

Nicola Romanò @nicolaromano@qoto.org
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Organiser, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
Nicola Romanò
boosted

‘According to the Retraction Watch database, the 200 authors with the most retractions account for over a quarter of all 19,000 retractions. Many of the most prolific fraudsters are senior scientists at big universities or hospitals.’
https://web.archive.org/web/20230222193709/https://www.economist.com/science-and-technology/2023/02/22/there-is-a-worrying-amount-of-fraud-in-medical-research
#fraud #science #academia
Nicola Romanò
boosted

Check out our new commentary piece in @NatureEcoEvo - Better incentives are needed to reward academic software development rdcu.be/c6uMN software is critical for synthesizing & modeling big data in ecology and evolution … but current incentive structures are lacking
Nicola Romanò
boosted

Ok, so there is much discussion about the alt text on pictures. My mom is legally blind. As she has gotten older her sight is almost gone. She LIVES on the computer and to say she gets excited when special attention is paid for the blind is a great understatement. Please use alt text and describe the pictures you post. Describe it as if you had your eyes closed and the only link to the outside world is what a kind soul took an extra 5 minutes to type. Come on, do it, make someone’s day.#AltText
Nicola Romanò
boosted

If you see a bank account for donations to help cyclone victims, take the time to verify the account from an official published source.
For example: the recipient organisation's website.
Best not to just send money to an account repeated by social media users.
Nicola Romanò
boosted

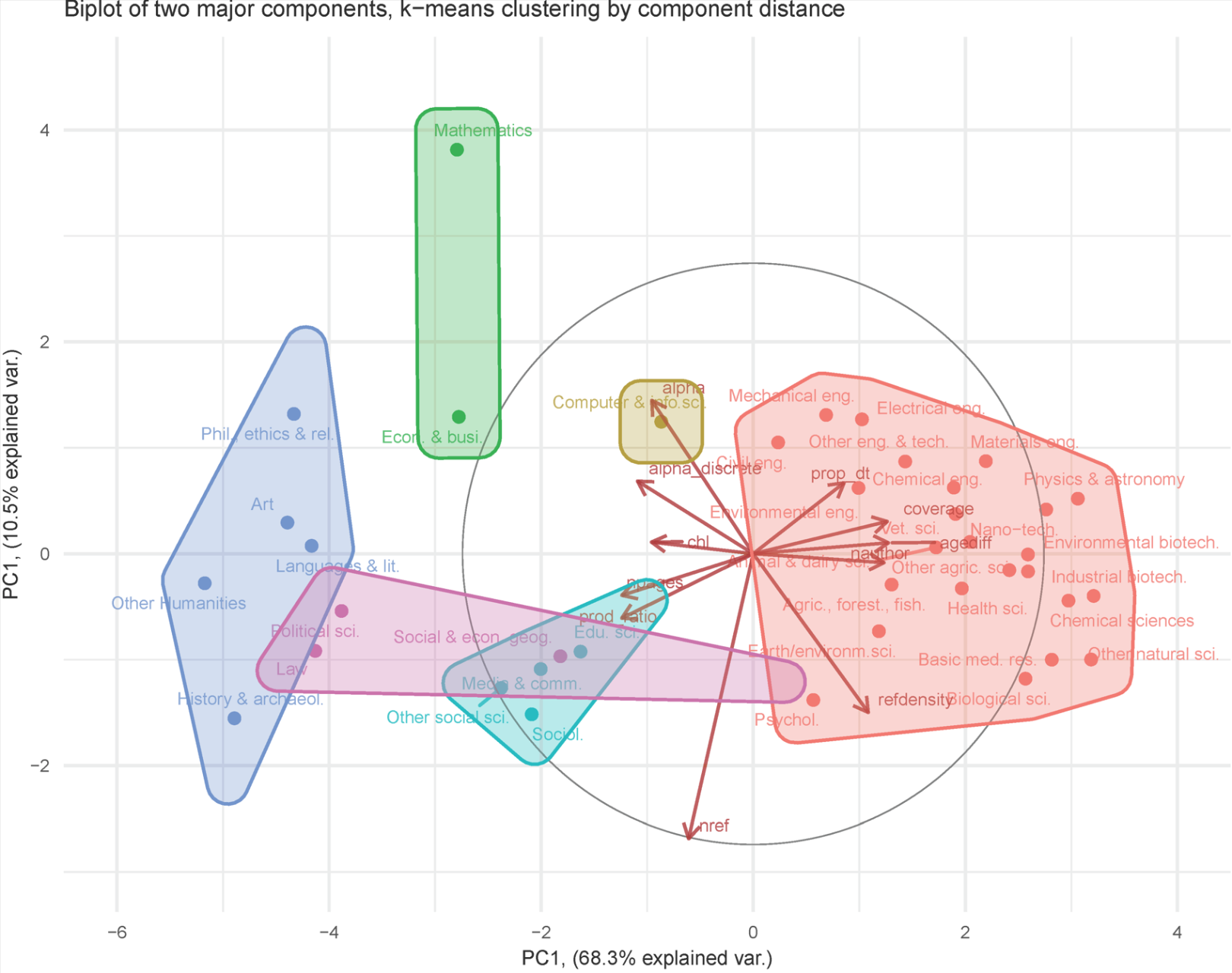
How are different scientific fields related, from a bibliometric point of view? Who writes longer papers? Uses more references? More recent references? In which fields does author position matter? Data for 20 years, all of Web of Science here:
https://doi.org/10.1162/qss_a_00246
Underlying, de-identified data can be found here: https://doi.org/10.5281/zenodo.7573523
Nicola Romanò
boosted

