

Jeffrey C. Erlich @jerlich@qoto.org
Jeffrey C. Erlich
boosted

What math do neuroscientists need to know?
A highlight of #SFN2022 was Ella Batty's answer to this question. She showed off an incredible math for neuroscientists course she has developed at Harvard with open materials (https://ebatty.github.io/MathToolsforNeuroscience/) and discussed her amazing work with Neuromatch Academy (https://compneuro.neuromatch.io/)
Her SFN slides are here: https://osf.io/s94b2
Jeffrey C. Erlich
boosted

If you are submitting an abstract to
@CosyneMeeting
this year, especially if its your first time, we at the COSYNE DEIA committee have made this video to help you out: https://youtu.be/0r4Nz7NGmUw
Its interviews from experienced reviewers talking about how they evaluate abstracts
Jeffrey C. Erlich
boosted

@Odedrechavi It's a fair point. I think there should be more flexibility. If a student knows which lab they want to join, they should be allowed to start without required rotations. For others, brief rotations may help them find the right home.
Jeffrey C. Erlich
boosted

RT @criticalneuro
I know everyone raises this every year, but why isn't there 1 portal to submit 1 reference letter per grad student on the job market that any university can access instead of having to submit to 500 different links?
Jeffrey C. Erlich
boosted

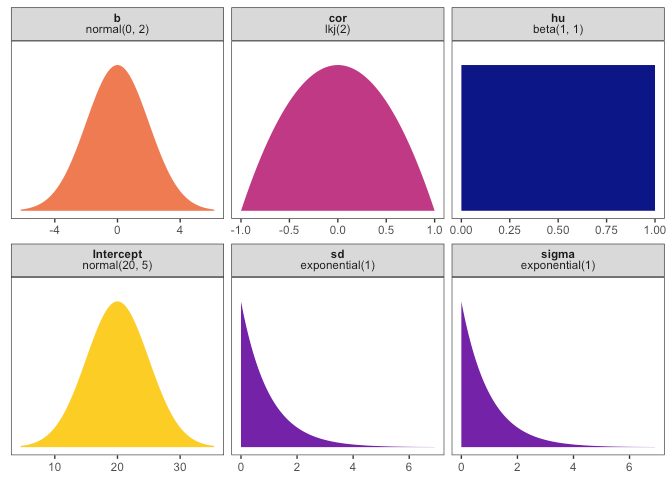
Loving tidybayes + ggdist more and more and more. Check out how easy it is to plot all your priors (even the tricky LKJ distribution!) at once, automatically, with ggdist::parse_dist()! (code here: https://gist.github.com/andrewheiss/a4e0c0ab2d735625ac17ec8a081f0f32) #rstats #bayesian #brms
Jeffrey C. Erlich
boosted

RT @aaronhoyland@twitter.com
It's the year of our Lord 2022 and I'm still seeing people say "Well, what did kids do before?" referring to vaccines and other modern medicine. There is no magical halcyon past where kids lived "natural" lives and thrived. You want to know what they did, Jan? THEY DIED. Often.
🐦🔗: https://twitter.com/aaronhoyland/status/1592920555724079105
Jeffrey C. Erlich
boosted

Dude, read this paper. https://psyarxiv.com/2uxwk/
Today!!! Go visit 567.08 / UU14 - The rat frontal cortex encodes a value map in support of economic decisions under risk!
https://www.abstractsonline.com/pp8/#!/10619/presentation/69748
related preprint: https://www.biorxiv.org/content/10.1101/2021.11.19.469107v2
Jeffrey C. Erlich
boosted

