

Michael Piotrowski @true_mxp@qoto.org
Associate professor of digital humanities, University of Lausanne, Switzerland
Professeur associé en humanités numériques, Université de Lausanne, Suisse
Joined Nov 2022
Michael Piotrowski
boosted

Shift Happens is nearing $600K and after talking to the printer, we figured out a way to set a stretch goal of $700K, meeting which would allow us to make the third volume slightly larger, but most importantly, to make it full-color!!!
Read the update here and tell your friends! A full-color third volume on the same great paper would be so much fun. (There would also be a great update to the Gorton font, also.)
https://www.kickstarter.com/projects/mwichary/shift-happens/posts/3736296
Michael Piotrowski
boosted

Shift Happens—a book about keyboards—is closing on $600,000 at Kickstarter and we’ve set a $700,000 stretch goal! An upgrade to the font (tier/add-on) and an already-committed third volume of extra goes from 100 pages to 160 and from black-only to full-color! Read the update from @mwichary https://www.kickstarter.com/projects/mwichary/shift-happens/posts/3736296
Nearing #2 funded non-fiction book in Kickstarter history, too (currently #3).
Michael Piotrowski
boosted

Congratulations to the winners of the first IFDB Awards!
https://intfiction.org/t/results-of-the-2022-ifdb-awards/60462
Michael Piotrowski
boosted

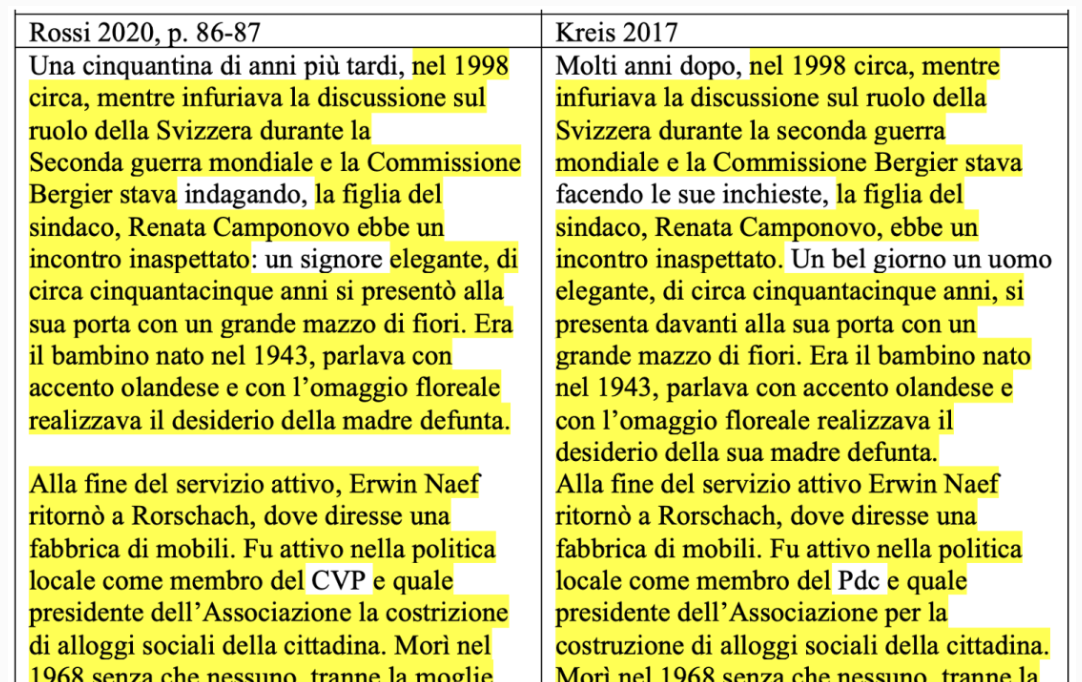
What I have seen so far (mostly on Twitter, published by a variety of accounts, and on academia.edu, published by Carla #Rossi) in terms of #Receptio's reaction to the accusations of #plagiarism and creating misleading appearances, is not up to the task of defending the #reputation of a research institute and a researcher. #receptiogate [1/5]
Preparing for the semester is mainly finding out which workarounds for #TeXLaTeX issues no longer work and coming up with new workarounds :-(
Michael Piotrowski
boosted

