

Bibliolater 📚 📜 🖋 @bibliolater@qoto.org
Not a bot, just a chap in his fifties who occasionally reads things.
Toots are humanities, science, non-fiction, books, maps, charts and graphs related. Some toots containing videos may also find their way into the timeline.
Toots or follows or boosts or mentions ≠ endorsements of any particular notion or notions.
Finis
Joined Nov 2022
Bibliolater 📚 📜 🖋
boosted

Will The Washington Post Embrace the AI Slush Pile? https://www.theatlantic.com/ideas/archive/2025/06/washington-post-ai-opinion/683064/?utm_source=feed
📸 🇳🇴 **King Harald Hardrada**
#Image attribution: Lerwick Town Hall, CC0, via Wikimedia Commons. Page URL: https://commons.wikimedia.org/wiki/File:Haraldhardrada.jpg. https://commons.wikimedia.org/wiki/File:Haraldhardrada.jpg.
Bibliolater 📚 📜 🖋
boosted

#Earthquake 23 km SE of #Ierissós (#Greece) 19 min ago (local time 15:46:20). Updated map - Colored dots represent local shaking & damage level reported by eyewitnesses. Share your experience via:
📱https://m.emsc.eu/#app
🌐https://m.emsc.eu/?id=1817933
**Gold Solidus of Theodosius II, Constantinople, 425–429 AD.**
#Gold #Coin #Numismatics #History #Byzantine #Empire
#Image attribution: ANS, CC0, via Wikimedia Commons. Page URL: https://commons.wikimedia.org/wiki/File:Gold_Solidus_of_Theodosius_II,_425-429.jpg.
Bibliolater 📚 📜 🖋
boosted

The Nag Hammadi Library & the Recovery of the Lost Gnostic Tradition
"How did the discovery of the Nag Hammadi Library influence the modern understanding of Gnosticism and early Christianity?"
https://www.thecollector.com/nag-hammadi-library-gnostic-tradition/
Bibliolater 📚 📜 🖋
boosted

The whole “AI demands universal basic income” argument presupposes that “AI” will eventually work and won’t be a major source of volatility that ultimately leads to a series of economic crises, which is unfortunately at least equally likely.
(Systemic volatility is lethal for an economy. It doesn’t matter if it comes coupled with an incremental productivity boost, systemic volatility has a tendency to cascade and cause major crises.)
Bibliolater 📚 📜 🖋
boosted
Why philosophy of physics?
Some physicists reject philosophy as a distraction from ‘real’ science but it is in fact both useful and beautiful
By James Read
Philosophy of physics at PG:
https://www.gutenberg.org/ebooks/subject/7005
Bibliolater 📚 📜 🖋
boosted

🇺🇸 **Trump bill set to add trillions to US debt pile – can America stop it climbing?**
“_Economists are concerned, politicians are angry – but the national debt keeps growing, no matter who’s in charge_”
🔗 https://www.theguardian.com/business/2025/jun/07/trump-bill-us-national-debt.
#Debt #Economy #Economics #Politics #USPol #Trump #USA #US #UnitedStates @economics
Bibliolater 📚 📜 🖋
boosted

I just love the fact that so much money (in this case, profit for an egregious rent-seeking bloodsucker) turns on the #OxfordComma
The European Commission is, of course, grammatically, stylistically, and aesthetically correct here. 😃
Morning all.
Bibliolater 📚 📜 🖋
boosted

