

Martin Ruskov @mapto@qoto.org
- Games
- https://mapto.itch.io
- Others (+fedi)
- https://linktr.ee/mapto
Studying how people interact, in the past (#CulturalAnalytics) and today (#EdTech #Crowdsourcing). Researcher at @IslabUnimi, University of Milan. Bulgarian activist for legal reform with @pravosadiezv. I use dedicated accounts for different languages.
My profile is searchable with https://www.tootfinder.ch/
Joined Nov 2022
Today at #CHR2025, I will be presenting our work on the evaluation of the historical adequacy of masked language models (MLMs) for #Latin. There are several models like this, and they represent the current state of the art for a number of downstream tasks, like semantic change and text reuse detection. However, a historical researcher, philologist or else would want to be sure that such models really represent the historical period of interest. For example, it would be an embarrasing hallucination if St. Augustine showed up in the context of the Roman senate.
Our evaluation confirms a known problem: LLMs and masked models in particular are trained on corpora without attention to historical periods. Unlike other research we've done on Early Modern English, this problem leads to models being barely distinguishable when it comes to their ability to generate based on a historical period. Even though history is a case where it is most obvious when models go wrong, this type of contamination is a known problem for LLM training overall, think of different legal jurisdictions using the same language, dialects in programming languages, etc.
This research was generously supported by AgileLab.
The full paper is available at:
https://anthology.ach.org/volumes/vol0003/the-latin-language-evolved-over-time-masked-models/
{kind=link}
I would rather define myself as a #GenAI sceptic (I've documented the reasons in my publications at https://www.zotero.org/mapto/publications), but here's what a professional adopter, i.e a founder of a GenAI startup (that I value lots) has to say about the state of technology. No need to say we diverge on the outlooks, but that's not the point here
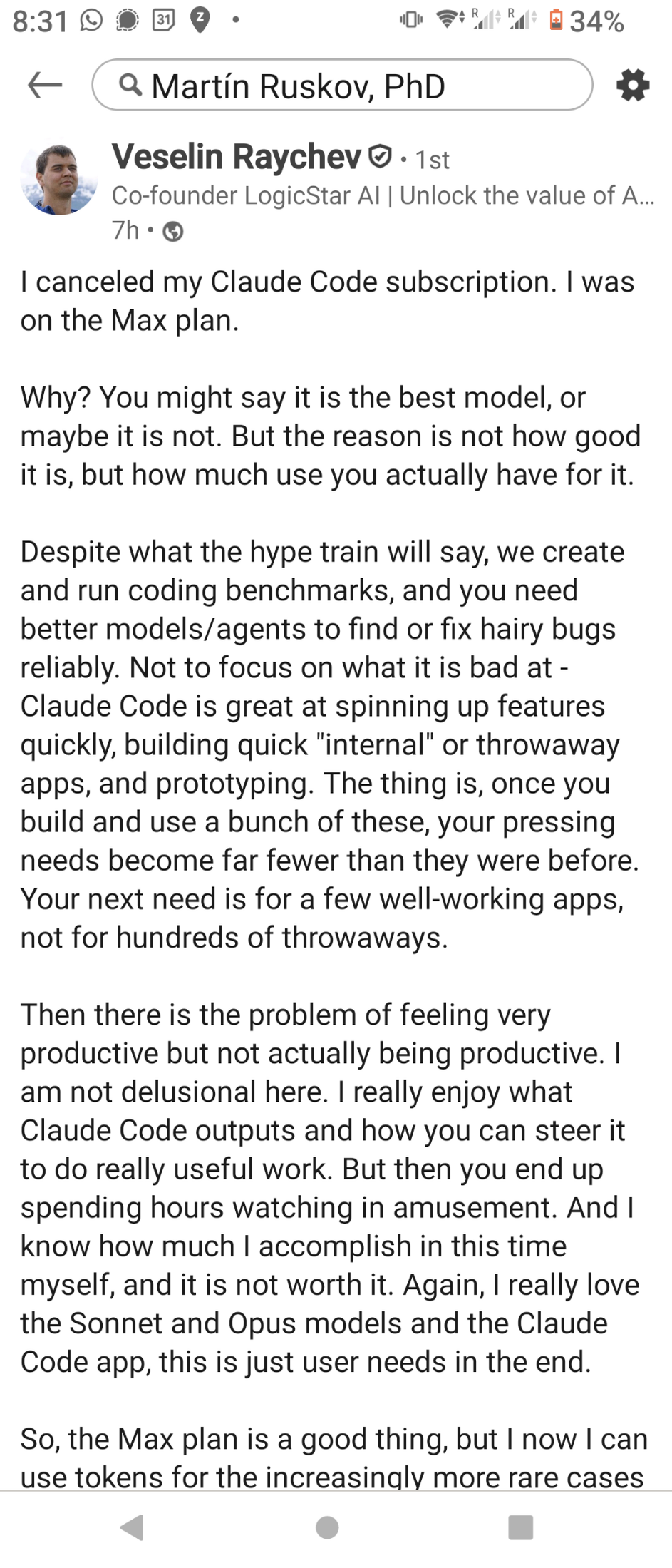{kind=link}
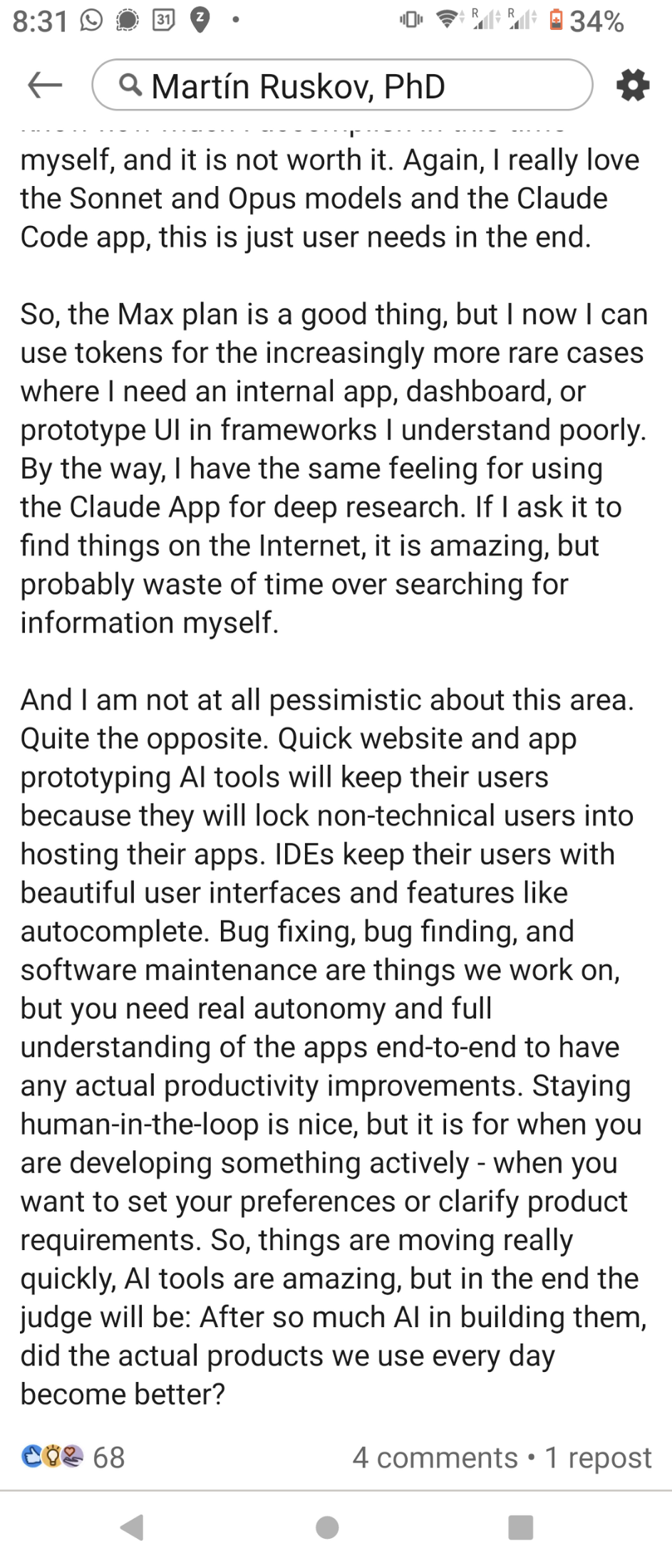{kind=link}
"In a broader sense, however, today’s ruling is of a piece with this Court’s recent tendencies. “[R]ight when the Judiciary should be hunkering down to do all it can to preserve the law’s constraints,” the Court opts instead to make vindicating the rule of law and preventing manifestly injurious Government action as difficult as possible….. This is Calvinball jurisprudence with a twist. Calvinball has only one rule: There are no fixed rules. We seem to have two: that one, and this Administration always wins."
