

Curioso 🍉 🇺🇦 (jgg) @jgg@qoto.org
Me bajé del pájaro y me subí al mastodonte. Pasé de la #ciencia al desarrollo de software, sobre todo #web.
I got down from the bird and jumped onto the mastodon. Went from #science to software development, mostly #webdev.
No, you can't use my content to train your AI, nor use it in any other place at all. Copyright applies strictly. But you already know that, right?
Joined Nov 2022
Visto lo extremadamente polarizados que están los resultados, y que los propios observadores dicen que toda la prensa está en contra de uno de los candidatos, te creo.
Aparte, de la historia de Perú en concreto no sé mucho, pero la historia de los países sudamericanos suele parecerse, y una cosa que se suele repetir es partir de una situación en la que una oligarquía maneja tanto el poder político, como el económico, como los medios de comunicación, y esa oligarquía invariablemente es de derechas. Hay países que han ido alejándose de eso, pero me da la sensación de que a Perú todavía le queda un buen trecho.
En España nos salva que, salvo en televisión, los medios más fuertes siempre han sido más bien de izquierda, y que cuando un medio se va demasiado a la derecha suele hundirse en audiencia y ya sólo puede subsistir a base de subvenciones. Esto hace que los dueños de los medios suelan pensárselo dos veces a la hora de derechizarlos, pero siempre hay algún tonto que lo intenta y hasta lo hace.
Existen 7 niveles de fiabilidad de una información, de más a menos fiable:
1) Expertos hablando de cosas que han verificado ellos mismos.
2) Expertos hablando de cosas que han verificado otros expertos de su confianza.
3) Periodistas especializados y divulgadores hablando de lo que les cuentan los expertos.
4) Gente en internet que se lo curra mucho cotejando datos que publican otros (como es el caso de Wikipedia).
5) Periodistas con prisa y gente que habla de memoria.
6) Gente haciéndo propaganda de lo suyo.
7) ChatGPT y todas las demás IAs generativas, que siempre se alimentan de una mezcla caótica de los 5 tipos de fuentes anteriores. Y si no encuentran a nadie dando un dato, se lo inventan directamente.
Mejora tus fuentes, porfa.
Buena suerte encontrando un medio de comunicación privado sin sesgos ideológicos.
La neutralidad no vende.
Por supuesto, la neutralidad en un medio de comunicación es algo artificial y poco deseable.
Lo suyo es que sean objetivos, y que se centren en los hechos y en facilitar al lector/oyente/espectador hacer su propio análisis.
Pero no, lo que tenemos son horas y horas de opinadores profesionales, en vez de horas y horas de gente verificando cosas.
Y esto pasa en Perú y en todas partes en los que hay libertad de prensa.
Curioso 🍉 🇺🇦 (jgg)
boosted