🚨 BIG DATA RELEASE 🚨 We are beyond excited to announce the release of our Brain Wide Map of neural activity during decision making! It consists of 547 Neuropixel recordings of 32784 neurons across 194 regions of the mouse brain 🐭🧠
All these recordings were performed in a distributed fashion in 12 different labs, spanning Europe and the US 🌎 Rigorous standardization of methods and materials allowed us to pool the data from these labs together into a single gigantic dataset 🐙
Mice are performing our standardized perceptual decision-making task in which they have to position a stimulus in the center of a screen to receive reward. The dataset contains the stimuli and decisions, but also videos from three angles and DeepLabCut pose information. We're even releasing all the raw ephys data!
We know, it's a lot. At your own pace you can read all the details about the experimental setup, the task, processing of the data, and much more in the technical paper which accompanies this data release: https://figshare.com/articles/preprint/Data_release_-_Brainwide_map_-_Q4_2022/21400815
To explore the data at your leisure, visit our visualization website where you can scroll through different recording sessions, look at neural activity during example trials, and see trial-based activity of single neurons: https://viz.internationalbrainlab.org
Do you have itchy fingers to run your models on this humongous dataset? We totally get it! Here you can find how to download the data using our API so you can fire up those computing clusters: https://int-brain-lab.github.io/iblenv/notebooks_external/data_release_brainwidemap.html
This was a collective effort of our stellar team, who all put in so much work to make this monumental achievement possible. Our collaboration consists of 22 PIs, 37 researchers, and 11 staff members who all worked tirelessly to bring these data to you, the community 👏🍾
Jeffrey C. Erlich
boosted
The lab has two posters at SFN this year!
567.08. The rat frontal cortex encodes a value map in support of economic decisions under risk https://www.abstractsonline.com/pp8/#!/10619/presentation/69748
217.11. Distinct roles for rat premotor cortex in World-Centered versus Self-Centered Planning
https://www.abstractsonline.com/pp8/#!/10619/presentation/83705
Jeffrey C. Erlich
boosted

Question: how much flexibility do instances have to add/play with features (e.g. the mechanics of threading, something like QT, etc)? Is it worth thinking about the features that facilitate scientific discussion, the needs of our community, and how they might be implemented?
The number of grad students who want to stay in academia is dropping because dramatically better salaries and work/life balance compared in industry
Although this trend makes my life harder (since it is very hard to recruit good postdocs), i see it as generally positive. We need to be thinking about new sustainable models for conducting research in academia - and this "tipping point" will force us to grapple with this.
Jeffrey C. Erlich
boosted

We have sooooo many tutorials :-). If you don't mind sitting down for a longer read, this is a community-written guide that goes into a lot of detail:
https://github.com/joyeusenoelle/GuideToMastodon#an-increasingly-less-brief-guide-to-mastodon
Jeffrey C. Erlich
boosted

I made my qoto account months ago, but haven’t really spent time in the fediverse until this week. Good to be considerate to those who have built a community and culture here for years.
Jeffrey C. Erlich
boosted

My first post on Mastodon: please take part in The Perception Census - help us advance research into perceptual diversity, and learn about your own powers of perception too: https://perceptioncensus.dreamachine.world/
Jeffrey C. Erlich
boosted

An #introduction to eLife's new Mastodon page!
We're an #OpenAccess not-for-profit journal that publishes and reviews #research in the life and biomedical sciences.
We want to improve the way research is practised and shared in part by working with early-career researchers #ECR and supporting #OpenSource technology.
We also just announced our new publishing model that we hope will tackle an overreliance on journal titles and publishing decisions as quality measures for science and scientists.
Jeffrey C. Erlich
boosted

{kind=link}
{kind=link}
{kind=link}
In case someone didn't know, two books I've co-authored are freely available online for non-commercial use:
#Bayesian Data Analysis, 3rd ed (aka BDA3) at https://stat.columbia.edu/~gelman/book/ and lectures plus #rstats, #Python and #Stan code at https://avehtari.github.io/BDA_course_Aalto/
#Regression and Other Stories at https://avehtari.github.io/ROS-Examples/ including #rstats and #Stan code
The web sites also have links to the publishers' web stores if you prefer hard copies of these
{kind=link}
{kind=link}
The [NYTimes published an article on which steel plants make the most pollution](https://www.nytimes.com/2022/11/09/climate/climate-change-emissions-satellites.html) and it looks like China is by far the worst. But this map doesn't tell the whole story. Who is buying and using that steel from China? If a substantial portion of that steel is sold to the west then that pollution should really be attributed to the client countries, not the manufacturing countries (or at least show both maps).
{kind=link}