{kind=link}
History keeps repeating, dictators keep pulling each-other's strings.
"In interviews for a book about his Middle East peace efforts, Trump, according to its author, used an expletive to describe the embattled prime minister — “Fuck him,” he reportedly said — and accused Netanyahu of disloyalty."
https://www.timesofisrael.com/trump-posts-clip-of-prof-calling-netanyahu-obsessive-about-getting-us-to-fight-iran/
#Trump #Netanyahu #JeffreySachs #Iran #Israel #Palestine #Lebanon #Syria #Iraq
{kind=link}
Which part of this does not exactly hold for Katz and his involvement in bombing hospitals in Gaza?
Certainly that in the civilised world due process is part of life.
{kind=link}
This is how ruthless the Israeli military complex is
The sign talks of"protecting the state of Israel", remaining silent to the fact that this offensive "protection" actually costs hundreds of thousands of lives in Israel and the region.
Context:
https://www.theguardian.com/science/2025/jun/16/israeli-stands-paris-airshow-shut-down-french-government
#israel #palestina #lebanon #yemen #iran
{kind=link}
{kind=link}
Everything you need to know about Donald Trump: the slide with a summary of the collected evidence for his conviction in NY. Source:
https://www.msnbc.com/rachel-maddow-show/maddowblog/manhattan-da-bragg-closing-slides-trump-rcna157057
{kind=link}
Ruote in spalla, per la salute
(A Milano, stazione Missouri)
Qui #SiScherza alla grande, a livello istituzionale, direi...
{kind=link}
#mediapool.bg want to illustrate an article on bread prices in Bulgaria. What I see is #GenAI overdoing the job.
After having studied how #midjuorney v4 could illustrate fairy tales (for anyone interested, https://qoto.org/@mapto/110111252142814403 ) I really want to research more about what stops GenAI from overdoing it with bread around a baker. The greatest obstacle I encounter is the obscurity of most models that engage with #neurosymbolic. It's practically useless, because the creators of such models prefer to be very secretive about what they do. The one exception reported results that do not seem to be reproducible (https://twitter.com/Birchlabs/status/1602105002448805891).
Image sourced from: https://www.mediapool.bg/kzk-tavanat-za-nadtsenkata-na-hlyaba-e-predizborna-agitatsiya-news359054.html
{kind=link}
@techreview, this article is the perfect illustration of why I quit my subscription. I can understand that somewhere in the world there is some tech nerd who could come up with such an absurd idea. I will never accept that a title like this has to do with any self-respecting tech journalism. And here I see the failure of the entire editorial process of an institution that should know much better. This is only the worst title in a long series of articles lacking any critical reflection about GenAI whatsoever.
{kind=link}
imho, this image - the MAU curve of lemmy is the big news on the #fediverse. While also #mastodon and other platforms experienced peaks last summer, #lemmy is the only one that is consistently on the rise in 2024. Arguably, this is thanks to particular #affordances, like the fact that older posts of wider appreciation do not get overwhelmed in feeds.
More charts at https://fedidb.org
{kind=link}
Our paper on the values found in fairy tales from some European countries has been published. We studied how values are explicitly present in tales from Germany, Italy and Portugal using various NLP techniques, but most notably Word2Vec and Word Embedding with a Compass. We visualise synchronic semantic variation to show certain differences based on observations of the corpus, some of them already observed in previous literature. A discussed example in our findings is how motherhood in Germany is strongly related to generosity, whereas in Italy and Portugal it has stronger relationship to wisdom.
Fulltext available at: https://aclanthology.org/2023.nlp4dh-1.8/
{kind=link}
At the University of Milan we are seeking a research fellow to participate in the “MetaLing Corpus: Creating a corpus of English linguistics metalanguage from the 16th to the 18th century” project:
https://expertise.unimi.it/resource/project/PRIN202223AANDR%5F01
Through archival research and corpus compilation, the project aims to assess the genres and text-types involved in the circulation of linguistic knowledge, and to throw light onto unconventional texts and voices besides the major works and figures on which scholarship has naturally concentrated. The project is divided into three phases 1) collection of texts, 2) building the corpus, 3) lexical extraction and database creation, combining human and computational tools. The core part of our study will involve the analysis of the terminology, discursive strategies and descriptive metaphors used to describe and compare languages in English, in diachronic perspective.
