

Michael Piotrowski @true_mxp@qoto.org
Associate professor of digital humanities, University of Lausanne, Switzerland
Professeur associé en humanités numériques, Université de Lausanne, Suisse
Joined Nov 2022
Michael Piotrowski
boosted

I spend part of my academic life in the Digital Culture program at the University of Bergen. We’re hiring an associate professor dealing with game studies & digital narrative https://www.jobbnorge.no/en/available-jobs/job/240043/associate-professor-in-digital-culture
Michael Piotrowski
boosted

Post-Doc position at the @uzh Center for Reproducible Science: Participate in research projects related to reproducibility, Open Science and meta-science.
Position starts April 1st, 2023 or as soon as possible. Review of applications will start February 20, 2023 until the position is filled.
https://jobs.uzh.ch/offene-stellen/postdoctoral-position/9e669128-c162-44bf-b752-54f4b773df71
Michael Piotrowski
boosted

To celebrate the Kickstarter for Shift Happens going well, I thought I would show you 50 keyboards from my collection of really strange/esoteric/meaningful keyboards that I gathered over the years. (It might be the world’s strangest keyboard collection!)
Michael Piotrowski
boosted

When I first checked out Tcl in the early 1990s, interactively building GUIs with Tk on Unix felt magical. Back then the alternative was to batch compile endless, boilerplate-filled C sources to get a fraction of the functionality.
This interesting interview with Tcl's creator John Ousterhout puts these innovations into perspective by discussing the impact of the language:
Of course it was only when I started to prepare a talk when I noticed that the implicit_figures extension, together with the new Figure node type introduced by #Pandoc 3.0, breaks my setup for producing slides and lecture notes :-(
In case anybody but me uses https://github.com/mxpiotrowski/pandoc-lecturenotes: I’ve made some changes, but the best solution is probably to turn off implicit_figures regardless of the output format.
Michael Piotrowski
boosted

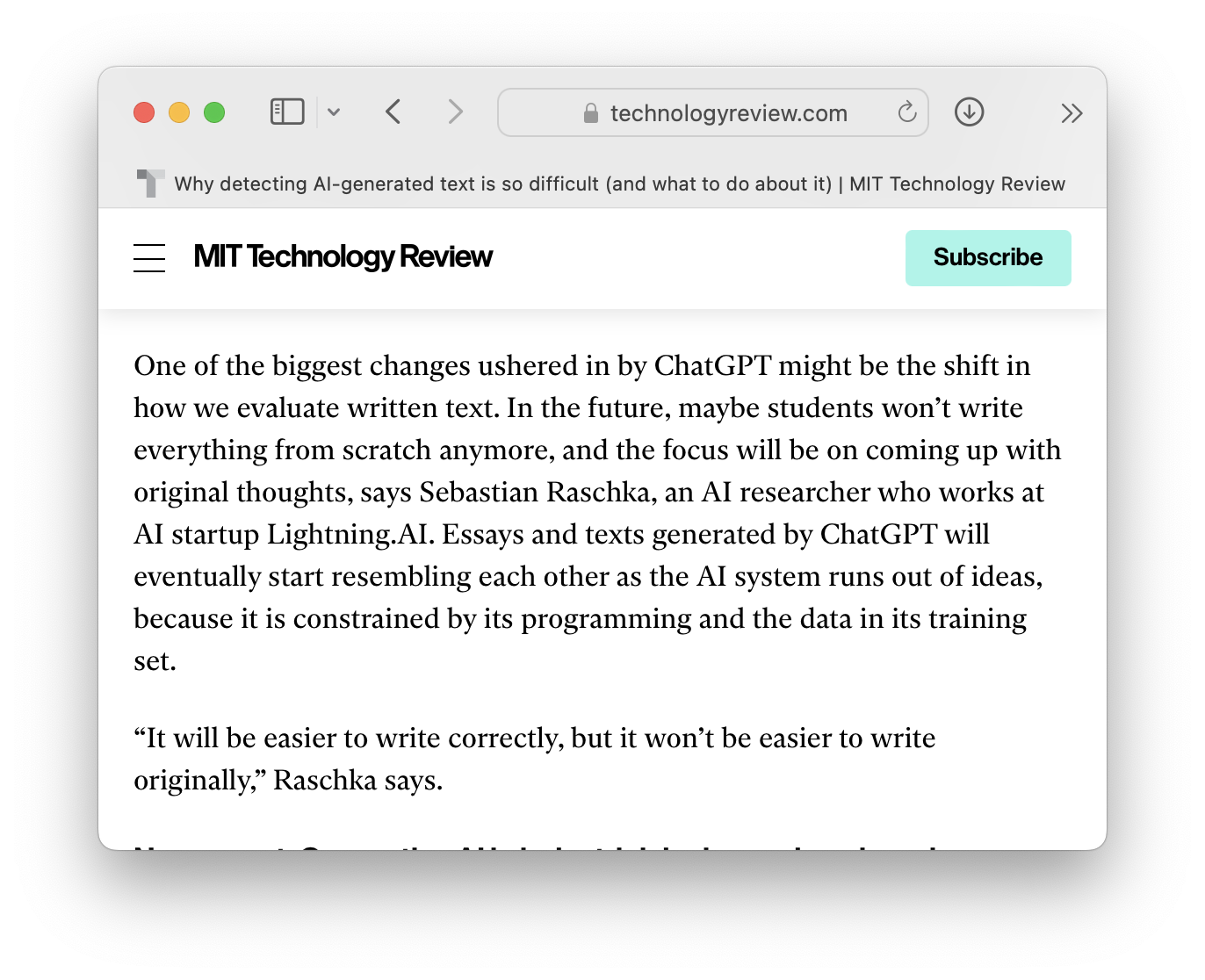
Are LLMs make it easier to write good essays? I’d say no, they are just shifting the goalpost.
LLMs will help us to write "correctly". However, crafting an original and engaging essay that someone wants to read will become a much more challenging task in the future.
Michael Piotrowski
boosted

