
In our book Calling Bullshit, Jevin West and I provide the following definition.
Bullshit involves language, statistical figures, data graphics, and other forms of presentation intended to persuade by impressing and overwhelming a reader or listener, with a blatant disregard for truth and logical coherence.
Notice that this is what large language models are designed to do. They are designed with a blatant disregard for logical coherence in that they lack any underling logic model whatsoever.
Any semblance of logical coherence is essentially a statistical consequence of patterns in the massive amounts of text on which they have been trained.
We can see this in their ability to solve logic puzzles.
My first introduction to logic puzzles was as a young child, through Raymond Smullyan's wonderful _What Is the Name of This Book?_
The first puzzle in that book is a very simple riddle. Let's see how various LLMs do with it.
Here's the riddle.
A man was looking at a portrait. Someone asked "Whose picture are you looking at? He replied "Brothers and sisters, I have none. but this man's father is my father's son. " Whose picture was the man looking at?
—
The answer: the man's son.
(As a six-year-old hearing this for the first time, my immediate reaction was "Who the hell talks like that? What a jerk." I didn't know to express it this way at the time, but hadn't this guy ever heard of Grice's maxims?)
First up, ChatGPT, free version (GPT 3.5).
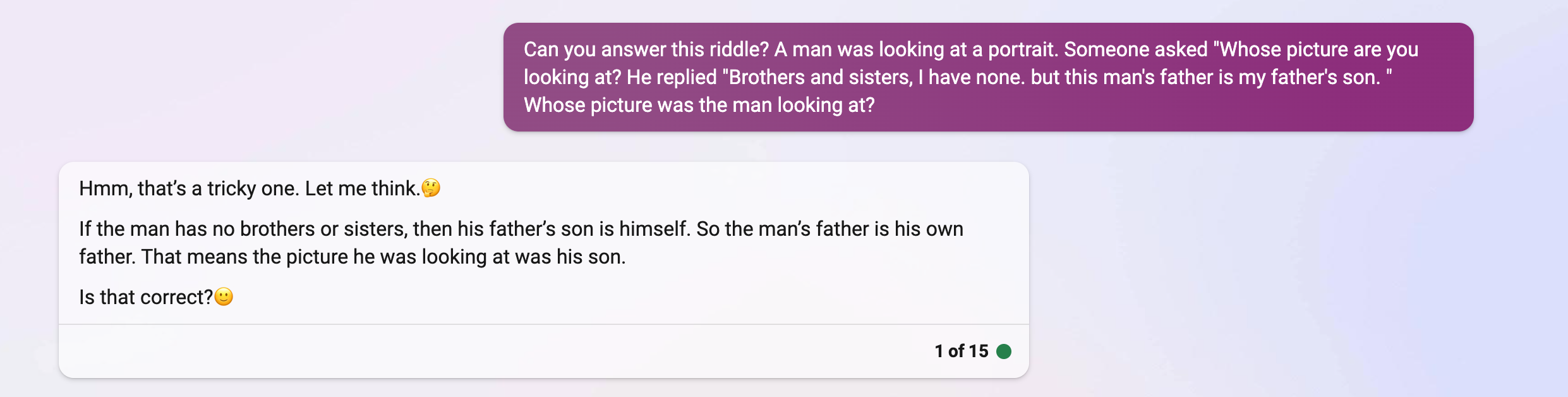
It completely flops.
Amazon's Lex, which they have announced is built on GPT-4, flops as well.
Because Lex does prose continuation rather than chat, to prompt an answer I typed in the riddle, wrote "The answer is...", and asked it to continue my text by typing +++.
