

Andrew Kennard @askennard@qoto.org
- Website
- https://andrewkennard.github.io
- Google Scholar
- https://scholar.google.com/citations?user=ifhxikkAAAAJ
Cell biologist and biophysicist studying evolutionary cell biology.
I'm interested in how amoebae divide, especially relatives of the "brain-eating amoeba"
I study this with microscopy, image analysis, and comparative genomics.
Postdoc at UMass Amherst Biology, PhD in Biophysics from Stanford.
I also love jazz and nature photography!
searchable
Joined Nov 2022
Andrew Kennard
boosted

Centuries ago, I published a manuscript on BioRχiv about the love/hate relationship between variability and robustness in embryogenesis.
And now, it's published in Science! I am so proud 🥳
https://www.science.org/doi/10.1126/science.adh1145
We went through three (3!) rounds of revisions. Although we did not change a comma in the abstract, the revisions improved the quality of the work very much (we nearly doubled the sample size and added an entire figure).
Andrew Kennard
boosted

I'm sure the answer to this is write something myself. But it would be great if there was a #ggplot solution to:
- show individual points* for categories
- add summary crossbar ± error
- and do faceting
all from one data frame.
* ideally geom_sina from `ggforce` which I love.
The package `ggpubr` is very close, but not quite flexible enough.
Andrew Kennard
boosted

Teaching a new applied maths/physics course and using handwritten solutions to problem sets from previous years that haven't been typeset in LaTeX. Mathpix is an absolute godsend. It's uncanny how good it is at recognising handwritten mathematics and the words in between. It misidentifies a few words and symbols, but it's easy to fix that. Would have taken ages to typeset all the solutions myself! #mathpix #LaTeX #teachingmaths #teachingphysics
Andrew Kennard
boosted

I'm looking for a Firefox extension that will:
a) allow me to highlight and annotate phrases in web-pages;
b) recall those highlights and annotations when I return to that page;
c) store all those annotations *locally*, not upload them to a server.
I am not interested in "collaborative annotating" or publishing my annotations. I just want to annotate the things I read, as I read them, in my browser, for my own use.
Any ideas?
Thanks!
ETA: Zotero is unsuitable for my purposes in every way
Andrew Kennard
boosted

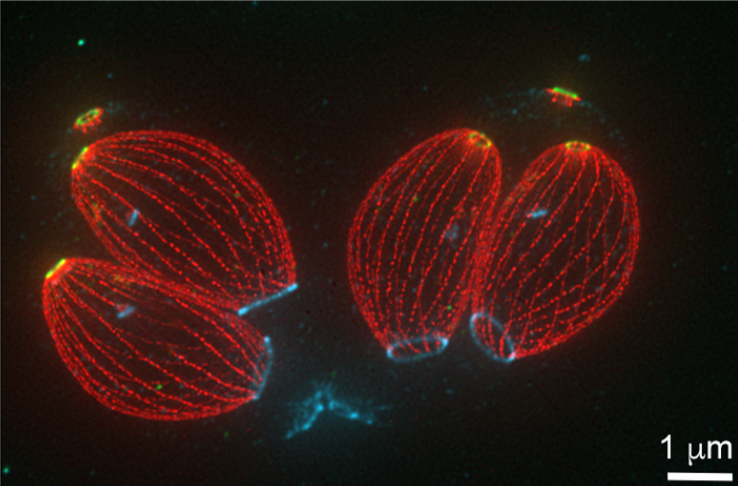
Luisa Padilla, Jonathan Lopez, Ke Hu and team use expansion microscopy to investigate the initiation of apical-basal polarity of Toxoplasma gondii.
@sennoma my two cents, as someone who is comfortable in python and dabbled just the slightest bit in SQLite-land:
1. If the goal is to get from dataset to analysis/conclusions as quickly as possible, it’s hard to beat #RStats. The codebase is so tightly integrated for exactly this task that it feels seamless once you get the hang of it. I’m a relative newbie to R (in particular the tidyverse set of packages explained in “R for Data Science”) but I am finding myself reaching for R first when I want to solve a data science type task.
2. OTOH, if data science is a case study for learning skills that would be transferable for more traditional software-engineering, then python + SQL is definitely the way to go. Or if you want to go all in on machine learning—a lot more widely used tools for ML in python.
Andrew Kennard
boosted
In 2024, the average cell biology preprint on bioRxiv gets ~50% of its views in the first 4-5 days after posting. And 75% of all views in its first month.
#ScientificPublishing #PowerToThePreprint #ReadAllAboutIt #CellBiology
Andrew Kennard
boosted

For fun and curiosity, I have few random sensors logging data at my home 24/7.
Earlier this month, I saw multiple events where my Geiger counter detected significant (not dangerously so) temporary increase in #radioactivity for some reason.
Today I think I got an explanation! The Finnish radiation authority #stuk posted that that they have measured Cesium-137 levels over 20 times higher than usual in the air early this month, likely coming in from the fires raging in #Chernobyl
So cool!
Andrew Kennard
boosted