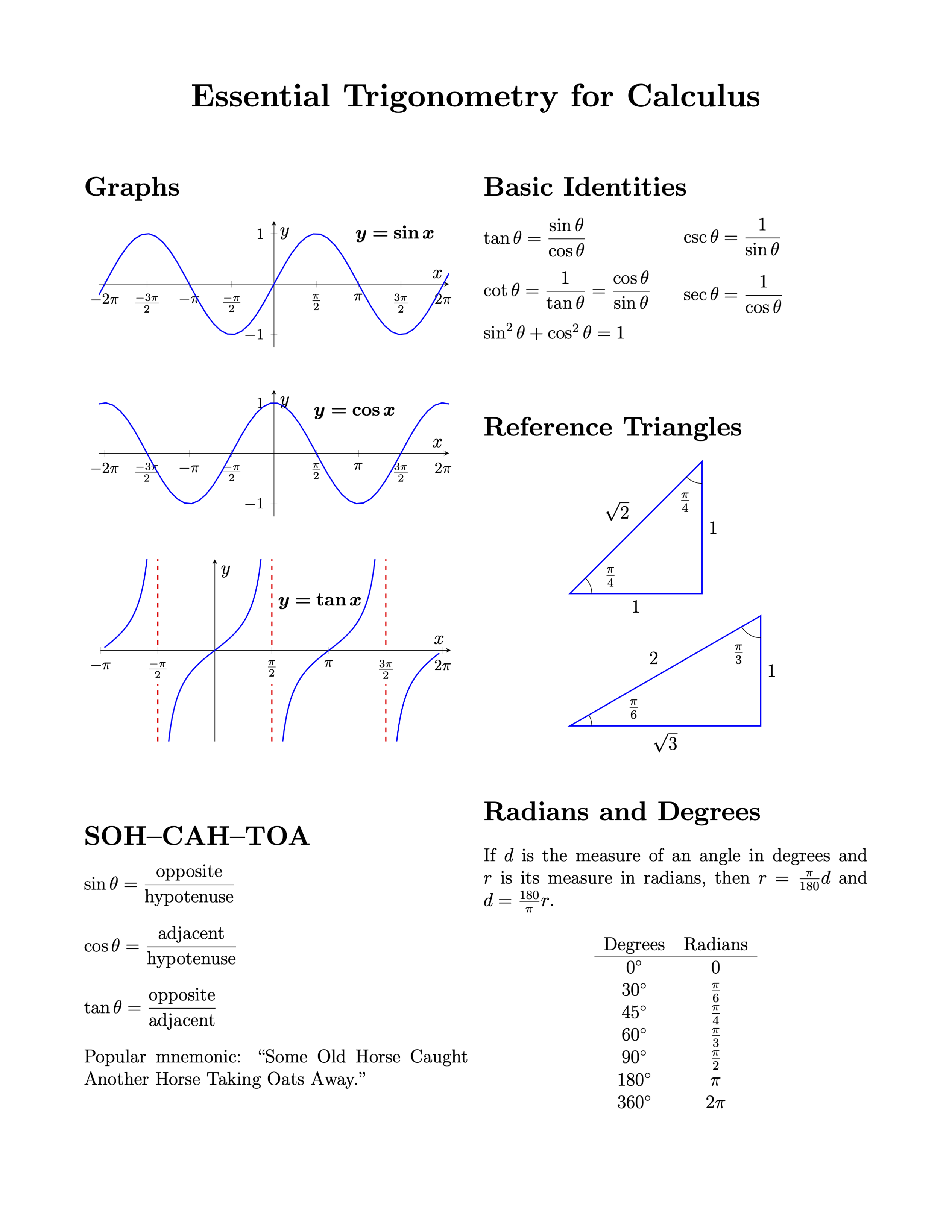
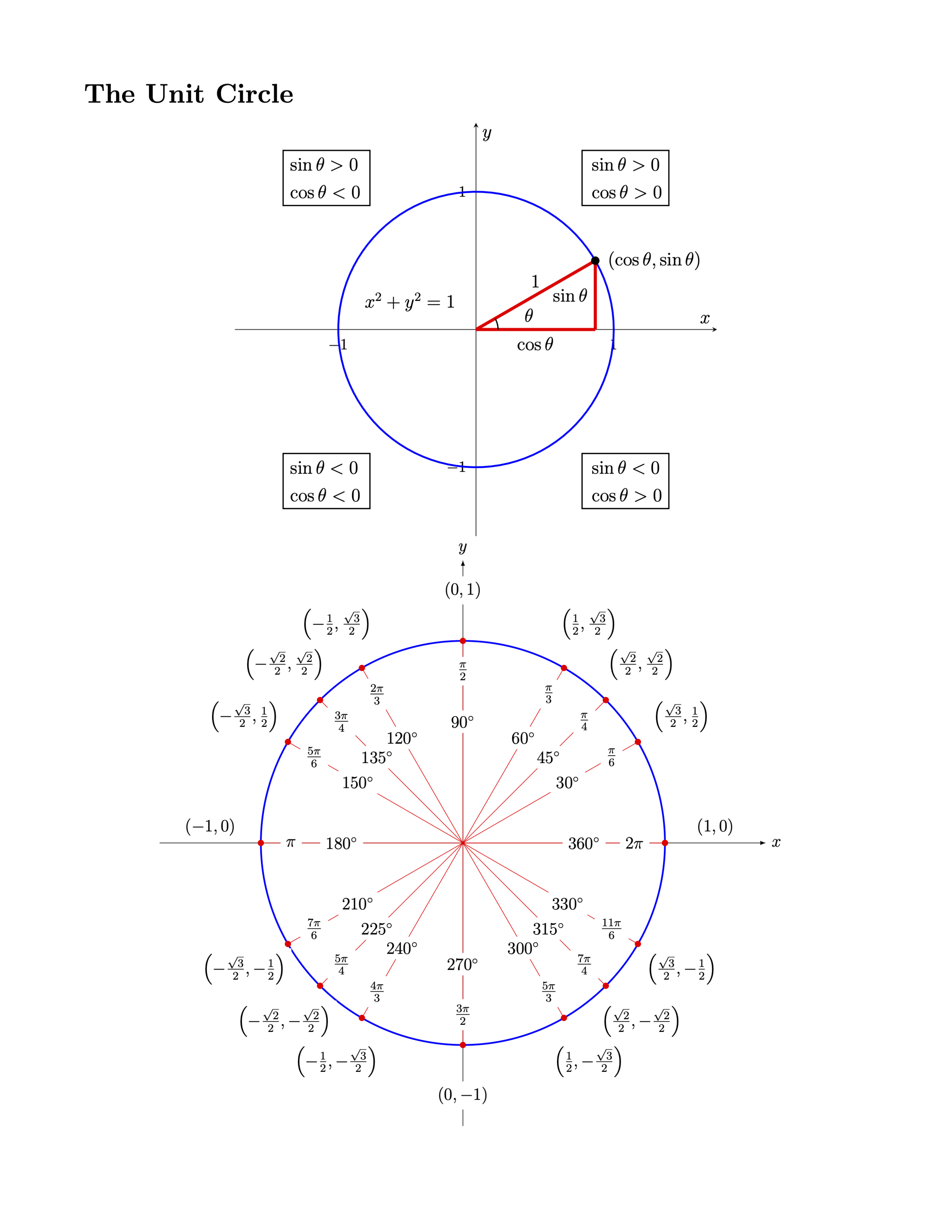
I got an email from someone asking for my "Essential Trigonometry for Calculus" cheat sheet, which I give to my calculus students. So, I thought I'd put it on GitHub for anyone to download (compiled PDF and source code). https://github.com/divisbyzero/Essential-Trig-for-Calculus
![]() **Request**
**Request**
I am looking for accounts (related to my interests) to follow, any suggestions will be greatly appreciated.
Please bear with me in response to any follow requests, as I have commitments outside social media that at times have to take precedent.
Thank you for reading this notice and your continued support.
Bibliolater 📚 📜 🖋
boosted

