
{kind=link}