

Post @post@qoto.org
#Mathematics #Macroeconomics #Engineering #ComputerScience #Programming
#Ecology #Environment #Democracy #Freedom #Equity #Liberal #Socialism #PostKeynesian
![]() #Inkscape ·
#Inkscape · ![]() #Gimp ·
#Gimp · ![]() #Blender ·
#Blender · ![]() #VLC
#VLC
![]() #WordPress ·
#WordPress · ![]() #Mastodon ·
#Mastodon · ![]() #PeerTube:
#PeerTube:
![]()
![]()
![]()
![]()
![]()
![]() searchable
searchable
Joined May 2019
Post
boosted

@hobs Here we’ll have to agree to disagree. AGI is IMO very much not a thing. I’m with Gary Marcus and Yann LeCun that LLMs are likely an off-ramp away from AGI, not a path towards it. And I’m with Timnit Gebru and Emily Bender that nothing in current LLMs hints at AGI.
These models are useful language tools but using them as thinking tools is IMHO a very bad idea.
But I agree that the EU might feel compelled to degrade consumer protections out of a fear of losing out on AGI.
Post
boosted
6. OpenAI is run by people involved in the tech startup scene for years if not decades. Given how many companies they’ve been involved with, it simply isn’t plausible that a competent executive in their position didn’t know about the company’s obligations towards the GDPR. They absolutely should have known better before they started training on personal data, which means there’s reason for regulators to believe that the violations are intentional.
Post
boosted
3. Removing memorised data from an LLM risks destroying it. Even though “machine unlearning” is a fast-moving topic and we don’t even know if it could work for a system as large as GPT-3/3.5/4 and it might even trigger “catastrophic forgetting” of unrelated data.
4. AFAICT, OpenAI never tried to get informed consent for adding user-provided prompts to their training data sets.
5. OpenAI does not support the right of erasure in any case.
Post
boosted
How this affects LLMs:
1. LLMs have a tendency to memorise data. Not all of it and not in a predictable way, but any time it answers a question like “who was the first person on the moon” with “Neil Armstrong” that isn’t pulled out of the ether. Memorisation also goes hand-in-hand with performance. So, these systems definitely do make copies of training data, we just can’t predict which bit it copies and which it doesn’t.
Post
boosted
Crash course in GDPR compliance, because it’s been obvious that the Americans have some misconceptions:
Remember, though: IANAL and this is not legal advice
1. The GDPR does allow data collection of arbitrary stuff of the internet, such as for search engine indexing, but it must be for a single, specific purpose so that owners of personal data that’s been indexed can take an informed decision. A system that’s specifically advertised as general-purpose is pretty much automatically disqualified.
#Logseq team setup a Feature Request category in the official forum and users are prompted to vote FRs there.
For a long time the top ones are: epub annotations, vim shortcuts, longform writing, custom todo/done/doing keywords and filters for page content and not only references section.
All of these (except maybe vim shortcuts) perfectly align with what Logseq provided so far in my opinion.
I see no development on GitHub about these, the team develops privately, the only thing we have is an outdated Trello board that has never been respected nor actual new features are listed there. It looks like the board of a Logseq from a parallel universe.
But now I see an "AI" branch on GitHub by the founder and lead developer that it seems a deep integration of Logseq with OpenAI services. To my knowledge no one made a Feature Request for it. It looks like they are focusing on what they want or what they expect people to like, ignoring the feedback system they setup.
CC @logseq
Given the points above and the fact I backed #Logseq for a long time but addressing these issues may require *years* and maybe the project won't survive anyway that long, what should I do? Move to a simpler but better supported system like #Emacs or wait and hope Logseq team figure out priorities?
Recent "AI" (sigh) native integration in Logseq (using OpenAI according to a GitHub branch of theirs, again zero communication by the team) lower my hopes a lot.
If they take money from people they should make clear what it will be used for.
Post
boosted

The Robot framework syntax highlighting for KDE is now merged!
https://invent.kde.org/frameworks/syntax-highlighting/-/merge_requests/474
Post
boosted

Post
boosted

The latest #logseq Times edition has been posted and is available
https://ednico.medium.com/logseq-times-2023-04-16-logseq-0-9-2-f240ecbc4fd9
- Logseq 0.9.2,
- Logseq Vision update,
- Chat-GPT and Logseq,
- Command Palette,
- Reviews,
- Requests and Plugins
Special mention to @post for such a great review on Logseq. Hope you do not mind that I included it.
Thanks in advance.