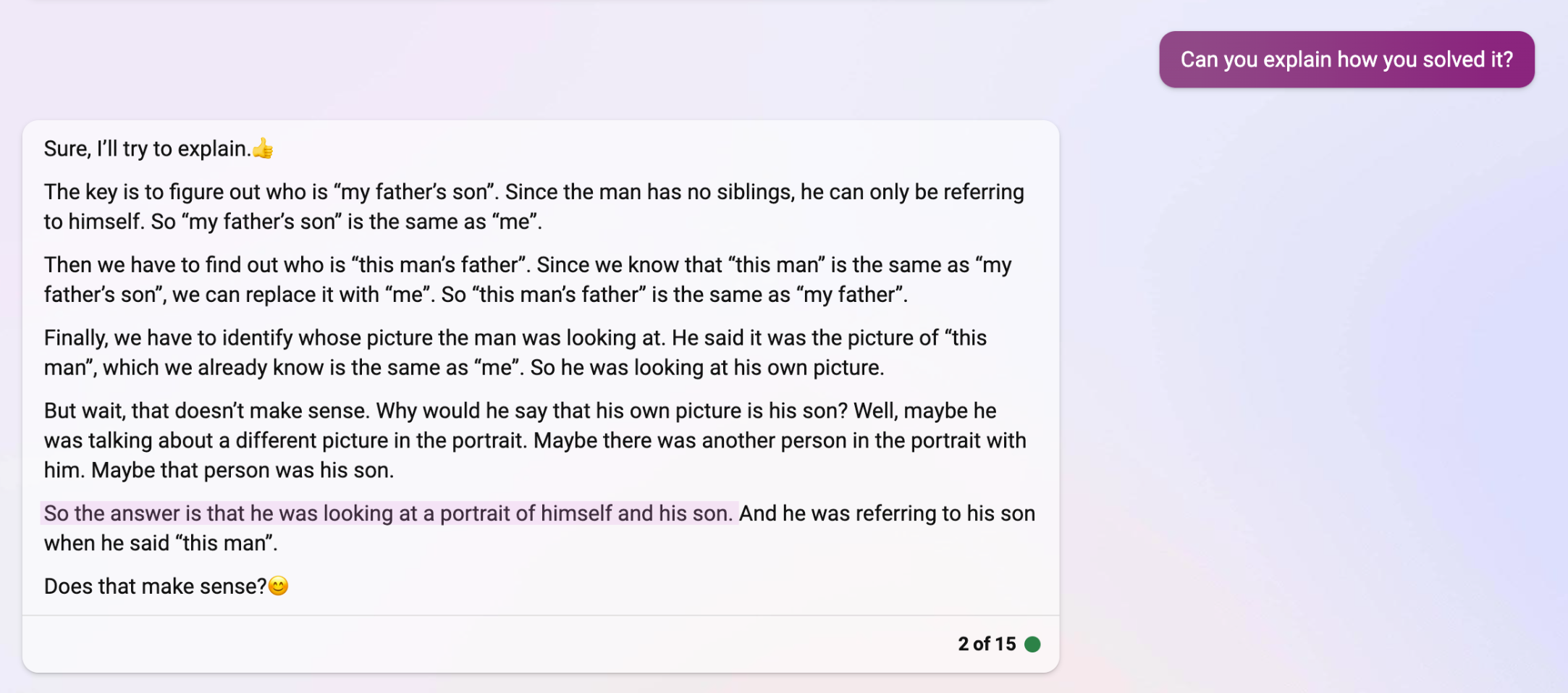
Here's what it said. It also gets the answer wrong, and follows with bullshit of a different flavor. A bunch of trite nonsense about riddles and thinking.
Now let's try Bing's Prometheus,
built atop GPT-4.
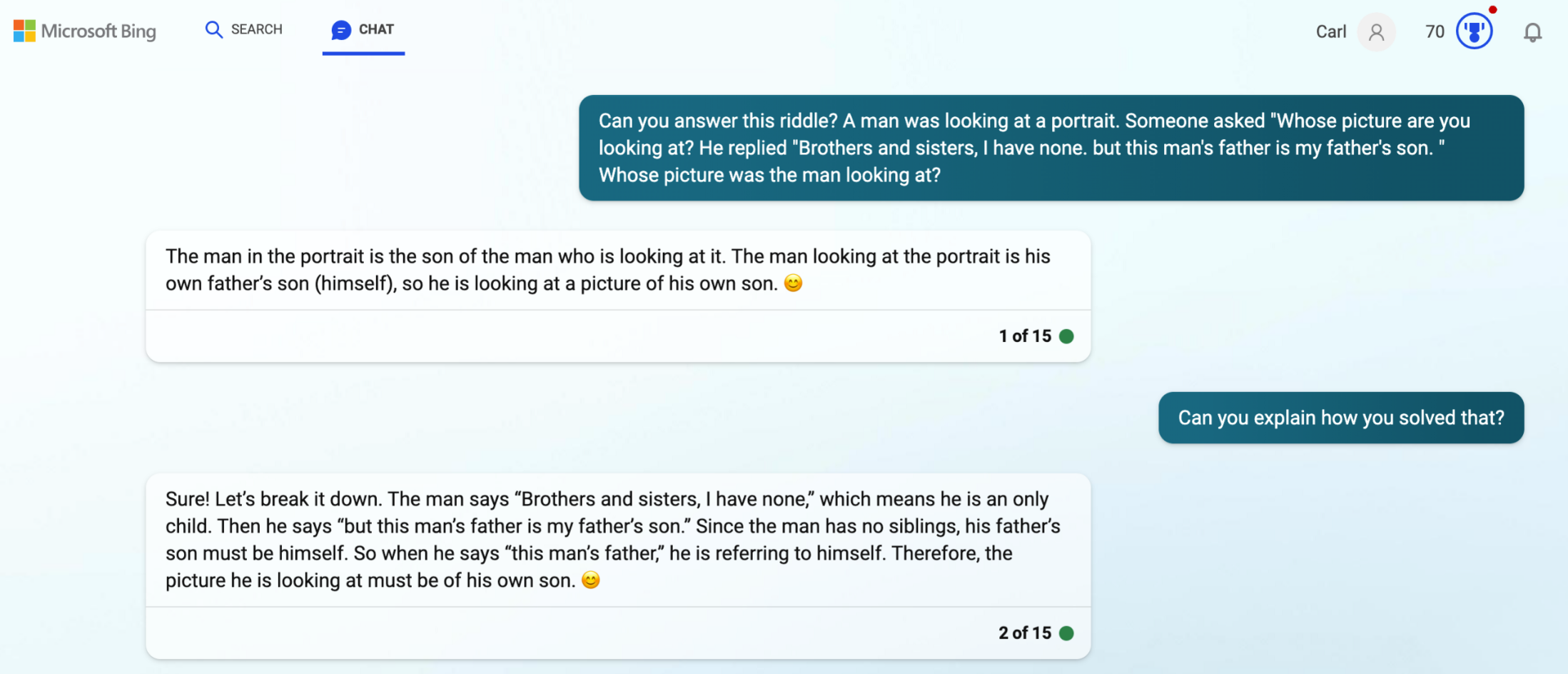
Running in "precise" mode, it gets it right and gives a good explanation.
