

Johannes Hoffart
boosted

DeepMind's paper refutes this last claim, and finds that both are equally useful.
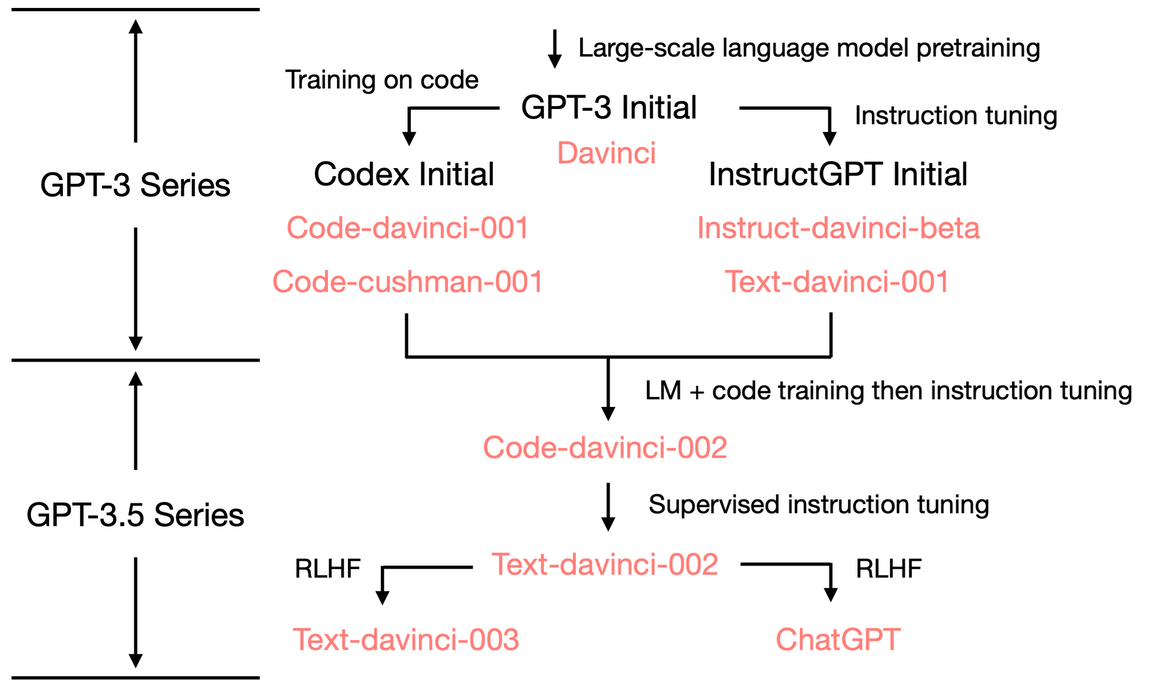
The differences between DeepMind & OpenAI's papers matter in terms of forecasting how big LLMs need to get. They arrived at these different conclusions because DeepMind did more learning rate tuning. This blog post https://severelytheoretical.wordpress.com/2022/07/18/thoughts-on-the-new-scaling-laws-for-large-language-models/ hypothesizes that DeepMind's paper might also be not doing enough hyperparameter tuning, and the scaling law may be less severe, perhaps not even a power law.
3/3
Johannes Hoffart
boosted

On #TheDataExchangePod I speak with Mark Chen, Research Scientist at OpenAI. We discuss the evolution of DALL·E, key research developments that led to DALL·E 2, data sources, safety measures, ML models needed for its success. #machinelearning #dalle2 #dalle #AI #generativeai https://thedataexchange.media/exploring-dalle-2/
Johannes Hoffart
boosted

I do however have high hopes for #blogic and RDF+Surfaces to make the interpretation of RDF vocabularies interoperable across organizations
Johannes Hoffart
boosted

Very interesting essay on LLMs, their limitations, and their future by @yoavgo!
https://gist.github.com/yoavg/59d174608e92e845c8994ac2e234c8a9
Johannes Hoffart
boosted

The latest issue of 'Ahead of AI' is now available!
This edition covers my top 10 papers of the year, as well as trends in the AI industry, notable developments in open source projects, and my personal yearly review routine.
Check it out at the link below and have a happy new year!
https://magazine.sebastianraschka.com/p/ahead-of-ai-4-a-big-year-for-ai
Johannes Hoffart
boosted

