

Shamar @Shamar@qoto.org
Joined May 2019
Shamar
boosted

Che una sede di pubblicazione sia scientifica per l'#ANVUR solo se si organizza in fascicoli, e che dunque Open Research Europe non lo sia può sembrare una bizzarria burocratica, ma non lo è.
La #valutazione di stato, essendo #bibliometrica, ha bisogno che tutta la discussione scientifica sia marchiata e ingabbiata in riviste, e per questo motivo deve scoraggiare i ricercatori dal tentare strade alternative, perfino quando sono promosse dalla commissione europea.
Shamar
boosted

Negli elenchi aggiornati delle riviste dichiarate scientifiche dall’ANVUR continua a mancare Open Research Europe (ORE), infrastruttura di revisione paritaria aperta offerta dalla Commissione dell’Unione Europea agli autori i cui lavori di ricerca sono esito di finanziamenti europei. Visti i precedenti, questa assenza non sorprende. Ed era anche già chiaro che la recente “Disposizione […]
Shamar
boosted

I attended the EDPB event on #PayorOkay models and left deeply concerned. The discussion lacked acknowledgment of data protection as a fundamental right and ignored clear GDPR principles making the model unlawful. Instead, it conflated ads with core services, sidelining fairness and rights. Surveillance ads harm individuals and society, yet their ‘value’ is overstated. We must reclaim the debate: data protection is key to human dignity and a rights-respecting digital future.
Shamar
boosted

I'm glad to announce the release of version 2.63 of #snac, the simple, minimalistic #ActivityPub instance server written in C. It includes the following changes:
The server can now act as a proxy for all image, audio or video media coming from other account's posts (both from the Web UI and the Mastodon API). This way, other servers will see media requests coming from the server IP, not the user's, improving privacy. This is controlled by setting the
The
Fixed a crash when posting from the links browser.
Fixed some repeated images from Lemmy posts.
Fixed a crash when posting an image from the tooot mobile app.
Updated FreeBSD rc script: the server process is now managed by the daemon(8) utility (contributed by @stefano@bsd.cafe).
RSS feeds are now in 2.0 version instead of 0.91.
https://comam.es/what-is-snac
If you find #snac useful, please consider contributing via LiberaPay: https://liberapay.com/grunfink/donate
#snacAnnounces
This release has been inspired by the song New Moon (Dark Phase) by #DuranDuran.
The server can now act as a proxy for all image, audio or video media coming from other account's posts (both from the Web UI and the Mastodon API). This way, other servers will see media requests coming from the server IP, not the user's, improving privacy. This is controlled by setting the
proxy_media boolean field to server.json to true.The
strict_public_timelines option introduced in the previous release now works correctly.Fixed a crash when posting from the links browser.
Fixed some repeated images from Lemmy posts.
Fixed a crash when posting an image from the tooot mobile app.
Updated FreeBSD rc script: the server process is now managed by the daemon(8) utility (contributed by @stefano@bsd.cafe).
RSS feeds are now in 2.0 version instead of 0.91.
https://comam.es/what-is-snac
If you find #snac useful, please consider contributing via LiberaPay: https://liberapay.com/grunfink/donate
#snacAnnounces
This release has been inspired by the song New Moon (Dark Phase) by #DuranDuran.
Shamar
boosted

@knowprose @sj Thanks for sharing this, it's good to know there's a sizable community that is unhappy with how OSAID got rolled out.
Shamar
boosted

@sj @jaredwhite Through LinkedIn, I got invited to this discussion area regarding the topic... So I'm passing it along.
I haven't had enough contiguous time yet to chime in, but I will.
*Dusts off penguins and Gnus*
Let's suppose you have to teach C to 7yo kids.
Where do you start from?
How do you setup their playground?
(please, don't question the goal in this thread... let's focus on solutions)
As I look openssl compiling, I wonder if we should surrender to C, and just find a way to teack kids how to program in C.
If you avoid malloc, it's not even such a terrible language...
Or I'm just too old and corrupted?
Shamar
boosted

Schneier joins the criticism of "Open Source" AI:
Shamar
boosted

More people in the Open Source community ought to read this: https://archive.is/paD1W
h/t @Shamar (via LWN)
tl;dr: OSI’s behaviour is even worse than we thought
(And apparently Fakebook was one of the driving forces behind this… and still there are idiots on Fedi who want to connect with them. Bah!)
Shamar
boosted