My problem is not really with #Logseq or other #PKM or #TfT apps but with the silos most apps are and how much effort it requires to build and maintain "bridges" between these silos i.e. the integrations everyone look for when evaluating a software solution.
Storing notes in a standard format like #Markdown is a step in the right direction but we need more standard protocols and formats and more OS-level integrations.
The OS should take care of stuff like contacts, calendar, indexing files etc and let applications transparently access them. This approach has been explored by #KDE for example with Kontact, Akonadi, Baloo and more.
I should be able for example to login into Mastodon from my system settings and 1) receive native notifications 2) being able to share a note or a image to Mastodon without opening a full client 3) found my bookmarked toots in my PKM app of choice 4) see my followed and following accounts in an ad-hoc category in my contacts and so on.
Too much work is required now, like "in which service did I save that thing?" because we have no unified search (well again KDE's Krunner does its best with this concept) or again "where can I contact that person? In which format the resource must be for that platfom?"
From this perspective projects promoting themselves as "Everything OS" while just being the n-th low-code platform like #Tana are laughable.
#Logseq honest review
🟢 #FOSS with AGPL license (in theory)
🔴 In reality it depends on a closed source module responsible for sync, dubious legality and misleading
🟡 Developed almost privately by a Venture Capitals funded company but accepting small contributions on GitHub and donations on OpenCollective
🟢 Store notes in #Markdown (or in less supported #OrgMode) locally
🟡 Forces indented lists in .md files and it doesn't support normal paragraphs at all
🟡 Introduces syntax that breaks Markdown in a very bad way instead of using code blocks where possible (in Advanced Queries?)
🟡 Based on Electron, NodeJS and NPM
🟡 UI and business logic mixed together, it forces you to always run the whole UI, including for sync
🟢 Available for Linux on FlatHub (unofficially)
🔴 AppImage is the only officially supported way to install on Linux
🟡 No official reproducible builds but unofficial Flatpak ones are reproducible
🟡 Not in F-droid (and the closed source sync feature wouldn't be allowed there anyway), you have to grab their APK manually or automatically
🟢 Supports Wayland but not by default
🟢 Custom CSS
🟡 Fixed UI, no tabs, no split view
🟡 Multi-window means multiple conflicting whole instances
🟢 Plugins platform
🔴 Plugins marketplace based on GitHub
🟡 Poor integration of plugins especially from UI/UX PoV
🟢 Very interesting concept of PDF annotations
🟡 PDF annotations not stored in the .pdf as standard annotations
🟡 PDF annotations stored in their own .md files with odd names
🟢 LaTeX formulas support
🟡 No native PDF export and in general problematic
🟡 Too many menus, command palettes and other redundant UI elements
🟢 Queries with simple syntax and UI
🟡 Advanced Queries are too often needed
🟢 Datalog query language in Advanced Queries
🟡 Very broken aliases feature
🟡 Inconsistent requirements of capitalize, lowercase etc in query syntax and elsewhere that even break some functionalities
🟢 Macros
🟡 Macros don't work with most syntax, including Advanced Queries
🟢 Supports HTML and Hiccup syntax
🟢 Supports embedding Web pages using iframes
🟢 Sync is e2e encrypted
🔴 The code for e2e encryption can't be audited because it is closed source
🟡 Tons of functionalities must be configured by editing a EDN file that it is very easy to break
🟢 Forum based on Discourse
🔴 Use (and abuse) of Discord, even release announcements are made there
🟡 Some Matrix bridges
Concept: 8/10
Execution: 5/10
CC @logseq
Post
boosted
You can see what the “let’s pause new AI work because AI is too dangerous” letter is for when you look at mainstream and local news coverage. It’s all about hypothetical harms by theoretical future products. It’s sucked all of the oxygen out of the room for discussion on current harms by existing tech.
(Local news here in Iceland fell especially hard for this nonsense.)
Post
boosted

The ODF file formats like .odt used by Libreoffice and more are just ZIP files containing a XML file and attachments.
Is there an equivalent for #Markdown containing one or more .md files and media like images? For example .mz extension but it's a just a ZIP.
It would be exported by Markdown editors and imported by online publishing services, for example.
I searched but I can't find anything. Please reshare
#PKM #Logseq #Zettlr #Obsidian #MarkText #GhostWriter #MindForger #Apostrophe #Notae
Post
boosted
For those who miss folders in #Logseq, here there is an example of hierarchy created manually in the outliner; notice how you are not limited to pages as leaves nor folders as text strings; everything can be everything.
The hierarchy can be browsed by clicking on bullet points and the breadcrumbs behave like the one of a file manager.
🧵👇🏻 #pkm
"I am ashamed to be a European" — MEPs slam #EU for silence on #NordStream blasts
Post
boosted
Post
boosted