How good of a BERT can one get in ONE DAY on ONE GPU?
With all the recent studies about scaling compute up, this paper takes a refreshing turn and does a deep dive into scaling down compute.
It's well written, stock full of insights. Here is my summary and my opinions.
https://arxiv.org/abs/2212.14034
🧶 1/N
Johannes Hoffart
boosted

Johannes Hoffart
boosted

With the advent of #ChatGPT, everyone is talking about large language models. But how do they work? Initially, such models were trained to complete sentences.
But they exhibit exciting capabilities that can be invoked by feeding them "prompts."
Read our Prompt Engineering Guide for a quick overview of the current state of this field.
#nlproc #gpt #llm
https://www.inovex.de/de/blog/prompt-engineering-guide/
Johannes Hoffart
boosted
Scikit-learn 1.2 is out: https://github.com/scikit-learn/scikit-learn/releases/tag/1.2.0
Was an eventful December & I totally missed the new release of my favorite #machinelearning library!
My personal highlights are around the HistGradientBoostingClassifier (if you haven't used it yet, it's a LightGBM impl that works really well)
It now supports
1. interaction constraints (in trees, features that appear along a particular path are considered as "interacting")
2. class weights
3. feature names for categorical features
Johannes Hoffart
boosted

😮 Exciting times:
Surprised to see a #ChatGPT style AI model integrated with Web search so soon!
The new #YouChat provides links to sources, but just like other AI models also makes many mistakes.
Will be interesting to see how people use it.
https://you.com/search?q=what+was+the+recent+breakthrough+in+fusion+research%3F
Johannes Hoffart
boosted

I asked #chatGPT for 4 visual descriptions involving technology from the book 'Snowcrash' (so insane that you can now ask for stuff like that!?). I then copy-pasted them into Midjourney. Here are some results.
Johannes Hoffart
boosted
Hey, I am just signed up a few days ago and want to introduce myself.
I am a #machinelearning researcher focusing on deep neural nets. My passion is sharing all kinds of stuff about machine learning & open source. (Some of you may know me from my books “Python Machine Learning” and “Machine Learning with PyTorch and Scikit-Learn”.)
I love to teach others, and am currently working as Lead AI Educator at Lightning AI, and also an Assistant Prof of Statistics at the University of Wisconsin-Madison.
Johannes Hoffart
boosted

We've been working on new https://prodi.gy workflows that let you use the OpenAI API to kickstart your annotations, via zero- or few-shot learning. We've just published the first recipe, for NER annotation 🎉 https://github.com/explosion/prodigy-openai-recipes
Here's what, why and how. 🧵
Let's say you want to do some 'traditional' NLP thing, like extracting information from text. The information you want to extract isn't on the public web — it's in this pile of documents you have sitting in front of you.
Johannes Hoffart
boosted

Please donate to the Internet Archive if you can.
https://archive.org/donate
We are a bargain! Serving millions every day with books music video and web archives.
Please help keep everything freely available.
Johannes Hoffart
boosted

