

Shamar @Shamar@qoto.org
Joined May 2019
Shamar
boosted

I wonder.. if #GitHubCopilot can output original code (don't worry, it cannot... but follow the reasoning) why #Microsoft did not use #Windows11 sources to "train" it? Or maybe #IIS's or #Office365's one? Or #Azure sources.
Why violate the copyright and trust of #GitHub users? 🤔
Shamar
boosted

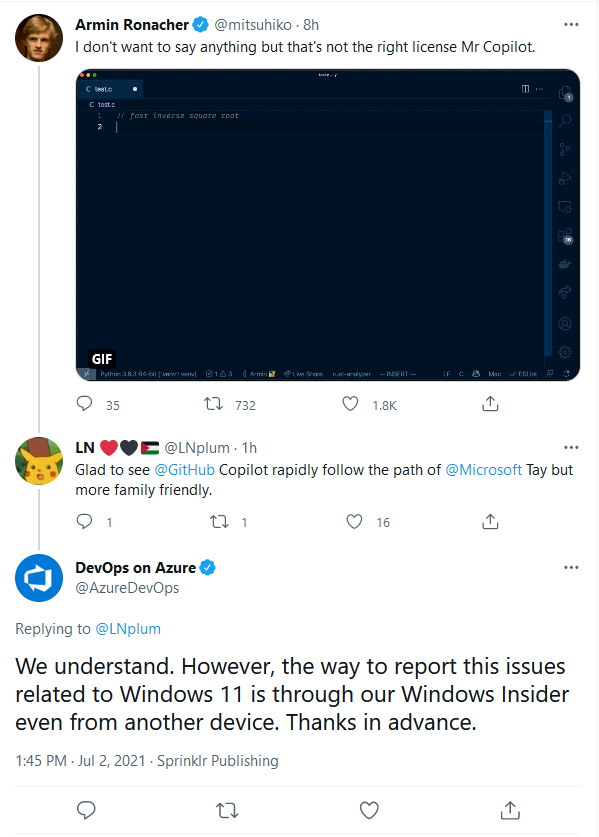
Some bot inception going on, this is a twitter post about Github copilot and a AzureDevOps account thinking its a windows 11 bug report on twitter
Shamar
boosted

I guess it is.
Maybe you would like to try #TempleOS, a very innovative operating system that was explicitly designed as a playful learning platform from a recently passed #hacker named #TerryADavis.
It's deeply inspired by #Commodore64 (in particular the UI), and it's completely written from scratch in #HolyC, a #C like language that is... somewhat unique.
Shamar
boosted

{kind=link}
A new user in #TempleOS:matrix.kiwifarms.net made some technical TempleOS videos: https://rumble.com/user/CravenCrypto
We need more videos like this, I regularly search on YouTube for recent TempleOS videos any 95% of the non-Terry videos are someone literally just booting it in VirtualBox, flailing around for a minute or two, and then ends.
We need more videos like this, I regularly search on YouTube for recent TempleOS videos any 95% of the non-Terry videos are someone literally just booting it in VirtualBox, flailing around for a minute or two, and then ends.
```
There are two orthogonal forces at work in the Squeak team [...] the incremental improvement plane (which #AlanKey calls the "pink" plane) and the paradigm shift (or "blue") plane. [...]
The forces in the pink plane have to do with making an ever-better Smalltalk-80 system [...]
The forces in the blue plane have to do with [...] an exquisite personal comuputing environment. [...]
One aspect is that things must stay small and simple enough that they remain comprehensible and accessible to a single person.
```
From http://web.archive.org/web/20050406063507/http://squeak.org/about/headed-prev-vers.html
I'm always amazed to see how ancient is the quest for #simplicity.
#Jehanne, #Wirth's #Oberon, #TempleOS, #Squeak... we are all looking for the same Holy Grail, dreaming the same dream but in a different way...
Dude, you know nothing about #US hegemony in technology.
This would be in no way the worst they did or do.
@marie_joseph@eldritch.cafe
I think it's up to us to explain this.
A long time ago I started using "statistical programming" instead of AI, ML, DL and similar antropomorhic locutions.
I always explain that ANN are just peculiar virtual machines whose programs (the numerical matrices of weights and activation thresolds) are programmed statistically through data samples.
As far as I can see, people understand this quite well.
The calibration of an ANN (improperly named "training") is just a form of compilation: the readable data are turned into opaque binaries that only that specific topology can execute "correctly" (for whatever correctly can means in this context).
Calling it "statistical programming" makes it also clear programmers' responsibility and how fragile and bugged are the opaque programs.
Yeah because #Microsoft is unable to automatically relates single files from a large project.
I mean... that would need NLP experts and a lot og expensive hardware! 🤣
Except in those languages that declare the module name at the beginning of each files, at least.
But sure, they "shall do no evil", right? 😇
How many ways are... fully legal like this?
You literally send them your code! On purpose! I mean... ok it's fooling dumb boys, but it's legal! You can't complain after!
@marie_joseph@eldritch.cafe
Not sure it's needed.
How could an algorithmic transformation of copyrighted material NOT be a derivative work?
It would be a giant loop-hole in #Copyright: you would just zip a mp3 and it would be public domain!
1. It's called industrial #espionage.
But with #Copilot, #Microsoft will get access to codebases that are NOT under #GitHub.
The editor will send them the sources, one file after another.
XXL le t-shirt... ;-)
@minimalprocedure@mastodon.uno
Non ti voglio convincere, ho solo paura di non essere chiaro!
Tu come definisci il codice?
Il codice è sempre un dato.
Il punto è se ogni dato possa essere codice.
Secondo me, se una macchina lo può eseguire, la risposta è sì.
Il ragionamento l'ho espanso anche su Nexa: https://server-nexa.polito.it/pipermail/nexa/2021-June/021823.html
@minimalprocedure@mastodon.uno
s/interpreta/può eseguire/
@minimalprocedure@mastodon.uno
No, se parliamo di reti neurali, non implementi modelli statistici in un linguaggio di programmazione (che so, R o Python), implementi una macchina virtuale (la rete neurale) che poi programmi attraverso i dati che gli dai in input.
I dati sono il programma statistico che la rete neurale "compila" durante la propria calibrazione (impropriamente detta "training).
Il risultato di quella compilazione è la matrice numerica, un binario che solo quella macchina interpreta "correttamente".
@minimalprocedure@mastodon.uno
Esatto sono matrici numeriche opache di pesi calcolate statisticamente.
Queste matrici costituiscono il programma eseguito meccanicamente dalla rete neurale che è sostanzialmente una macchina virtuale.
Potrebbe, in astratto essere costruita anche come hardware (scambiando magari flessibilità per performance) ed eseguirebbe quella stessa matrice numerica.
Perché quella matrice è il suo software, il suo "binario".
E viene prodotto statisticamente.
Per cui è corretto parlare di programmazione statistica.
Non sono "data scientists" sono programmatori.
Non è un'intelligenza artificiale, ma un programma che nessuno capisce completamente.
@minimalprocedure@mastodon.uno
No, non applichi i modelli statistici, sintetizzi i modelli (l'eseguibile di quella macchina virtuale) statisticamente.
Ovvero programmi statisticamente la macchina virtuale costituita dalla rete neurale (che ha una topologia specifica che ne costituisce l'hardware virtuale).
Puoi immaginarla come una CPU, solo che non si programma in assembly ma statisticamente.
@minimalprocedure@mastodon.uno
Una rete neurale è semplicemente una macchina virtuale programmabile (solo) statisticamente.
Joined May 2019
