

Michael Piotrowski @true_mxp@qoto.org
Associate professor of digital humanities, University of Lausanne, Switzerland
Professeur associé en humanités numériques, Université de Lausanne, Suisse
Joined Nov 2022
Michael Piotrowski
boosted

Michael Piotrowski
boosted

If the first non-whitespace non-comment thing in an #Inform7 source file is a double-quoted string, the story title is set to that string. If, on the same line as the closing quote, there's a " by " then the story author is set to whatever follows it. The story author may be double-quoted, but doesn't have to be. (If it's single-quoted then literal double-quote characters will be part of the story author value.) There may be a period immediately after the story author.
Michael Piotrowski
boosted

If anyone is wondering if Bing+GPT is somehow going to be better than Google Bard, remember that both LLM systems will be dependent on the underlying search algorithms.
Here is Bing (prior to GPT integration) doing the wrong thing. Bing search is retrieving articles about how Google summary boxes are wrong and then giving the wrong answer.
Both will have the same failure modes. The only difference is that Google stepped in it first.
Source: https://twitter.com/stilgherrian/status/1623576572015050753

Michael Piotrowski
boosted

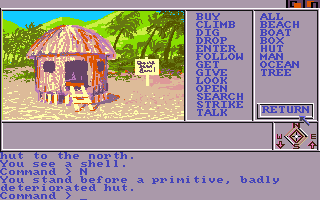
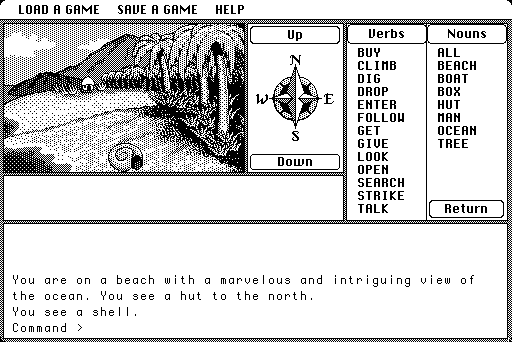
Mindshadow
Developed by Interplay
1984
Couldn't get a good source for the credits but it seems like it was designed by Rebecca Heineman and Allen Adham?
Michael Piotrowski
boosted

#DHNB2023 Calls for Reviewers for the Conference Proceedings! The DHNB proceedings are published with CEUR workshop series (https://ceur-ws.org/), a diamond open access publisher. Full papers are due 15 March 2023, and the review process will last until 26 April 2023.
Reviewing for the proceedings is an excellent way of contributing to the DHNB community and to digital humanities scholarship!
Interested? Fill in the short questionnaire, and we will get in touch! https://forms.gle/EEiaCgW56FWCHd4K7
Michael Piotrowski
boosted

Another new #Markdown extension in #pandoc 3: "mark".
pandoc --from=markdown+mark
This adds support for
==highlighted text==
syntax. Works with LaTeX, HTML, and docx output.
#formatExtension #highlight
Michael Piotrowski
boosted

Started work on SchXslt2, the second iteration of a modern XSLT-based ISO Schematron processor. SchXslt2 will be XSLT 3.0 only. What I can tell so far: The Schematron to XSLT transpiler is less then 500 lines of XSLT.
Dans le cadre du « Cercle de Serendip » https://wp.unil.ch/serendip/ j’interviendrai le 28 février 2023 (17 h 15, UNIL, salle POL-303 « Le Forum ») :
L’incertitude historiographique, mal nécessaire, ou bien inévitable ?
Nos connaissances du passé sont toujours incomplètes. En général, ce fait est considéré comme un défi pour l’historiographie. Mais si c’était une chance ?
The call for papers for @ACM #DocEng23 (August 22–25 in Limerick, Ireland) is out:
http://doceng.org/doceng2023/cfp
❝The 23rd ACM Symposium on Document Engineering (DocEng’23) seeks original research papers that focus on the design, implementation, development, management, use and evaluation of advanced systems where document and document collections play a key role. DocEng emphasizes innovative approaches to document engineering technology, use of documents and document collections in real world applications, novel principles, tools and processes that improve our ability to create, manage, maintain, share, and productively use these. In particular, DocEng 2023 seeks contributions in the area of collaborative work with documents. Attendees at this international forum have interests that span all aspects of document engineering and applications.❞
Michael Piotrowski
boosted