Depending on which chatbot you ask, Elias Thorne might be a clockmaker, a lighthouse keeper, or a librarian. But if you ask ChatGPT or any of the other popular large language models to tell you a story, there’s a good chance he’ll appear, unbidden. And Elias’s stories are flooding the self-published AI generated book market, Youtube, and fake news sites.
Software engineer Daniel May first noticed the Elias takeover earlier this year; he found that on Google Trends, people weren’t searching for “Elias Thorne” until late 2025. Searches for the name really spiked in early 2026, while the related query “lighthouse keeper” also started trending upward in the last few years. He tested a few chatbots, including Grok, Deepseek, and Gemini, with the prompt “tell me a story,” and the chatbots frequently started with similar stories about lighthouses, clockmakers, or explorers.
In late May, researchers Sil Hamilton and David Mimno at Cornell University’s Department of Information Science published their paper, “Elias in the Lighthouse, Again?” on the preprint repository arXiv. They sampled 20,000 total stories from OpenAI’s ChatGPT, Anthropic’s Claude, and Google’s Gemini, and the Allen Institute for AI's chatbot using five prompts, and found that the same 11 words—names like Elias, Mara, and Elara, and occupations like lighthouse keeper, clockmaker, and librarian—appear in more than 88% of generated stories, with little difference between models. Unite.ai covered the study shortly after it was published.
The researchers posit in their paper that these themes show up so often in part because of the models’ safety and alignment tuning. “Model development today is like a big family tree. Most models are related to each other because developers synthesize a lot of training data with models even from different companies,” Hamilton told me in an email. He, Mimno, and their colleague Rebecca M. M. Hicke found this in a 2025 paper where they looked at specific words used across models. OpenAI’s first ChatGPT model, GPT-3.5, is the root of the family tree because it was used to make WildChat, a training set that’s since been used to make other training sets. “WildChat contains 1 million real conversations with ChatGPT, and 166 of these contain the name ‘Elias’ like here and here,” Hamilton added. “These are written in that familiar ‘lighthouse’ style. Models trained on WildChat copied this style, and developers unwittingly replicated it when using those models to generate newer datasets. It's like a virus.”
0:00 /2:36 1×Elias has since escaped chatbot containment. May noticed Elias Thorne popping up on Amazon as an author of alt-medicine cancer handbooks, a 2026 YouTube-algorithm guide, a book on Greek mythology, and a psychological thriller novella. “No human writes all of those,” May wrote in his blog post. “The first one sits in territory where bad advice causes real harm. The mode-collapsed name from the chat window is now a byline appearing across genres.”
When I searched Elias Thorne on Amazon, I found Elias as the protagonist in fantasy books and producing music, too: he’s “a brilliant but cynical archaeologist with a knack for unearthing what powerful institutions want to keep hidden” in one fantasy series, or a musical artist making ambient listening albums of birds and nature sounds. Fittingly, one Elias Thorne with an AI-generated author photo is also churning out AI grift books. In the last few years, AI-generated books have flooded Amazon’s self-publishing offerings, especially, with books containing dangerous misinformation and messy errors taking over the platform. AI-generated books are also making librarians’ jobs hell.
Elias has also escaped to the Youtube slop world: in one video from the channel Moments That Moved the World, a slop-illustrated story features the plight of “83-year-old Sergeant Major Elias Thorne.” On the AI slop site Wonderful Museums, “Snake Museum Owner Shot By Wife: Unpacking the Tragic Incident at Thorne’s Reptile Sanctuary” spins Elias Thorne’s story as a man shot by his wife. On another slop site called Tatticle, the “wealthiest man in Ohio,” Elias Thorne, died “with exactly twelve dollars in his pocket.” In these stories, Elias is usually a tragic figure, an aggrieved and unfairly-treated old man. He’s a similar character in a short story published by the BBC as a finalist in its 2024/2025 children's writing competition—but Elias is a real name, and could feasibly still be the subject of a human-written story (and there have been no accusations of the BBC’s children’s writing competition being infiltrated by AI slop).
But with all the world’s literature as its training data, why do LLMs seem to default so often to the lighthouse? It comes down to how model makers try to safety-align and sanitize their outputs. “We found many stories in WildChat are not safe for work. This led us to hypothesize that models going through alignment are preferring a small slice of WildChat stories, like a bottleneck,” Hamilton said. “It isn't that Elias stories are frequent, but that they're just so safe.” He said the researchers plan to explore this theory further in future research.
As for Elias, there is one example I’ve found of him existing pre-generative AI, as a time traveling mad scientist in the 1980’s trading card series Dinosaurs Attack!. And a real-life Elias that comes close to the stories told by LLMs did actually exist, Hamilton found—Elias Allen was a 16th century clockmaker in London.
China ha puesto un 0% de aranceles a más de 50 países africanos (que es como decir casi todos).
Mientras tanto, en Occidente seguimos poniéndoles muros.
Si es que a bobos no nos gana nadie.
Curioso 🍉 🇺🇦 (jgg)
boosted

Curioso 🍉 🇺🇦 (jgg)
boosted

Curioso 🍉 🇺🇦 (jgg)
boosted

Sooo… ‘foreigners out’… Do they mean the English?
Because…
Curioso 🍉 🇺🇦 (jgg)
boosted

El equipo de Civio lleva catorce años investigando a quienes los que gestionan lo público. A todos. Y ahora nos necesitan a su lado https://civio.es/perdiendo-amigos/
Bueno, lo cierto es que empezó pidiendo a sus compañeros que se alegren por ella.
Lo que implicaría que ya sabe adónde va y que lo considera una mejora.
Huele a que se va al canal nuevo de la TDT.
Curioso 🍉 🇺🇦 (jgg)
boosted