{kind=link}
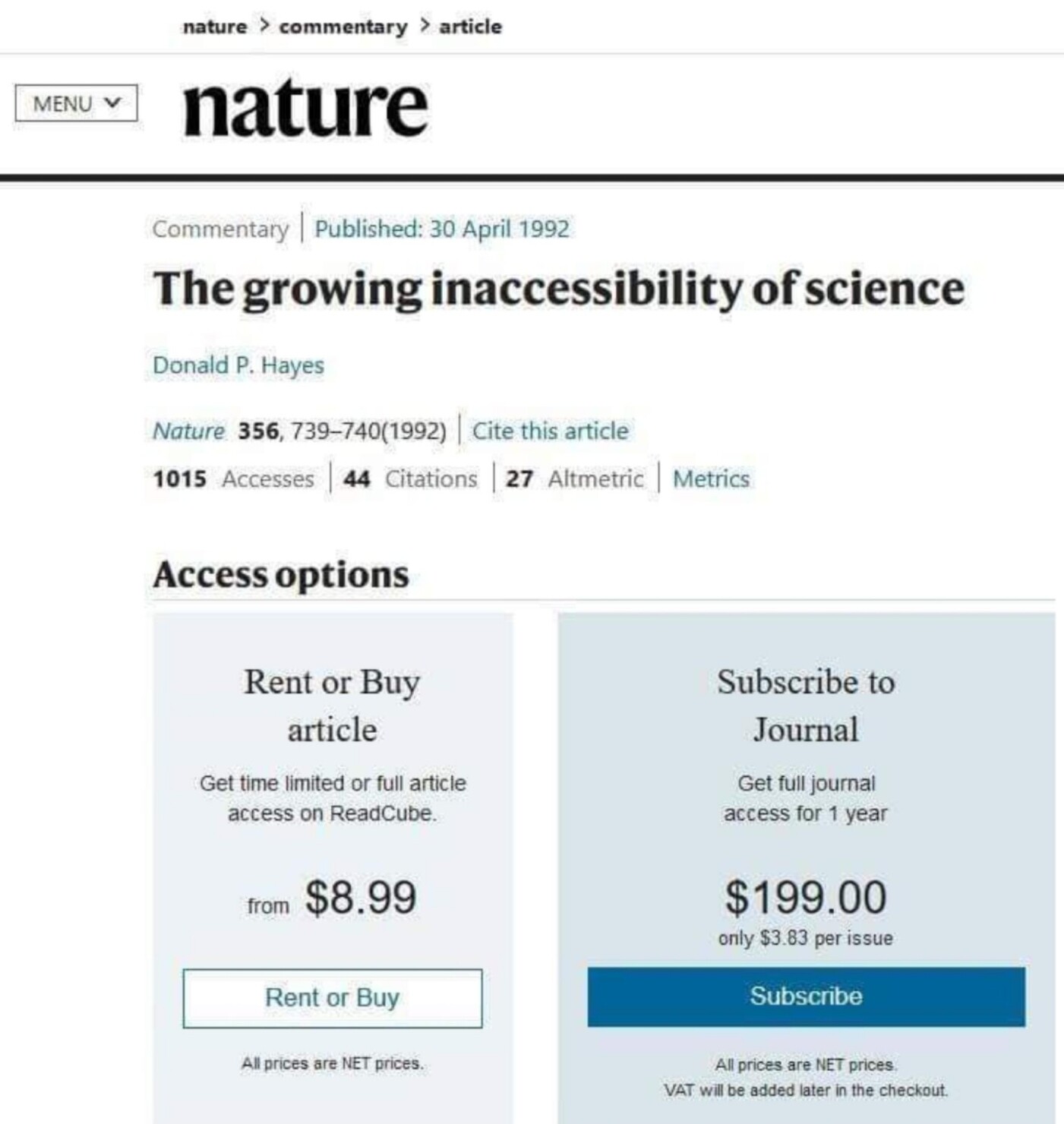{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Because we love open source software (and because they have fast review times), we’ve released our updated browser extension on @mozilla.
The new extension allows you to set labels and edit titles when saving items.
Coming to other browser later this week.
Post
boosted
{kind=link}
#Mathematics #Macroeconomics #Engineering #ComputerScience #Programming
#Ecology #Environment #Democracy #Freedom #Equity #Liberal #Socialism #PostKeynesian
![]() #Inkscape ·
#Inkscape · ![]() #Gimp ·
#Gimp · ![]() #Blender ·
#Blender · ![]() #VLC
#VLC
![]() #WordPress ·
#WordPress · ![]() #Mastodon ·
#Mastodon · ![]() #PeerTube:
#PeerTube:
![]()
![]()
![]()
![]()
![]()
![]() searchable
searchable
Joined May 2019