I spend part of my academic life in the Digital Culture program at the University of Bergen. We’re hiring an associate professor dealing with game studies & digital narrative https://www.jobbnorge.no/en/available-jobs/job/240043/associate-professor-in-digital-culture
Michael Piotrowski
boosted

Post-Doc position at the @uzh Center for Reproducible Science: Participate in research projects related to reproducibility, Open Science and meta-science.
Position starts April 1st, 2023 or as soon as possible. Review of applications will start February 20, 2023 until the position is filled.
https://jobs.uzh.ch/offene-stellen/postdoctoral-position/9e669128-c162-44bf-b752-54f4b773df71
Michael Piotrowski
boosted

To celebrate the Kickstarter for Shift Happens going well, I thought I would show you 50 keyboards from my collection of really strange/esoteric/meaningful keyboards that I gathered over the years. (It might be the world’s strangest keyboard collection!)
Michael Piotrowski
boosted

When I first checked out Tcl in the early 1990s, interactively building GUIs with Tk on Unix felt magical. Back then the alternative was to batch compile endless, boilerplate-filled C sources to get a fraction of the functionality.
This interesting interview with Tcl's creator John Ousterhout puts these innovations into perspective by discussing the impact of the language:
Of course it was only when I started to prepare a talk when I noticed that the implicit_figures extension, together with the new Figure node type introduced by #Pandoc 3.0, breaks my setup for producing slides and lecture notes :-(
In case anybody but me uses https://github.com/mxpiotrowski/pandoc-lecturenotes: I’ve made some changes, but the best solution is probably to turn off implicit_figures regardless of the output format.
Michael Piotrowski
boosted

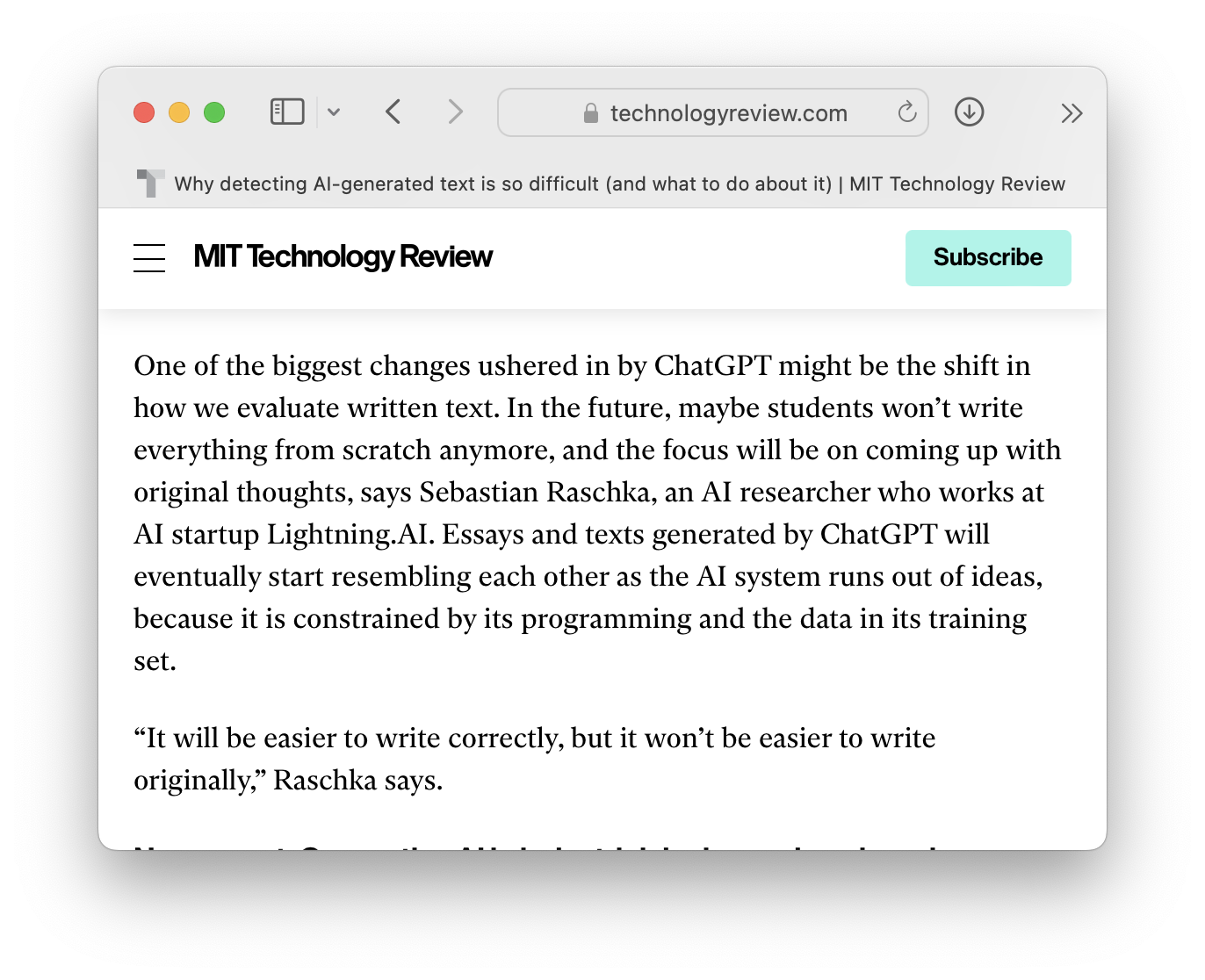
Are LLMs make it easier to write good essays? I’d say no, they are just shifting the goalpost.
LLMs will help us to write "correctly". However, crafting an original and engaging essay that someone wants to read will become a much more challenging task in the future.
Michael Piotrowski
boosted