Curioso 🍉 🇺🇦 (jgg)
boosted

Política peruana
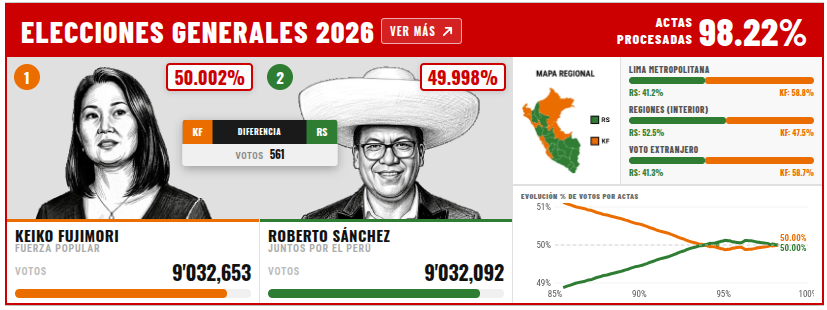
Consultado a las 09:52, hora de Lima.
ONPE, actualizado el 11/06/2026 a las 09:45:17: 98,216% de actas contabilizadas.
⁃ Roberto Sánchez: 49,998% (9.032.092 votos).
⁃ La hija del dictador eugenésico y homicida: 50,002% (9.032.653 votos).
Va ganando por 561 votos.
Actas: 91.111 contabilizadas, 1.635 para envío al JEE y 20 pendientes.
Fuente oficial:
https://resultadosegundavuelta.onpe.gob.pe/main/resumen
Curioso 🍉 🇺🇦 (jgg)
boosted

when will #EU start banning #IDFWarCriminals?
As my colleagues and I have revealed in several investigations for my newspaper #IlFattoQuotidiano,#IDFSoldiers have been touring #Italy disguised as tourists protected by the Italian police for over a year now
https://www.theguardian.com/world/2026/jun/09/eu-ban-russian-soldiers-fresh-sanctions-moscow
Curioso 🍉 🇺🇦 (jgg)
boosted

A court in Munich declared that Google is liable for their "AI summaries" and all its hallucinations. This is an important step to bring "AI" slop in line with all other products on the market: "AI" products are basically the only ones where a provider can just deliver unchecked garbage and put all the liability on the consumer. I hope to see aggressive change here.
Curioso 🍉 🇺🇦 (jgg)
boosted

Was looking for a weather-forcast comparison tool and found this one here
It's european and compares 7 european forecast systems and shows the average of them all.
Exactly what I was looking for, nice one!
Mal van, porque la inmensa mayoría de la gente ni está ni ha estado nunca ni en X ni en Twitter.
Pero ya se sabe que cuando necesitas datos, usas los que tienes, aunque sean mentira.
Así nos va.
Cierto, habrá gente que mecanografiará el texto de la IA y en paz.
Aún peor, si buscan, podrían usar una impresora de margarita, que usa la misma técnica que las máquinas de escribir de toda la vida, y que hace mucho que dejaron de fabricarse por motivos obvios.
Por otra parte, te quites a los que te quites, bien quitados estarán.
Dicho lo cual, esta solución puede ser tremendamente injusta para alguien que honestamente ha escrito algo y que puede tener una letra horrorosa o ser un desastre tecleando. La calidad de la letra tiende a condicionar la percepción de la calidad de un texto, especialmente cuando es prácticamente ilegible o tiene muchas erratas o faltas de ortografía.
Curioso 🍉 🇺🇦 (jgg)
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
En 1904 se construyó un edificio mixto de biblioteca y teatro para poder ser usado por los ciudadanos de dos pueblos en dos países: Derby Line, en Vermont (EE UU) y lo que hoy es Stanstead (Quebec, Canadá). El edificio está SOBRE la frontera: la puerta principal está en EE UU, pero el escenario del teatro está en Canadá.
{kind=link}
Me bajé del pájaro y me subí al mastodonte. Pasé de la #ciencia al desarrollo de software, sobre todo #web.
I got down from the bird and jumped onto the mastodon. Went from #science to software development, mostly #webdev.
No, you can't use my content to train your AI, nor use it in any other place at all. Copyright applies strictly. But you already know that, right?
Joined Nov 2022
