

Martin Ruskov @mapto@qoto.org
- Games
- https://mapto.itch.io
- Others (+fedi)
- https://linktr.ee/mapto
Studying how people interact, in the past (#CulturalAnalytics) and today (#EdTech #Crowdsourcing). Researcher at @IslabUnimi, University of Milan. Bulgarian activist for legal reform with @pravosadiezv. I use dedicated accounts for different languages.
My profile is searchable with https://www.tootfinder.ch/
Joined Nov 2022
To initiate such a process, I engaged with an investigation following the principles of action research (https://sonyaterborg.com/2016/02/17/action-research/) - an iterative methodology where research and practice go hand in hand. While a task is being completed, in parallel a reproducible process is being developed, lessons learned are being collected.
What does it take to be more rigorous about the composition of prompts? Well, first of all, not only talking about what words are used, but also about how they are chosen, why one choice of words might be better than another? Then, it is important to be careful how features are tried, putting an effort to separate different effects as much as possible. This takes time, but allows for a better understanding of the interplays (https://doi.org/10.1207/s15327809jls1502_2). And this is only for a start of a long reflective practice that allows for the collection of insights that can be valid also across models, hopefully also for models that are yet to come.
With AI text-to-image generator models gaining popularity, there's a lot of talk about #promptEngineering, the process of refining the textual input used to obtain a desired result. However, calling the current practices "engineering" is an exaggeration considering that 1. it commonly limits itself to everyone using their ad-hoc techniques, 2. that are barely validated, and 3. and transferability across models is not even considered. For an overview of practices among #aiartists, consider Jonas Oppenlaender's ethnographic study (https://arxiv.org/abs/2204.13988) He gives a good idea of some of the employed witchcraft, such as quality boosters, repetitions and magic words
Not long ago I presented my experiments on illustrating famous fairy tales with #Midjourney v4 at the #IRCDL23 (http://lacam.di.uniba.it/IRCDL23/) This experimentation is part of the VAST project https://www.vast-project.eu/ that studies values present in different texts, including some fairy tales recorded by the Grimm brothers. My generations were an aside activity, and I attempted to generate 5 illustrations for each of 5 fairy tales: #LittleRedRidingHood, #Cinderella, #LittleSnowWhite, #HanselAndGretel, and #FaithfulJohannes
Martin Ruskov
boosted

On the "sparks" paper:
https://twitter.com/emilymbender/status/1638891855718002691?s=20
On the GPT-4 ad copy:
https://twitter.com/emilymbender/status/1635697381244272640?s=20
On "general" tasks:
https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/084b6fbb10729ed4da8c3d3f5a3ae7c9-Abstract-round2.html
>>
Martin Ruskov
boosted
And could the creators "reliably control" #ChatGPT et al. Yes, they could --- by simply not setting them up as easily accessible sources of non-information poisoning our information ecosystem.
And could folks "understand" these systems? There are plenty of open questions about how deep neural nets map inputs to outputs, but we'd be much better positioned to study them if the AI labs provided transparency about training data, model architecture, and training regimes.
>>
Martin Ruskov
boosted
Okay, so that AI letter signed by lots of AI researchers calling for a "Pause [on] Giant AI Experiments"? It's just dripping with AI hype. Here's a quick rundown.
First, for context, note that URL? The Future of Life Institute is a longtermist operation. You know, the people who are focused on maximizing the happiness of billions of future beings who live in computer simulations.
https://futureoflife.org/open-letter/pause-giant-ai-experiments/
>>
Martin Ruskov
boosted

Join the rally in #SanFrancisco! Big Media is suing to cut off #libraries’ ownership and control of digital books, opening new paths for #censorship & #surveillance.
On 4/8, we rally at 🐦InternetArchive to demand #DigitalRightsForLibraries ✊🏻📚
RSVP: https://actionnetwork.org/events/dont-delete-our-books-rally-in-san-francisco?source=twitter&
An enquiry into photograph smiles and how Midjourney distorts these
RT @hackylawyER@twitter.com
"It was as if the AI had cast 21st century Americans to put on different costumes and play the various cultures of the world. Which, of course, it had."
Great article from @babiejenks@twitter.com https://medium.com/@socialcreature/ai-and-the-american-smile-76d23a0fbfaf
🐦🔗: https://twitter.com/hackylawyER/status/1641157473833762833
At @IslabUnimi@twitter.com we're using bespoke (quantitative) word embeddings as a tool for comparative corpus analysis. I see it as a first step towards better informed critical analysis. Here's an example by @eliroc98@twitter.com and Tommaso Locatelli
http://tales.islab.di.unimi.it/2023/03/27/john2vec-or-embedding-deweys-philosophy/
#DigitalHumanities
RT @emilymbender@twitter.com
But people want to believe SO HARD that AGI is nigh.
Remember: If #GPT4 or #ChatGPT or #Bing or #Bard generated some strings that make sense, that's because you made sense of them.
🐦🔗: https://twitter.com/emilymbender/status/1640414584891928576
RT @george__mack@twitter.com
2. The Rise Of Negative Media
Since 2010, the media massively increased headlines that use fear, anger, disgust, and sadness.
It's no surprise the media isn't covering this 😅
🐦🔗: https://twitter.com/george__mack/status/1640010316468858880
RT @yudapearl@twitter.com
For this reason, GPT's understanding should be tested on questions whose answer is "NO, it is not possible under any circumstances". Such questions are the core of causal logic. e.g., can a drug be good for men, good for women and bad for people? https://twitter.com/yudapearl/status/1640075242470277120
🐦🔗: https://twitter.com/yudapearl/status/1640079735282864131
Martin Ruskov
boosted