For all my academic colleagues who now work at the University of Bums on Seats - or if you are in the US and dont speak English, the University of Butts in Seats (they share BS in common)
@academicchatter #academics #universities #bumsonseats #buttsinseats #misinformation #pressreleases #advertising #sciencecommunication #science #astrobiology.
Bibliolater 📚 📜 🖋
boosted

@bibliolater @ai I cannot for the life of me imagine why lawyers still do this. There was that Mata v. Avianca case back in 2023 where a lawyer got flamed by the court for doing it, and ok, I have a little sympathy for him because he probably sincerely thought that ChatGPT was a fancy natural-language search interface. Under those circumstances it was an understandable error, though it's NEVER ok to cite things without checking that the citation supports the proposition you're citing it for even if you're copying out of a treatise or another case, so the guy deserved what he got. However, one of the things he got was a vast amount of mainstream media exposure, and at this point this has come up so often that there's really no excuse for not knowing how bad an idea it is. There's a guy in France who's trying to keep track of all the times it's happened; his database is up to 139 entries, and I'm sure there are a lot of cases he doesn't know about.
🇺🇸 ![]() **When Does US Debt Become Genuinely Bad?**
**When Does US Debt Become Genuinely Bad?**
“_The U.S. national debt is on its way to $30 trillion dollars and is projected to be more than 100% of GDP at the end of this year. So is that… bad?_”
#Video length: seven minutes and thirty-five seconds.
🔗 https://www.youtube.com/watch?v=Xi7RvweuIUk.
#WSJ #USA #US #UnitedStates #Debt #Economy #Economics @economics
🇬🇧 💻 **Lawyers face sanctions for citing fake cases with AI, warns UK judge**
“_A senior judge lambasted lawyers in two cases who apparently used AI tools when preparing written arguments, which referred to fake case law, and called on regulators and industry leaders to ensure lawyers know their ethical obligations._”
#AI #ArtificialIntelligence #Technology #Tech #Legal #Ethics #UK #UnitedKingdom @ai
Bibliolater 📚 📜 🖋
boosted

Towering tornadoes of plasma the size of planets dance over the Sun's surface in this timelapse from the Solar Dynamics Observatory spacecraft.
Credit: NASA GSFC/SDO
Bibliolater 📚 📜 🖋
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
"AI companies claim their tools couldn't exist without training on copyrighted material. It turns out, they could — it's just really hard. To prove it, AI researchers trained a new model that's less powerful but much more ethical. That's because the LLM's dataset uses only public domain and openly licensed material."
tl;dr: If you use public domain data (i.e. you don't steal from authors and creators) you can train a LLM just as good as what was cutting edge a couple of years ago. What makes it difficult is curating the data, but once the data has been curated once, in principle everyone can use it without having to go through the painful part.
So the whole "we have to violate copyright and steal intellectual property" is (as everybody already knew) total BS.
Not a bot, just a chap in his fifties who occasionally reads things.
Toots are humanities, science, non-fiction, books, maps, charts and graphs related. Some toots containing videos may also find their way into the timeline.
Toots or follows or boosts or mentions ≠ endorsements of any particular notion or notions.
Finis
Joined Nov 2022