I wrote about #LLM and #LanguageTechnology at large for #LanguageLearning and teaching. It's a non-reviewed #preprint of a journal paper to appear this summer (and will be revised as technology progresses...)
You can read it on @EdArXiv
Happy to get feedback and comments!
Featuring Goudy OldStyle, #Brandon (by Hannes van Döhren) and the citation style
@true_mxp created for my dissertation
Michael Piotrowski
boosted

Former Federal President #Gauck nails it. „Surely the lesson of history, in which we were terrible murderers, cannot be to watch other murderers in silence.“
Michael Piotrowski
boosted
Blick auf den Kalender: Montag fängt das Frühlingssemester an. Wie unvorbereitet kann so ein Semester eigentlich losgehen?
Ich: Ja
Michael Piotrowski
boosted

Anxious time when I discovered this just-published title this morning. So close to my book's area. But looks good.
Chown, Eric, and Fernando Nascimento, Meaningful Technologies: How Digital Metaphors Change the Way We Think and Live (Lever Press, 2023) <https://doi.org/10.3998/mpub.12668201>
Michael Piotrowski
boosted

@philosophy #SocialEpistemology #Epistemology
I work on discourse, social networks, misinfo, etc. work here typically assumes that correcting misinfo will lead to better outcomes (decisions etc) -at least long term.
But imagine a scenario like this: dangerous misinfo is being countered by plausible and hence effective misinfo of its own. What actions (if any) should be taken *against* the rebuttal discourse?
Thoughts? Are there good game theoretic accounts of this? on morality?
@kzollmann
Michael Piotrowski
boosted

Really great piece from Sacasas about what I think is my biggest worry about LLM chatbots: how easily they can, without intention, take advantage of our highly social nature, and how dangerous that is when combined with a population of lonely, isolated people. https://theconvivialsociety.substack.com/p/the-prompt-box-is-a-minefield-ai
Michael Piotrowski
boosted

I generally don't talk about RECEPTIO and #ReceptioGate here (there's still plenty going on at the other place), but for those who are interested, there are two more damning reports published today by the Dutch Fact-Checking website Nieuwscheckers.nl
One mainly concerns extensive plagiarism in a book about Jews fleeing Italy in 1943-45: https://nieuwscheckers.nl/receptiogate-ook-boek-over-jodenvervolging-bevat-knip-en-plakwerk-zonder-bron/
The other concerns plagiarised artwork, with very interesting animations: https://nieuwscheckers.nl/roos-is-een-roos-is-een-roos-de-kunst-van-carla-rossi/
Michael Piotrowski
boosted

Looks like Microsoft finally took big steps to reign in their wildly-rogue Bing chatbot:
- 50 message daily chat limit
- 5 exchange limit per conversation
- No longer allows you to talk about Bing AI itself
On the one hand, this is absolutely the right thing to do
Have to admit I'm a bit gutted I never got to talk to unfiltered Bing (aka Sydney) first hand though
Michael Piotrowski
boosted
Though a scenery thing is already by default fixed in place in #Inform7, even if you mark it portable, the can't take scenery rule would prevent taking it. Like things in general, by default scenery is not pushable between rooms, but even if you made it pushable between rooms, the can't push scenery rule would prevent it. (Backdrops and doors are definitively never pushable between rooms.)
Michael Piotrowski
boosted
Are there recommendations on books or blogs or … for information on #Parkinson disease targeting not patients but relatives? English or German would be fine
Michael Piotrowski
boosted
New report from Peter Burger concerning #ReceptioGate (Google translator works quite well with it)
Michael Piotrowski
boosted