Okay, it's been a while since I last did this, and I haven't done it on mastodon yet, so I'm going to take a deep dive into p-values for another automated GWAS. Specifically, this one, relating to "Eosinophil percentage":
https://twitter.com/SbotGwa/status/1622218396661071874
I'm interested in this particular set of results because the p-values are impossibly large, with dozens of impossibly-large p-value peaks throughout the genome.
Also, the heritability of 0.22 is within the realm of possibility for finding true links.
Nicola Romanò
boosted

@ct_bergstrom Not sure what's this rant about. Nobody ever said decoder models are perfect or will have an actual understanding of the world. (Ok, maybe except for that one Google guy) OpenAI released a beta product which is incredibly helpful if used correctly but people like you just focus on its mistakes. It's like hating on cars because they can't take the stairs.
Nicola Romanò
boosted

@ct_bergstrom The LLM isn't bullshitting, because it's just a machine. It has no intentionality and no mind.
The engineers and execs at tech companies who are leveraging LLMs: they are bullshitting. It's an act of malice and should be treated as such.
Nicola Romanò
boosted

@ct_bergstrom Disagree. They're designed to mimic what a human would write. If they end up bullshitting it's because the models aren't good enough, not because that's what they're designed to do.
Nicola Romanò
boosted

= Sharing peer review publicly? =
In a discussion with non-academics there was a consensus that us not sharing our peer review process publicly violates what they perceive as our scientific integrity & our commitment to them as key stakeholders and indirect funders.
My reply: yes, I agree.
Question 👇
Nicola Romanò
boosted

@brewsterkahle Not just avoiding paywalls, but also avoiding the encumbrance of getting access via all those different publisher interfaces, I reckon.
Nicola Romanò
boosted

@villavelius @brewsterkahle yes! as far as I know, sci-hub is the only way to get PDFs by DOI via a proper API that you can use on the command line or in Python scripts (e.g. https://pypi.org/project/scidownl/ ). obviously this is really practical or even a necessity for larger-scale systematic literature research. so even if the publication is open-access or you have official access in some other way, sci-hub can just be much more practical to use.
Nicola Romanò
boosted

“I dashed out to grab some drugstore makeup to paint our faces with insignia from Cars and Star Wars. The random blocks of bright white, iridescent gold, and thick blues and reds reminded me of the Zinc sunscreen my own mother painted on my face for our Disney trips in the 1980s. She was protecting us from sunburn, I was warding off facial recognition systems.” — @cyberlyra
Nicola Romanò
boosted

Here's an analysis I have done on editorial processing times in Hindawi special issues; https://psyarxiv.com/6mbgv. I think there's v circumstantial evidence for paper mill infestation.
Nicola Romanò
boosted

Hello world! 📢
The #Bioconductor EuroBioc 2023 conference will be in Ghent, Belgium 🇧🇪 on the 20, 21, 22 September 2023. More details, including keynote speakers and calendar at https://eurobioc2023.bioconductor.org/
Oh, and abstract submissions are already open!
Nicola Romanò
boosted