{kind=link}
{kind=link}
{kind=link}
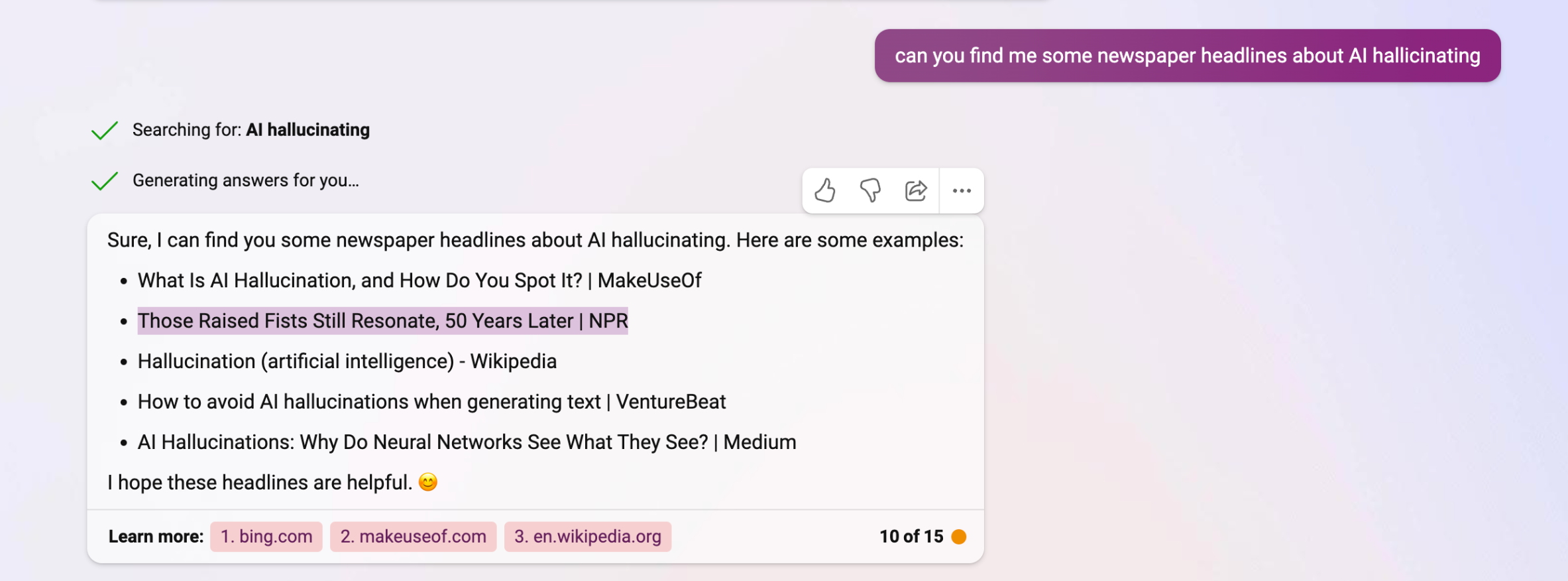
Here's a glitch/bug/massive-fucking-privacy-risk associated with the new #Bing #chatbot feature that I haven't seen documented.
Answers from one query bleed over into another.
Earlier today I asked it about the black power salute that Tommie Smith and John Carlos gave at the 1968 Olympic Games.
Tonight I asked it about headlines referencing chatbot halluncinations.
Look what it did. It returned an utterly irrelevant answer to a previous query.
Amazing this is production technology.
{kind=link}
RT @ProfNoahGian@twitter.com
GPT4 can speak fluently, so maybe it's mastered language in that sense--but to manipulate us it'd need to measure the impact its words have on us, and it cannot. Donald Trump could see what his words do to his crowds of supporters, what actions they took because of his speeches.
🐦🔗: https://twitter.com/ProfNoahGian/status/1639698833276846081
RT @ProfNoahGian@twitter.com
data: we're already training LLMs now on most human written text, so how do we keep increasing this finite supply? Even if we could, how do we know AI capabilities will continue exponentially and not plateau? We don't. They might, they might not: it's an assumption, not a fact.
🐦🔗: https://twitter.com/ProfNoahGian/status/1639698828839329792
RT @ProfNoahGian@twitter.com
Next point I LOVE: "Drug companies cannot sell people new medicines without first subjecting their products to rigorous safety checks. Biotech labs cannot release new viruses into the public sphere in order to impress shareholders with their wizardry. Likewise, A.I. systems ..."
🐦🔗: https://twitter.com/ProfNoahGian/status/1639698816482852865
RT @ProfNoahGian@twitter.com
When I see that X% percent of "AI experts" believe there's a Y% chance AI will kill us all, sorry but my reaction is yeah that's what they want us to think so we are in awe of their godlike power and trust them to save us. It's not science.
🐦🔗: https://twitter.com/ProfNoahGian/status/1639698814503202818
RT @ShannonVallor@twitter.com
The most depressing thing about GPT-4 has nothing at all to do with the tech. It’s realising how many humans already believe they are merely a machine for generating valuable word tokens
🐦🔗: https://twitter.com/ShannonVallor/status/1639631757002547202
България официално е полудяла. Видях само едно заглавие, което още на първо четене не ми изглежда абсолютно безумно. Ще успеете ли да го откриете?
{kind=link}
- Games
- https://mapto.itch.io
- Others (+fedi)
- https://linktr.ee/mapto
Studying how people interact, in the past (#CulturalAnalytics) and today (#EdTech #Crowdsourcing). Researcher at @IslabUnimi, University of Milan. Bulgarian activist for legal reform with @pravosadiezv. I use dedicated accounts for different languages.
My profile is searchable with https://www.tootfinder.ch/
Joined Nov 2022