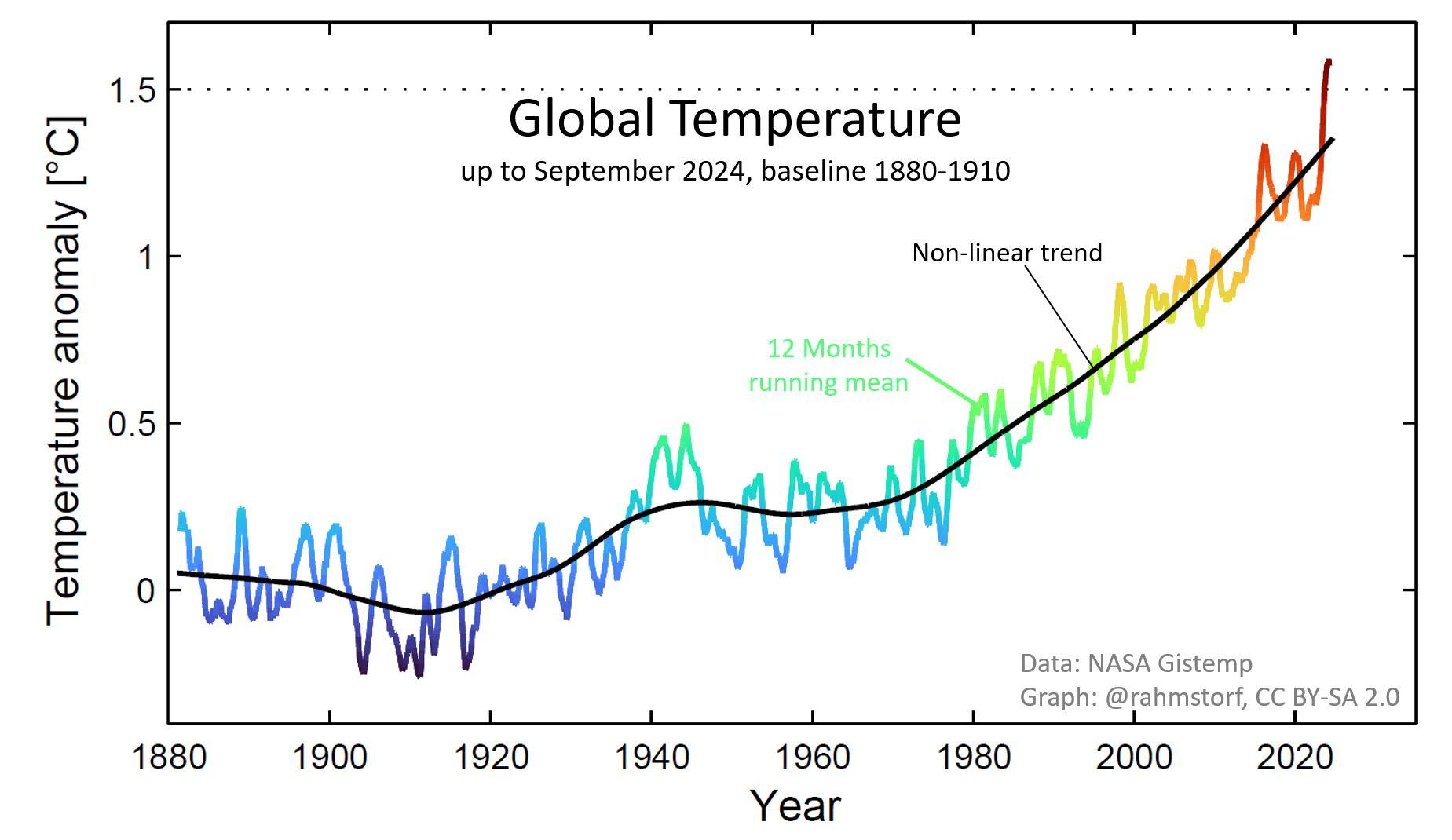
Latest NASA global temperature data.
Earth has never been hotter since Homo sapiens (we) discovered agriculture in the early Holocene. Likely even since the Eemian interglacial 120.000 years ago.
Fossil coal, oil and gas emissions caused it.
We need to stop making it worse.
Yes, we can if we want to.
Shamar
boosted