The successful applicant will work with the project team to identify relevant primary materials and build an electronic corpus of texts. The post is for someone with a postgraduate degree in Linguistics, English, Computer Science or related discipline. Candidates may or may not have a doctorate at the time of application. The researcher will have the opportunity to contribute to the project database, work in archives, and develop academic writing in individual and joint papers.
Post: Postdoctoral research fellow, Early stage researcher or 0-4 yrs (Post graduate)
Location: Milan (on-site)
Duration: 18 months, fixed-term/contract
Salary: EUR 21,888 per annum
Closes: 4th January 2024
Interview date: 16th January 2024
Full details and instructions on how to apply: https://www.unimi.it/it/ricerca/ricerca-lastatale/fare-
ricerca-da-noi/assegni-e-borse/bandi-assegni-di-ricerca/bando-di-tipo-b-dottssa-andreani-id-6082
We'd appreciate if you boost or forward to any potentially interested candidates. In case of questions or difficulties with understanding Italian (language or bureaucracy), do get in touch with me or the provided contacts. Further details in the attached file.
{kind=link}
Finally, after a first exploration, one might feel ready to see the big picture, i.e. fusion. Of course after that one might tbacktrack to drill back into particular values.
One way to show multidimensional (nominal data, except for years) that we've found useful is the following graph. But more generally we need visualisation techniques that allow for multidimensional nominal data. For two dimensions heatmaps could be a good candidate. It gets more complicated with more dimensions. Alluvial diagrams could turn handy here
{kind=link}
The second pattern is generalisation. It says we should fix our dimension of interest and and vary anything independent of it. We do this by focusing on individual authors and looking of other dimensions (e.g. the interplay between Italian and UK publishers). In the example here, we consider Vasco Pratolini who is the only author from the above graph that has more than one publisher in both countries. Of course this graph is just a start of an enquiry as to why this occurs. In our case we actually had to look into the archives of publisher exchange to get an understanding, but that's beyond the topic here.
PS: Sorry for the transparent backgrounds of images that don't work well on dark app themes. The graphs can be seen better in the paper which is at the end of this thread
{kind=link}
These patterns of variation consider aspects of phenomenon, which at a simple level could be seen as dimensions of data. The simplest of the three patterns is contrast, the idea that to start understanding a phenomenon one needs, to consider each of its dimensions in isolation (i.e. variating it while keeping others fixed). Our example is from translation of Italian novels from the post-war period into the UK market. We apply contrast on authors. Our way to fix other dimensions is by counting them
{kind=link}
Please do check out our poster on explicit references of values in folk tales where we compare the values (Schwartz) in 3 corpora from three European countries. We evidence how between Germany, Portugal and Italy there are common traditions (emphasis on the values of Universalism, Tradition,...), but also cultural peculiarities, e.g. different ways to convey such values #CHR2023
Full text at https://tales.ko64eto.com/ref
{kind=link}
{kind=link}
Let me share the takeaway from Richard McElreath's keynote (at least for me) #CHR2023
{kind=link}
Happy to be invited to present at the 1st edition of the #AIxEDU workshop held in conjunction with the annual conference of the Italian association for AI #AIxIA https://aixedu.pa.itd.cnr.it
The topic was:
The Need for AI that Helps Teach People How to Learn
A summary is available on the workshop website:
https://aixedu.pa.itd.cnr.it/invited-speakers
The full slides with references:
https://docs.google.com/presentation/d/1o0WWS-KXPpr9h-PY07OGN5m68dapGWtTuVFviHABuSA
{kind=link}
- Games
- https://mapto.itch.io
- Others (+fedi)
- https://linktr.ee/mapto
Studying how people interact, in the past (#CulturalAnalytics) and today (#EdTech #Crowdsourcing). Researcher at @IslabUnimi, University of Milan. Bulgarian activist for legal reform with @pravosadiezv. I use dedicated accounts for different languages.
My profile is searchable with https://www.tootfinder.ch/
Joined Nov 2022