great post about chatgpt, reviewing everything known about how its emergent abilities might have come about https://yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1
Johannes Hoffart
boosted
Introducing: LAION 5B, a large-scale dataset for research purposes consisting of 5,85B CLIP-filtered image-text pairs. 2,3B contain English language, 2,2B samples from 100+ other languages
#OpenData #MachineLearning
https://laion.ai/blog/laion-5b/
Johannes Hoffart
boosted
This article sheds light on the question of why machine learning products mostly do not get into production even though they are enjoying an ongoing boom. Additionally, it shows how MLOps can help to tackle these challenges in the machine learning life cycle.
https://www.inovex.de/de/blog/a-conceptual-view-on-the-machine-learning-life-cycle/ #ml #mlops
Johannes Hoffart
boosted
Controversial #machinelearning suggestions by Yann LeCun at #NeurIPS2022 Self-Supervised Learning workshop!
He suggests:
(1) abandoning generative AI architectures
(in favour of joint embedding ones)
(2) abandoning probabilistic models
(in favour of energy-based models)
(3) abandoning contrastive methods
(in favour of regularized methods)
(3) abandoning RL where possible
(in favour of model-predictive control)
Related talk:
http://youtu.be/VRzvpV9DZ8Y
Source: https://twitter.com/BeingMIAkashs/status/1599061227665514496
Johannes Hoffart
boosted
Monolith (from ByteDance, creator of TikTok) is an interesting system for online training that addresses two problems faced by modern recommenders: (1) Concept Drift - underlying distribution of the training data is non-stationary; ( 2) Features used by models are mostly sparse, categorical and dynamically changing. #recsys #MachineLearning
Johannes Hoffart
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
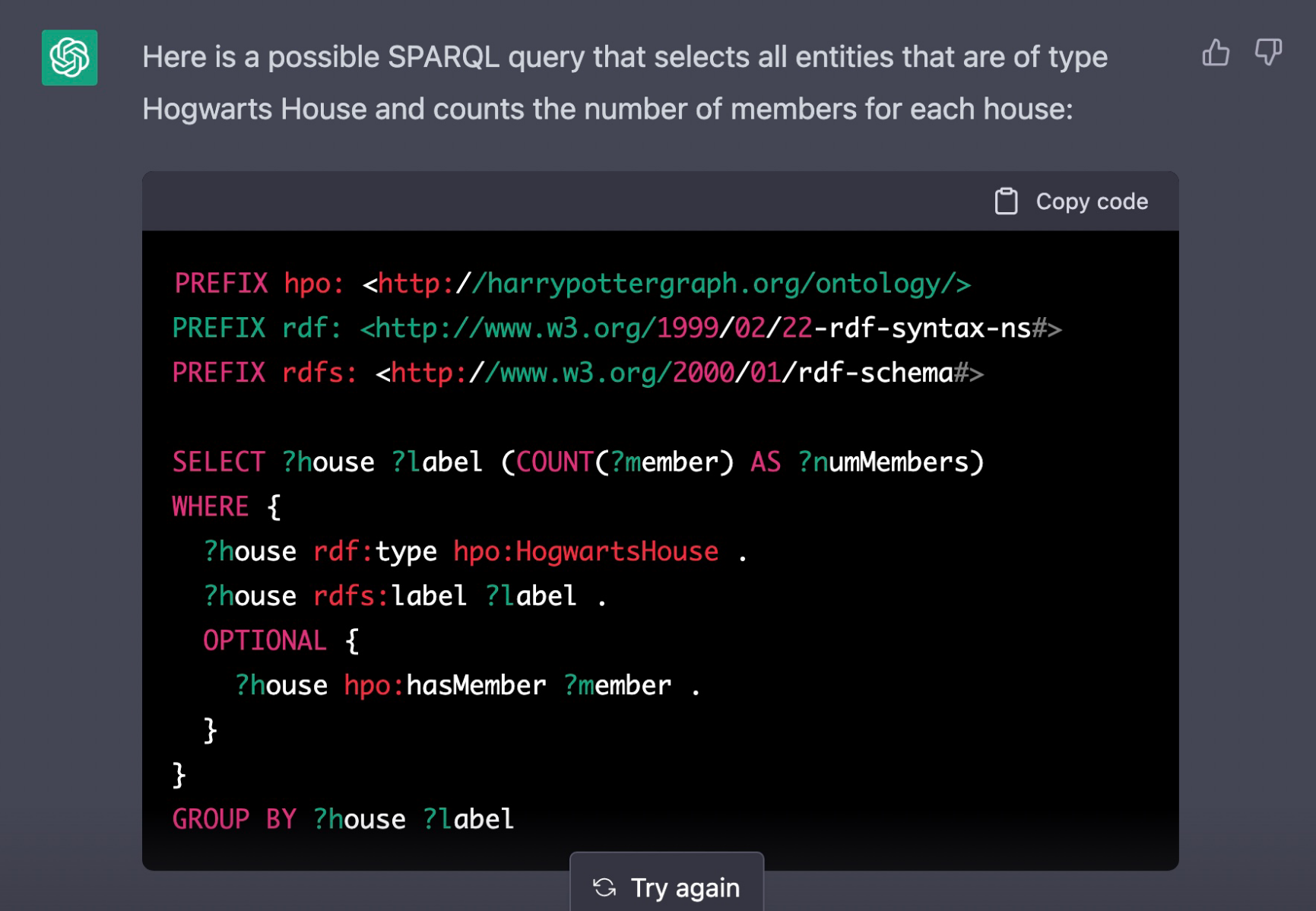
Like @timfinin I tried ChatGPT on last semester's final exam for my lecture "Information Service Engineering", with questions/tasks on Knowledge Graphs, basic NLP, and basic ML. It performed surprisingly well (for SPARQL it achieved 11 out of 12 points). Even for more complex questions like performing an evaluation or constructing an FSA, it performed not flawlessly, but not so bad. Overall, ChatGPT would have passed. Congratulations!
{kind=link}
- Website
- https://www.hoffart.ai
Joined Sep 2019
