
Continued: it's striking that the authors didn't even use conventional machine learning procedures to develop their classifier.
Rather, they chose features that made sense to them as indicators.
These were not even indicators of fake papers, but rather indicators of non-response to a survey —which of course is a very different thing than authorship of a fake paper.
The mind just boggles.
"Note that the tallying rule [private email, no international collaborators] identifies likely fakes, but it cannot determine with certainty whether a given publication is actually (legally) a fake. Nevertheless, it is a reliable tool to red-flag scientific reports for further analysis and is a rational basis to estimate the upper value of fake publishing in biomedicine."
RELIABLE TOOL?
RATIONAL BASIS?
And then there's this:
"It is important to keep in mind that our indicators provide a red flag, not legal proof, that a given manuscript or publication might be fake. However, it is the authors' burden of proof to demonstrate that their science can be trusted."
BULLSHIT.
It is absolutely not the authors' burden of proof to demonstrate that their science can be trusted when the criteria used to question their work are (1) their email address and (2) the lack of international collaborators.
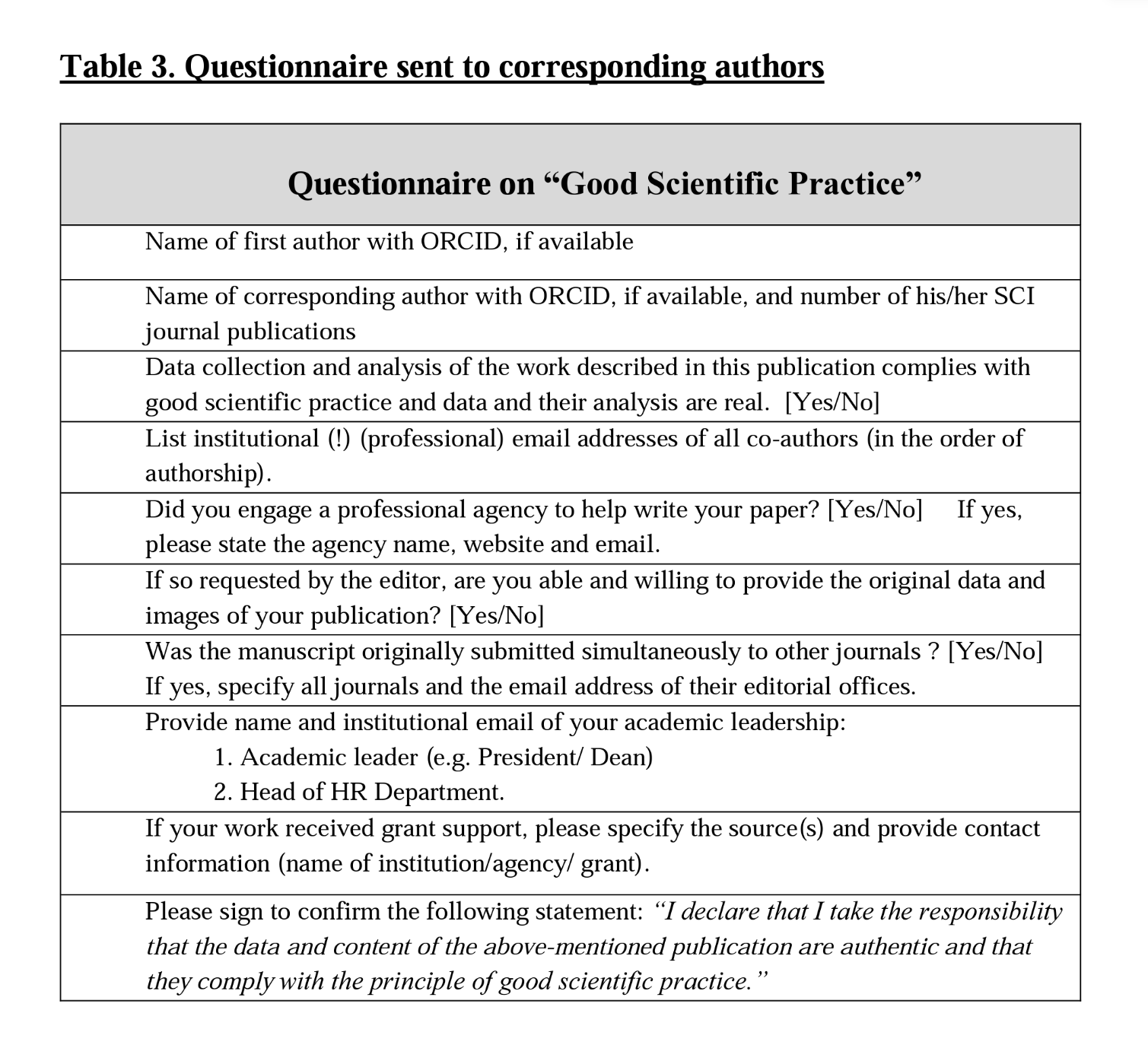
And then there's the survey they used to "validate" their hopeless instrument.
How would you respond if you received this from some random account?
As a misinformation researcher, I get all sorts of politically motivated harassment that looks a lot like this.
Last thing I'm going to do is give them information they could look up themselves about my dean, HR people, etc.
To presume that not answering implies guilt is outrageous.
Finally, I want to stress that it is no defense whatsoever to say that the algorithm could be used simply as a preliminary screen to red-flag papers for additional scrutiny.
If one is going to propose machine-learning classifier to make instrumental decisions that affect careers and reputations, one must carefully and thoroughly consider issues of fairness and risks algorithmic harm that might arise.
The authors of this preprint don't even mention such issues.
Not only does the Science story fail to call them on this; its author falls into the one of the oldest and most pernicious traps around algorithmic bias.
The author contrasts the use of "automated methods" with reliance on "human prejudice", entirely overlooking the fact that the automated methods propose here are nothing but the explicit and fully-descirbed instantiation of human prejudice.
It's truly an embarrassment all around.
UPDATE: The paper is now discussed on pubpeer, and the lead author has responded.
I find his response to be a completely unsatisfactory effort at misdirection, but read it and decide for yourself.
The irony of this guy writing a paper that spectacularly overestimates the frequency of fake papers using ridiculous methods and then saying "The loss of trust in science is the key issue we should worry about."
https://pubpeer.com/publications/0CE23D5DD5AD6929404AF03D700623

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
@ct_bergstrom This partially explains their thinking - Gigerenzer is a proponent of something called "fast-and-frugal trees" which appear to just be simple decision trees. Maybe there's more to it. https://en.wikipedia.org/wiki/Fast-and-frugal_trees