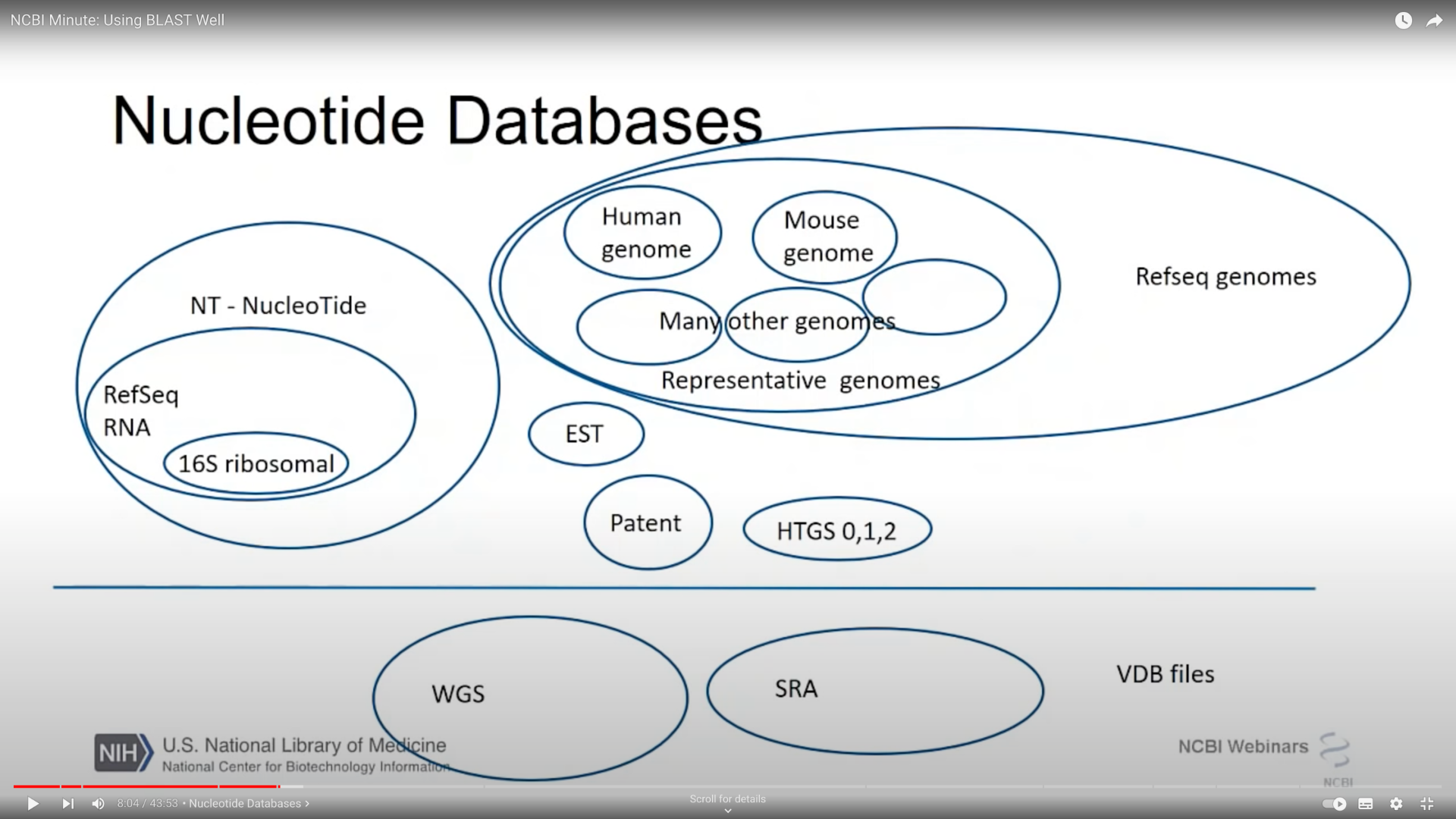
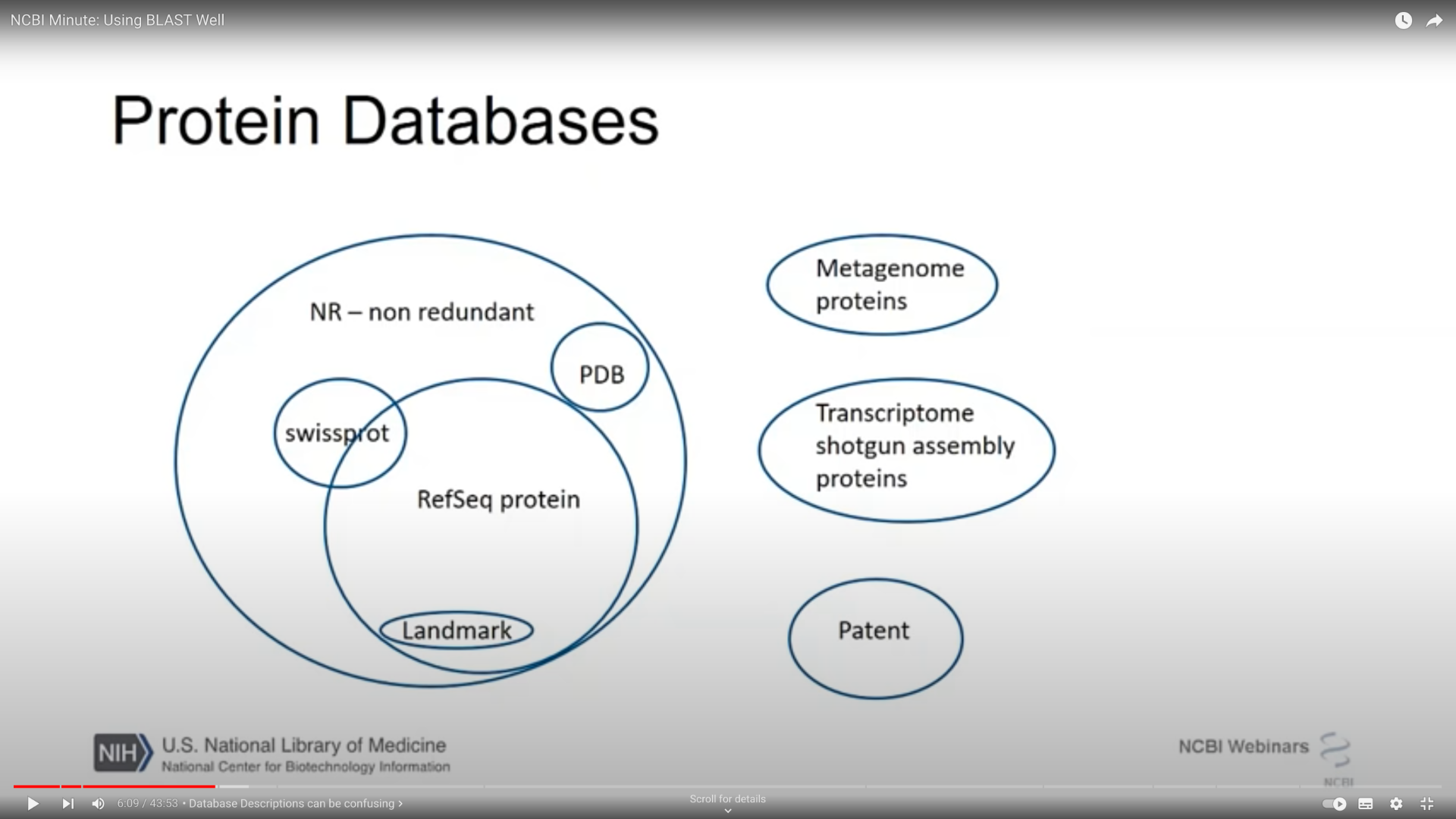
If you've ever wondered EXACTLY what is in
@NCBI
nt and nr (I certainly have!)
From https://youtu.be/2FW1dk5YQ3I?t=484 and https://youtu.be/KLBE0AuH-Sk?t=692 (cued to the right spots in the video)
Nicola Romanò
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
𝚖𝚊𝚛𝚐𝚒𝚗𝚊𝚕𝚎𝚏𝚏𝚎𝚌𝚝𝚜 0.9.0 is a BIG📦release! Simple yet powerful tools to help you interpret the results of over 70 classes of models in #RStats (GLM, GAM, discrete choice, mixed-effects, bayesian, etc.) 🧵 on some cool new stuff. https://vincentarelbundock.github.io/marginaleffects/
{kind=link}
One #vscode feature that can be annoying or extremely useful, depending on your workflow, is that when you click on a file in your project, it is open in "preview mode". The file won't stay open and the tab will be reused to open any other file you click on unless you modify it.
I just discovered that you can either:
- double click on the file to open it persistently
- change the workbench.editor.enablePreview
parameter in the settings to disable preview altogether! (there are specific settings workbench.editor.enablePreviewFromQuickOpen and workbench.editor.enablePreviewFromCodeNavigation if you want to control preview mode only in specific cases)
- Pronouns
- he/him
Senior lecturer at Edinburgh University and Zhejiang-Edinburgh Joint Institute (ZJE).
Undergraduate Programme Organiser, Biomedical Informatics at ZJE.
I teach #imageanalysis & #dataanalysis with #RStats & #python.
My research is focused on how #heterogeneous behaviour in #pituitary (and other) cells shapes their function as a population.
I'm also very interested in #reproducibility and #openscience.
Joined Oct 2022