Michael Piotrowski
boosted

@shriramk The numbers I see publicly claimed are 2-4 cents per chat. https://lifearchitect.ai/chatgpt/#cost
Scaled up to 8.5 billion searches per day, that's a bit of cash (and, energy).
I'm a little puzzled what the added value is, because the model optimizes word patterns, not facts. Sometimes the word patterns encode facts, sometimes, they do not.
Michael Piotrowski
boosted

@shriramk I only found this one
“Martin Bouchard, cofounder of Canadian data center company QScale, believes that, based on his reading of Microsoft and Google’s plans for search, adding generative AI to the process will require “at least four or five times more computing per search” at a minimum.”
here
https://www.wired.com/story/the-generative-ai-search-race-has-a-dirty-secret/
So one would have to know generic search costs to calculate it
Michael Piotrowski
boosted

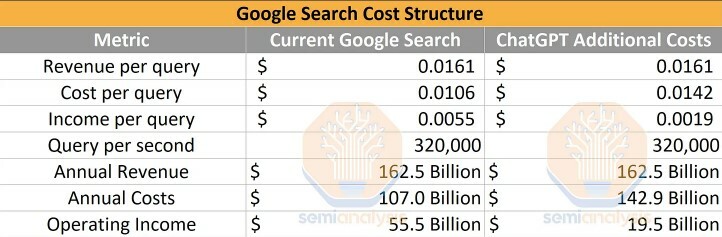
Disruption and innovation in #search don’t come for free
The costs to train an #LLM are high
More importantly, inference costs far exceed training costs when deploying a model at any reasonable scale
Some Microsoft CEO Satya Nadella quotes:
o This new Bing will make Google come out and dance, and I want people to know that we made them dance
o From now on, the [gross margin] of search is going to drop forever
https://www.semianalysis.com/p/the-inference-cost-of-search-disruption
Michael Piotrowski
boosted

Wharton professor Ethan Mollick has an interesting piece on how easy it was for him to create an entirely-synthetic video of him lecturing, using AI text, voice, and video generation tools.
Michael Piotrowski
boosted

Gotta admit that my first reaction to ChatGPT as a college instructor was a mixture of fascination & dread. Now I am encouraging my journalism students to use and interrogate AI services as part of their education. Here's why:
https://www.thescoop.org/archives/2023/02/11/teaching-journalism-with-chatgpt/
Michael Piotrowski
boosted

Some interesting information in the survey breakdown for this article. The survey found Gen Xers and older Millennials took cyber security the most seriously
@Kihbernetics Oh, wow, that’s an enthusiastic recommendation not to read the original ;-) Thanks, I’ll look for the translation then!
Michael Piotrowski
boosted

A Google Sheet showing Twitter bots moving to Mastodon. (h/t @researchbuzz) https://docs.google.com/spreadsheets/d/1SOmgXL3fRHAsxiVufw73VmzYmyLGat5koC7sf045Cic/edit#gid=1724839402
Michael Piotrowski
boosted

>"The aim of cognitive science always was - and still is today- the mechanization of the mind, not the humanization of the machine."
*Jean-Pierre Dupuy*
***The Mechanization of the Mind:***
*On the Origins of Cognitive Science*
https://www.google.ca/books/edition/On_the_Origins_of_Cognitive_Science/gDoiEAAAQBAJ
Michael Piotrowski
boosted

In 2008, I created a chat bot that would simulate the speech of Sarah Palin. Called GoAskSarah.com, it used a large corpus of her speeches and interviews to generate responses to questions posed by site visitors. The responses were, of course, inane, but they simulated her speech patterns using Markov chains, and sounded like her.
ChatGPT is, of course, much better, but fundamentally the same parlor trick that plays on humans’ extreme desire for anthropomorphism.
@Kihbernetics Thanks, sounds interesting! I’ll check out the original French edition at our library.
Michael Piotrowski
boosted

Much of the complexity of the 8086's flags is for historical reasons. The 8086's flags were compatible with the 8080 processor (1974), which extended the 8008 (1972). The 8008 was a clone of the Datapoint 2200 (1971), a desktop computer that is now mostly forgotten.
Michael Piotrowski
boosted

Lipstick on an amoral Chatbot pig
In hindsight, ChatGPT may come to be seen as the greatest publicity stunt in AI history, an intoxicating glimpse at a future that may actually take years to realize—kind of like a 2012-vintage driverless car demo, but this time with a foretaste of an ethical guardrail that will take years to perfect.
https://garymarcus.substack.com/p/inside-the-heart-of-chatgpts-darkness?utm_medium=email
#ai #artificialintelligence #chatGPT @garymarcus #chatbot #chatbots

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Associate professor of digital humanities, University of Lausanne, Switzerland
Professeur associé en humanités numériques, Université de Lausanne, Suisse
Joined Nov 2022