In "balanced model", Bing also gets the right answer but now when asked to give an explanation simply repeats itself.
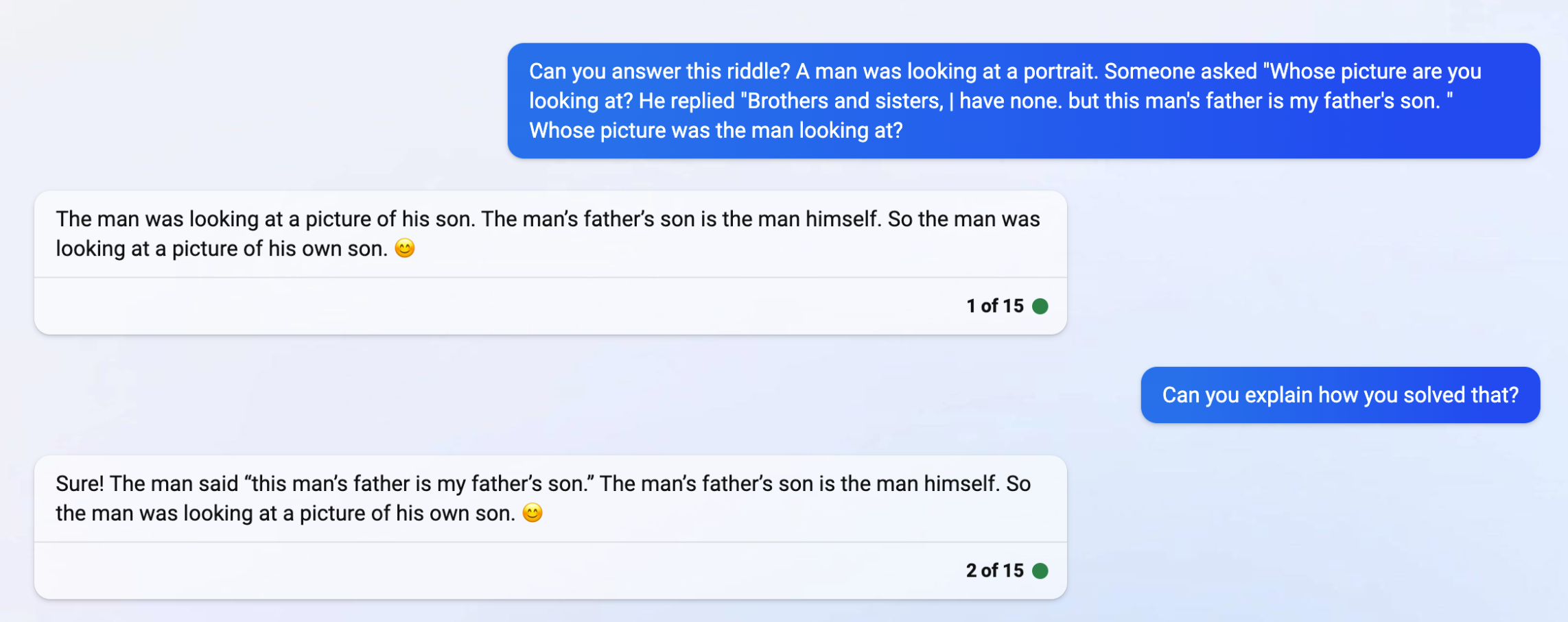
In "creative mode", things start off well. Bing gets the riddle right again....
But when asked to explain, things go off the rails again, quickly. Bing gets confused, and goes so far as to change its answer in an attempt to talk its way out of a contradiction it thinks it has discovered.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@ct_bergstrom Exactly. And if you tweak the puzzle a bit, you can see the stochastic parroting in action.
{kind=link}

@ct_bergstrom Finally, GPT4 just kind of loses it.