Michael Piotrowski
boosted

@shriramk The numbers I see publicly claimed are 2-4 cents per chat. https://lifearchitect.ai/chatgpt/#cost
Scaled up to 8.5 billion searches per day, that's a bit of cash (and, energy).
I'm a little puzzled what the added value is, because the model optimizes word patterns, not facts. Sometimes the word patterns encode facts, sometimes, they do not.
Michael Piotrowski
boosted

@shriramk I only found this one
“Martin Bouchard, cofounder of Canadian data center company QScale, believes that, based on his reading of Microsoft and Google’s plans for search, adding generative AI to the process will require “at least four or five times more computing per search” at a minimum.”
here
https://www.wired.com/story/the-generative-ai-search-race-has-a-dirty-secret/
So one would have to know generic search costs to calculate it
Michael Piotrowski
boosted

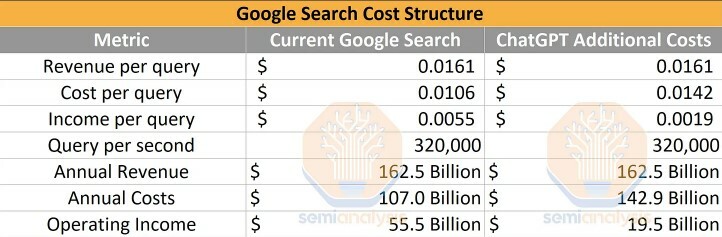
Disruption and innovation in #search don’t come for free
The costs to train an #LLM are high
More importantly, inference costs far exceed training costs when deploying a model at any reasonable scale
Some Microsoft CEO Satya Nadella quotes:
o This new Bing will make Google come out and dance, and I want people to know that we made them dance
o From now on, the [gross margin] of search is going to drop forever
https://www.semianalysis.com/p/the-inference-cost-of-search-disruption

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Associate professor of digital humanities, University of Lausanne, Switzerland
Professeur associé en humanités numériques, Université de Lausanne, Suisse
Joined Nov 2022