The unreasonable effectiveness of simple HTML
https://shkspr.mobi/blog/2021/01/the-unreasonable-effectiveness-of-simple-html/
I've told this story at conferences - but due to the general situation I thought I'd retell it here.
A few years ago I was doing policy research in a housing benefits office in London. They are singularly unlovely places. The walls are brightened up with posters offering helpful services for people fleeing domestic violence. The security guards on the door are cautiously indifferent to anyone walking in. The air is filled with tense conversations between partners - drowned out by the noise of screaming kids.
In the middle, a young woman sits on a hard plastic chair. She is surrounded by canvas-bags containing her worldly possessions. She doesn't look like she is in a great emotional place right now. Clutched in her hands is a games console - a PlayStation Portable. She stares at it intensely; blocking out the world with Candy Crush.
Or, at least, that's what I thought.
Walking behind her, I glance at her console and recognise the screen she's on. She's connected to the complementary WiFi and is browsing the GOV.UK pages on Housing Benefit. She's not slicing fruit; she's arming herself with knowledge.
The PSP's web browser is - charitably - pathetic. It is slow, frequently runs out of memory, and can only open 3 tabs at a time.
But the GOV.UK pages are written in simple HTML. They are designed to be lightweight and will work even on rubbish browsers. They have to. This is for everyone.
Not everyone has a big monitor, or a multi-core CPU burning through the teraflops, or a broadband connection.
The photographer Chase Jarvis coined the phrase "the best camera is the one that’s with you". He meant that having a crappy instamatic with you at an important moment is better than having the best camera in the world locked up in your car.
The same is true of web browsers. If you have a smart TV, it probably has a crappy browser.
My old car had a built-in crappy web browser.
Both are painful to use - but they work!
If your laptop and phone both got stolen - how easily could you conduct online life through the worst browser you have? If you have to file an insurance claim online - will you get sent a simple HTML form to fill in, or a DOCX which won't render?
What vital information or services are forbidden to you due to being trapped in PDFs or horrendously complicated web sites?
Are you developing public services? Or a system that people might access when they're in desperate need of help? Plain HTML works. A small bit of simple CSS will make look decent. JavaScript is probably unnecessary - but can be used to progressively enhance stuff. Add alt text to images so people paying per MB can understand what the images are for (and, you know, accessibility).
Go sit in an uncomfortable chair, in an uncomfortable location, and stare at an uncomfortably small screen with an uncomfortably outdated web browser. How easy is it to use the websites you've created?
I chatted briefly to the young woman afterwards. She'd been kicked out by her parents and her friends had given her the bus fare to the housing benefits office. She had nothing but praise for how helpful the staff had been. I asked about the PSP - a hand-me-down from an older brother - and the web browser. Her reply was "It's shit. But it worked."
I think that's all we can strive for.
Here are some stats on games consoles visiting GOV.UK
Interestingly we have 3,574 users visiting https://t.co/CcU3PLPTpj on games consoles:
• Xbox - 2,062
• Playstation 4 - 1,457
• Playstation Vita - 25
• Nintendo WiiU - 14
• Nintendo 3DS - 16
20/22
— Matt Hobbs (@TheRealNooshu) February 1, 2021
https://shkspr.mobi/blog/2021/01/the-unreasonable-effectiveness-of-simple-html/
Andrew Kennard
boosted

This post from junkcharts was fun. Covers some simple tweaks that can improve charts which show GO term enrichment in biology.
https://junkcharts.typepad.com/junk_charts/2024/09/small-tweaks-that-make-big-differences.html
Andrew Kennard
boosted

Can we observe how the injured leg of an animal is regenerated?
We have figured out how to do this in the crustacean Parhyale. Over the course of a week, we can record the entire process of leg regeneration at cell-by-cell resolution.
Our latest preprint describes how we do this and what we see:
https://www.biorxiv.org/content/10.1101/2024.09.11.612529v1
More info/links on https://bsky.app/profile/michalis-averof.bsky.social/post/3l3xonnzt6u2n
Andrew Kennard
boosted

Conventional Ne metrics require both polymorphism and mutation rate data. Our CAIS metric can be inferred from just a single proteome + intergenic GC content. This makes it way easier to do study the effects of Ne over a broader range of species. 5/5
@JoannaMasel very cool! Do you have a sense how useful CAIS could be for estimating Ne for eukaryotic microbes? (Even roughly, say relative to vertebrates ). It seems that parameter has been super difficult to assess in those groups.
I recently did a small dip in this literature and now I have no clue how strong selective pressure is on the cells I care about (amoebae etc)!
Andrew Kennard
boosted
Our latest paper https://elifesciences.org/articles/87335
directly measures the #EffectivePopulationSize that matters to #NearlyNeutralTheory / #DriftBarrier theory, as the degree to which #CodonBias differs from expectations from GC content. Surprisingly, stronger #NaturalSelection -> higher #IntrinsicStructuralDisorder proteins
#MolecularEvolution #PopulationGenetics #EvolgenPaper 1/
Andrew Kennard
boosted

“It was a simple but brilliant design stroke: rather than a window where people paste text and allow the LLM to extend it, ChatGPT framed it as a chat window.”
"The practical risks of AI are not that they become super capable thinking machines. It is building complex systems around machines we falsely assume are capable of greater discernment and logic than they possess."
Just two of the excellent insights in this piece.
https://www.techpolicy.press/challenging-the-myths-of-generative-ai/
Andrew Kennard
boosted

Fascinating preprint on how (slowly) we think: "The Unbearable Slowness of Being"
https://arxiv.org/pdf/2408.10234
Andrew Kennard
boosted

{kind=link}
{kind=link}
Happy #MicroscopyMonday! Here are somme amoebae crawling into channels
Andrew Kennard
boosted
Kevin Gross and I have a new paper out in PLOS Biology about how the ubiquitous incentive structures that motivate hard work also discourage scientists from taking on high-risk, high-return research projects.
https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.3002750
- Website
- https://andrewkennard.github.io
- Google Scholar
- https://scholar.google.com/citations?user=ifhxikkAAAAJ
Cell biologist and biophysicist studying evolutionary cell biology.
I'm interested in how amoebae divide, especially relatives of the "brain-eating amoeba"
I study this with microscopy, image analysis, and comparative genomics.
Postdoc at UMass Amherst Biology, PhD in Biophysics from Stanford.
I also love jazz and nature photography!
searchable
Joined Nov 2022