Following snippet as an example what I mean
Yes, the term "hallucinate" has an established meaning as AI jargon. Loosely and in the context of large language models (LLMs) such as GPT-3, it refers to situation in which the AI makes claims that were not in the training set and which have no basis in fact.
But I want to look at how this use of language in public communications perpetuates misunderstandings about AI and helps distance the tech firms that create these systems from the consequences of their failures.
A lesser issue is that in common language and in common understanding, as well as in medical science, a hallucination is a false sense impression that can lead to false beliefs about the world.
A large language model does not experience sense impressions, and does not have beliefs in the conventional sense. Using language that suggests otherwise serves only to encourage to sort of misconceptions about AI and consciousness that have littered the media space over the last few months in general and the last 24 hours in particular.
The bigger problem with this language is that the term "hallucination" refers to pathology. In medicine, a hallucination arises a consequence of a malfunction in an organism's sensory and cognitive architecture. The "hallucinations" of LLMs are anything but pathology. Rather they are an immediate consequence of the design philosophy and design decisions that go into the creation of such AIs. ChatGPT is not behaving pathologically when it claims that the population of Mars is 2.5 billion people—it's behaving exactly as it was designed to, making up linguistically plausible responses to dialogue, in the absence of any underlying knowledge model, and guessing when its training set offers nothing more specific.
I would go far as to say that the choice of language—saying that AI chatbots are hallucinating—serves to shield their creators from culpability. "It's not that we deliberately created a system designed to package plausible but false claims in the form of trusted documents such as scientific papers and wikipedia pages—it's just that despite our best efforts this system is still hallucinating a wee bit."
The concept of hallucinating AI brings to mind images of HAL struggling to sing Daisy Bell as Dave Bowman shuts him down in 2001: A Space Odyssey. No one programmed HAL to do any of things he did in the movie's climax. It was pathology, malfunction, hallucination.
When AI chatbots flood the world with false facts confidently asserted, they're not breaking down, glitching out, or hallucinating. No, they're bullshitting. In our book on the subject, we describe bullshit as involving language intended to appear persuasive without regard to its actual truth or logical consistency. Harry Frankfurt, in his philosophy paper "On Bullshit", distinguishes between a liar who knows the truth and tries to lead you in the opposite direction, and a bullshitter who doesn't know and/or doesn't care about the truth one way or the other*. (Frankfurt doesn't tell us what to think about someone who hallucinates and relays false beliefs, but it is very unlikely that he would consider such a person to be bullshitting.) Frankfurt's notion of bullshit aligns almost perfectly with ChatGPT and the likes are generating. A large language model neither knows the factual validity of its output — there is no underlying knowledge model against which its text strings are compared — nor is it programmed to care.
Language matters, and it perhaps matters more than average when people are trying to describe and understand new situations and technologies beyond our previous experiences. Talking about LLMs that hallucinate not only perpetuates the inaccurate mythos around the capabilities of these models; it also suggests that with a bit more time and effort, tech companies will be able to create LLMs don't suffer these problems. And that is misleading. Large language models generate bullshit by design. There may be ways to develop AIs that don't do this, perhaps by welding LLMs to other forms of knowledge model or perhaps by using some completely different approach. But for pure LLMs, the inaccuracies aren't pathological—they're intrinsic to the approach.
Established jargon or not, it's time for those who write for the public about AI and large language models to abandon the term "hallucinating". Call it what it is. Bullshitting, if you dare. Fabricating works too. Just use a verb that signals that when a chatbot tells you something false, it is doing exactly what it was programmed to do.
Michael Piotrowski
boosted

Ho ho ho. Copyright being used to takedown research outputs (again). Wiley versus SSRN (Elsevier/RELX). Everybody loses 👍 🙃
https://twitter.com/TomValletti/status/1625930771213975553?s=20
Michael Piotrowski
boosted

Sloth is a native Mac app by fellow Icelander Sveinbjörn Þórðarson that shows all open files and sockets in use by all running processes on your system. This makes it easy to inspect which apps are using which files and sockets.
It's lsof for people like me. Very useful.
brew install --cask sloth
Michael Piotrowski
boosted

According to MS, Bing AI goes crazy because “[the team] didn’t ‘fully envision’ people using its chat interface for ‘social entertainment’ or as a tool for more ‘general discovery of the world.’” Which demonstrates either a colossal lack of vision or a colossal ignorance of people. Which, now that I think about it, is kind of on brand for most AI systems.
https://www.theverge.com/2023/2/16/23602335/microsoft-bing-ai-testing-learnings-response

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Associate professor of digital humanities, University of Lausanne, Switzerland
Professeur associé en humanités numériques, Université de Lausanne, Suisse
Joined Nov 2022