I remember Google+, and the idee fixe and mad hype around it. (Google was afraid of Facebook.) G+ was a ghost town. But for the first year or so the G+ team reported astronomical engagement numbers. Huhh?
Finally we learned they were counting every G+ notification dropped at the top of Gmail as an "engagement."
Anyway, I wonder how they're measuring this...
https://www.businessinsider.com/google-earnings-q3-2024-new-code-created-by-ai-2024-10
Shamar
boosted
Ospedali o cannoni? Scuole o cannoni? Cannoni o democrazia?
"In Cina o Russia l’investimento militare va a cascata su strutture legate allo Stato e al potere. In Occidente invece trasferisce enormi fondi pubblici ai grandi interessi privati. Le multinazionali delle armi hanno tra i principali azionisti le società globali dei fondi: #Blackrock, #Vanguard, #StateStreet, #Kkr. Questi colossi si stanno comprando pezzi d’Italia e sono anche i veri padroni delle aziende di #armi. Anche l’Italia sta finendo in quest’orbita: il governo Meloni ha dato via libera a Blackrock per entrare in Leonardo sopra il 3% senza esercitare il golden power. Così i grandi fondi danno soldi ai governi comprando pezzi di Paese ma poi chiedono un ritorno, fanno affari con le armi e coi guadagni poi comprano altri pezzi di Paese. Entra in casa chi poi comanderà alla faccia della democrazia, come già avviene negli Usa e in Gran Bretagna."
https://archive.is/7r4zT
Shamar
boosted
#Debian classify the kind of #AI systems that the #OSI's #OSAID defines as #opensource, as #ToxicCandy: https://salsa.debian.org/deeplearning-team/ml-policy/-/blob/master/ML-Policy.rst
Without training data you cannot ecercise the freedom to study a #ML system and your ability to modify it is severely limited to fine tuning.
Which is like to say that windows is open source because you can tweak the registry.
For these reasons some open source developers are already moving beyond OSI: https://opensourcedeclaration.org
You are welcome to join!
It's not just matter of securing the #OSD, but to update it with a truly open process, with all developers, artists, musicians, data scientists... who contribute their time and valuable skills to open source: https://opensourcedefinition.org/wip/
Shamar
boosted

"Still, it’s unclear whether “Just Go Independent” is a sustainable career path for the number of journalists who we need to have a functioning society. But I do know that relying on the passing interest of billionaires to keep journalism alive is not sustainable. And I know that 250,000 subscribers could fund a lot of independent journalists."
(Original title: The Billionaire Is the Threat, Not the Solution)
https://www.404media.co/the-billionaire-is-the-threat-not-the-solution/
Shamar
boosted

They posit you can still modify (tune) the distributed models without the training source. You can also modify a binary executable without its source code. Frankly that's unacceptable if we actually care about the human beings using the software.
A key pillar of freedom as it relates to software is reproducibility. The ability to build a tool from scratch, in your own environment, with your own parameters, is absolutely indispensable to both learning how the tool works and changing the tool to better serve your needs, especially if your needs fall on the outskirts of the bell curve.
There's also the issue of auditability. If you can't run the full build process yourself, producing your own results from scratch in a trusted environment to compare with what's distributed, it becomes exponentially harder to verify any claims about how a tool supposedly works.
Without the training data, this all becomes impossible for AI models. The OSI knows this. They're choosing to ignore it for the sake of expediency for the companies paying their bills, who want to claim "open" because it sounds good while actually hiding the (largely stolen and fraudulently or non-consentually acquired) source material of their current models.
Do we want a new definition of "open source" that actively thwarts analysis and tinkering, two fundamental requirements of software that respects human beings today? Reject this nonsense.
#OpenSource #OpenSourceAI #OSI #OpenSourceInitiative #FreeSoftware #AI #GenAI #GenerativeAI
Shamar
boosted
As for the #OSAID, it could have required something like the #CDLA (Community Data License Agreement) by the #LinuxFoundation for the AI/ML/LLM training data, or started establishing equivalency classes like it did for programming language source code licensing.
That it didn't, and doesn't even recommend it, is ... disappointing, and falls short of even the open-washing it did for less protective licenses in the past.
Shamar
boosted

🚨 Please take a moment to SIGN ✒️ and SHARE 📢 the #OpenSourceDeclaration to protect #OpenSource from damaging forks that undermine the four essential freedoms of free software on which modern society is based: to Use, Study, Modify, and Share it:
Shamar
boosted

{kind=link}
Il diniego di Bezos alla presa di posizione del Washington Post riguardo le prossime elezioni e' aperto al pubblico.
la risposta dei suoi editor critici della decisione, è dietro paywall.
dai paladini della libertà di espressione è tutto, a voi studio.
p.s. fortunatamente ci sono modi per aggirare il paywall.
la risposta e' leggibile qui
https://archive.is/JX3fp
Joined May 2019
